深度学习框架Pytorch学习笔记
由于工作原因,需要使用到深度学习pytorch框架,所以,跟随视频学习了深度学习框架的使用方法
1、安装pytorch
在windows下使用pytorch,首先找到anaconda官网,安装64位windows版本,然后使用清华的源替换掉anaconda默认源
打开anaconda prompt
conda create -n your_env_name python=x.x
命令创建环境,可以使用
conda env list
查看当前已有的环境,来判断环境是否创建成功
打开Start Locally | PyTorch,选择自己需要的pytorch版本,将Run this Command命令复制到自己控制台,然后就可以等待pytorch自己安装成功啦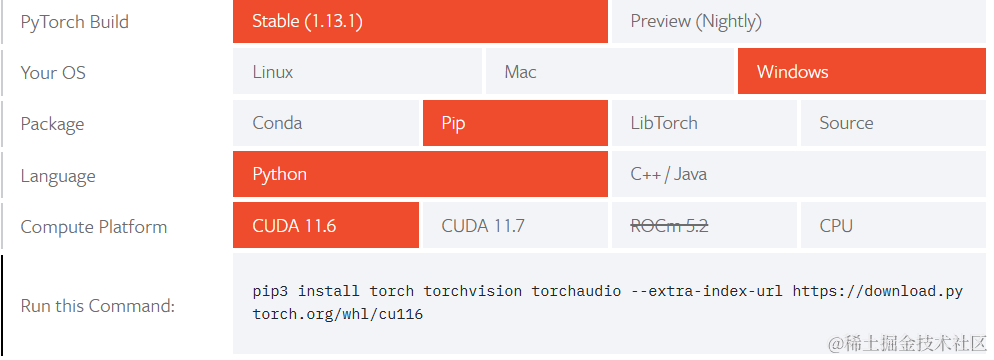
安装完成后,在控制台输入
python
import torch
print(torch.__version__)

输出版本后,就表明安装成功啦,当然,如果是GPU版本,还可以输入
print (torch.cuda.is_available())
显示TRUE就表示显卡加速也开启了,就可以开启我们的深度学习之路了。
ps:python中的两个方便的函数
dir()? ? ? 显示包中的方法
help()? ?显示方法的具体帮助信息
2、数据加载
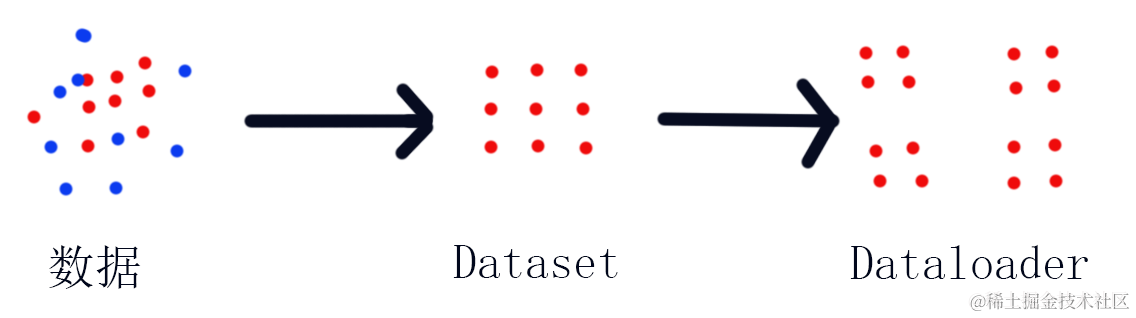
如图所示,数据在变成Dataset的过程就是将杂乱的数据刨除和整理数据的过程,并且统计了数据的大小,而Dataset到Dataloader则是将整理过的数据按照设定大小进行打包的过程,最终Dataloader为深度学习直接提供需要的数据。
使用的示例代码如下:
from torch.utils.data import Dataset
from PIL import Image
import os
class myData(Dataset):
def __init__(self, strRootDir, strLabelDir):
self.mstrRootDir = strRootDir
self.mstrLabelDir = strLabelDir
self.mstrPath = os.path.join(strRootDir, strLabelDir)
self.mstrImagePath = os.listdir(self.mstrPath)
def __getitem__(self, item):
strImageName = self.mstrImagePath[item]
strImageItemPath = os.path.join(self.mstrPath, strImageName)
zImage = Image.open(strImageItemPath)
strLabel = self.mstrLabelDir
return zImage, strLabel
def __len__(self):
return len(self.mstrImagePath)
strRootDir = "dateset/train"
strLabelAnts = "ants"
strLabelBees = "bees"
zAntsData = myData(strRootDir, strLabelAnts)
zBeesData = myData(strRootDir, strLabelBees)
zTrainData = zAntsData + zBeesData
print(len(zAntsData), len(zBeesData), len(zTrainData))
3、深度学习训练工具
由于深学习过程太过抽象,无法直观的查看模型学习的程度,所以使用Tensorbard工具来查看,在控制台输入
pip3 -install tensorbard
下载该工具,使用其中的SummaryWriter类的add_scalar和add_image方法就可以将数据进行图表展示以及图片的展示
示例程序如下:
from torch.utils.tensorboard import SummaryWriter
import numpy
from PIL import Image
wirter = SummaryWriter("logs")
PILImagePath = "dateset/train/ants/0013035.jpg"
PILImage = Image.open(PILImagePath)
ImageArray = numpy.array(PILImage)
wirter.add_image("ants", ImageArray, 1, dataformats='HWC')
for i in range(100):
wirter.add_scalar("y = 2x", 2 * i, i)
wirter.close()
在控制台输入
tensorboard --logdir=你的日志文件位置
就可以查看到如下的图表
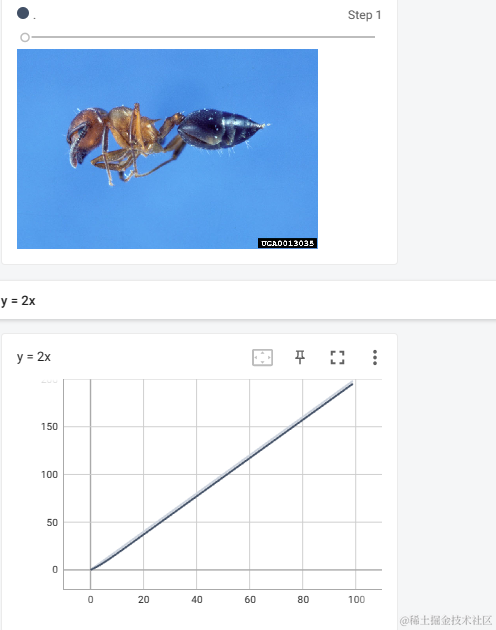
4、图形变换
图形变换主要使用torchvision包中的Transforms包内的方法,有Resize、ToTensor等方法,可以使用Compose方法将所以操作合并为一个命令,要求方法间输入与下一个方法的输出一一对应。
5、数据集
在torchvision包中的dataset包提供了一些内置的数据集可以使用,将download设置为True将在程序运行时自动下载。
6、神经网络的结构
1、模型本体,需要创建一个nn.Module的子类作为深度学习模型的本体,需要自己根据模型结构实现自己的__init__方法和forward方法
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.model = nn.Sequential(
# 卷积层1
nn.Conv2d(3, 32, 5, 1, 2, ),
# 池化层1
nn.MaxPool2d(2),
# 卷积层2
nn.Conv2d(32, 32, 5, 1, 2),
# 池化层2
nn.MaxPool2d(2),
# 卷积层3
nn.Conv2d(32, 64, 5, 1, 2),
# 池化层3
nn.MaxPool2d(2),
# 展平层
nn.Flatten(),
# 全连接层1
nn.Linear(64 * 4 * 4, 64),
# 全连接层2
nn.Linear(64, 10)
)
def forward(self, x):
"""
神经元向前传播函数
:param x: 输入的参数
:return: 输出的参数
"""
x = self.model(x)
return x
一般将这个类写入单独的py文件方便之后操作,并且一般在文件末尾提供模型的自检方法
# 神经网络模型测试
if __name__ == '__main__':
funModel = MyModel()
myInPut = torch.ones(64, 3, 32, 32)
myOutPut = funModel(myInPut)
print(myOutPut.shape)
2、卷积层
卷积层负责卷积操作,一般调用nn.conv2d方法
3、池化层
池化层的作用是在尽量保证特征的同时减少数据量,一般卷积层后就会跟随一个池化层,调用nn.MaxPool2d方法
4、非线性激活层
非线性激活主要是为了引入非线性特征,一般使用的有nn.ReLU方法和Sigmoid方法
5、正则化层
正则化层主要目的是加快训练速度,一般使用nn.BatchNorm2d方法
6、线性层
线性层也叫全连接层,主要是对数据进行线性组合,一般使用Linear方法,在线性层之前可以调用nn.Flatten方法对数据进行展平
7、可以使用nn.Sequential方法将网络各层方法合并为一个命令,需要保证输出与下一个输入的数据对应
8、损失函数和反向传播
损失函数可以产生一个loss数,用来判断模型特征与实际数据之间的差异,并且对神经网络的反向传播提供依据,一般使用nn.L1Loss方法或nn.MSELoss方法,计算出的loss值越小,越接近真实。
9、优化器
优化器内置了许多成熟的神经网络优化算法,一般使用SGD方法,需要提供一个学习速率,优化前需要将之前优化器的偏移进行清空,使用zero_grad方法,然后将网络进行反向传播填充偏移,随后调用step方法进行神经网络优化
10、学习速率调整函数
为了得到更好的模型,往往随着训练次数增大,需要调整学习的速率,lr_scheduler包提供了调整学习速率的函数方法,使用step方法就可以进行速率调整,注意,这个step需要在优化器至少在之前执行了一次step
11、GPU训练模型
可以使用GPU进行训练加速的地方有数据,损失函数和模型。具体方法有两种:
11.1、使用cuda方法将需要加速的地方放入gpu
11.2、使用to(device)方法将需要加速的地方放入gpu,如果需要写cpu和gpu平台通用的函数,可以把device设备这样写:
zDevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
7、训练模型常用套路
训练模型基本套路为:
1、设置设备
2、加载数据集
3、添加日志记录者
4、计算数据集长度
5、利用dataloader加载数据集
6、创建网络模型
7、创建损失函数
8、设置优化器
9、设置学习衰减函数
10、设置训练网络的一些参数
11、循环开始训练和测试
12、保存每一次训练的模型
13、记录者关闭
#!/usr/bin/env pytorch
# -*- coding: UTF-8 -*-
"""
@Project :llearn_pytorch
@File :model.py
@IDE :PyCharm
@Author :张世航
@Date :2023/2/24 11:30
@Description :一个深度学习演示样例
"""
import torchvision.datasets
from torch.optim import lr_scheduler, SGD
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import *
import time
# 设置设备
zDevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载数据集
zTrainData = torchvision.datasets.CIFAR10("TrainData", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
zTestData = torchvision.datasets.CIFAR10("TestData", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# 添加记录者
writer = SummaryWriter("logs")
# 计算数据集长度
iTrainDataLength = len(zTrainData)
iTestDataLength = len(zTestData)
print("the length of train data :{}".format(iTrainDataLength))
print("the length of test data:{}".format(iTestDataLength))
# 利用dataloader加载数据集
zTraindataLoader = DataLoader(zTrainData, batch_size=64)
zTestDataLoader = DataLoader(zTestData, batch_size=64)
# 创建网络模型
myModel = MyModel()
myModel = myModel.to(zDevice)
# 创建损失函数
myLossFunction = nn.CrossEntropyLoss()
myLossFunction = myLossFunction.to(zDevice)
# 优化器
dLearnRate = 1e-2
myOptimizer = SGD(myModel.parameters(), lr=dLearnRate)
# 设置学习率衰减函数
MyScheduler = lr_scheduler.StepLR(myOptimizer, 50, gamma=0.5)
# 设置训练网络的一些参数
# 训练的总次数
iTotalTrainStep = 0
# 测试的总次数
iTotalTestStep = 0
# 训练的轮数
iEpoch = 300
# 记录开始时间
fStartTime = time.time()
for i in range(iEpoch):
print("----第{}训练开始!!!----".format(i))
myModel.train()
for data in zTraindataLoader:
images, targets = data
images = images.to(zDevice)
targets = targets.to(zDevice)
outputs = myModel(images)
loss = myLossFunction(outputs, targets)
# 优化器优化模型
myOptimizer.zero_grad()
loss.backward()
myOptimizer.step()
iTotalTrainStep = iTotalTrainStep + 1
if iTotalTrainStep % 100 == 0:
fEndTime = time.time()
print("第{}次模型训练loss是{}".format(iTotalTrainStep, loss.item()))
writer.add_scalar("train_loss", loss.item(), iTotalTrainStep)
print("训练耗时{}".format(fEndTime - fStartTime))
MyScheduler.step()
print("----调整学习率为{}----".format(myOptimizer.state_dict()['param_groups'][0]['lr']))
writer.add_scalar("train_lr", myOptimizer.state_dict()['param_groups'][0]['lr'], i)
myModel.eval()
iTotalLoss = 0
iTotalAccuracy = 0
print("----第{}测试开始!!!----".format(i))
with torch.no_grad():
for data in zTestDataLoader:
images, targets = data
images = images.to(zDevice)
targets = targets.to(zDevice)
outputs = myModel(images)
loss = myLossFunction(outputs, targets)
iTotalLoss = iTotalLoss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
iTotalAccuracy = accuracy + iTotalAccuracy
print("第{}次模型测试loss是{}".format(i, iTotalLoss))
print("第{}次模型测试正确率是{}".format(i, iTotalAccuracy / iTestDataLength))
writer.add_scalar("test_loss", iTotalLoss, iTotalTestStep)
writer.add_scalar("test_accuracy", iTotalAccuracy / iTestDataLength, iTotalTestStep)
iTotalTestStep = iTotalTestStep + 1
# 保存每一次训练的模型
torch.save(myModel.state_dict(), "model/model_{}.path".format(i))
print("----模型已经保存!!!----")
writer.close()
8、模型保存和读取方法
有两种方法保存和读取训练好的模型
1、使用torch.save和torch.load保存和读取整个模型
2、使用torch.save(model.state_dict(),”xxx“)和model.load_state_dict(torch.load(“xxx”))来保存和加载模型中的数据(官方推荐)
9、使用模型的套路
1、加载模型
2、加载数据
3、获取模型输出结果
#!/usr/bin/env pytorch
# -*- coding: UTF-8 -*-
"""
@Project :llearn_pytorch
@File :testmodel.py
@IDE :PyCharm
@Author :张世航
@Date :2023/2/27 8:48
@Description :一个简易的验证训练好的模型的程序
"""
import os
import torch
from PIL import Image
from torchvision import transforms
from model import MyModel
class myImage:
def __init__(self, strRootDir):
self.mstrRootDir = strRootDir
self.mstrImagePath = os.listdir(self.mstrRootDir)
def __getitem__(self, item):
strImageName = self.mstrImagePath[item]
strImageItemPath = os.path.join(self.mstrRootDir, strImageName)
zImage = Image.open(strImageItemPath)
strLabel = strImageName
return zImage, strLabel
def __len__(self):
return len(self.mstrImagePath)
funTransform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor()
])
model = MyModel()
model.load_state_dict(torch.load("model/model_37.path"))
model.eval()
strTestDir = "testimage"
zData = myImage(strTestDir)
image_type = ("airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck", "nolen")
with torch.no_grad():
for data in zData:
image, label = data
image = image.convert('RGB')
image = funTransform(image)
image = torch.reshape(image, (1, 3, 32, 32))
output = model(image)
iResult = output.argmax(1)
print("图片类型|模型识别出类型:{}|{}".format(label, image_type[iResult]))
完整的代码地址?深度学习练习: 在学习深度学习时候的一些代码 编译环境为python10+pytorch1.13.1+ancoda (gitee.com)
希望可以对大家学习有一定的帮助,互勉。
教会你怎么使用pytorch这套工具,刘老师的视频pytorch版本比较老,侧重点不在于教会使用pytorch这套工具,而在于给学习者打开深度学习这扇门,所以一些原理也简单的讲解了一些,并且参杂着一些思维方式。
1、数据集尽可能接近真实
2、梯度下降算法本质:下一步所在的点 = 当前点位置-学习率*当前点所在位置的导数
3、鞍点:梯度为0的点,或者在多维问题中,这个点在一个切面为极大值点,另一个切面为极小值点,就会导致梯度消失现象。
4、梯度消失:梯度在运算过程中趋近于0,导致权值无法随着迭代进行更新
5、随机梯度下降算法:使用随机的一个loss来代替平均loss计算梯度。好处是引入随机噪点可能解决了梯度消失问题,坏处是由于计算过程中,后一步的loss计算依赖前一步的计算,导致无法使用cpu或gpu的并行计算能力,时间复杂度增加
6、batch:批量 批量随机梯度下降算法,解决随机梯度下降算法时间复杂度高的折中方法,在一批中使用梯度下降算法,在批与批之间使用随机梯度下降算法。
7、由于线性方程无论多少层也可以化简为一层的形式,所以每层间需要加入一个非线性函数进行激活,引入随机变量
8、反向传播的过程就是通过loss来计算前一层梯度的过程
9、sigmoid(饱和函数):有极限,单调增,趋向正负无穷导数为0的函数
10、常用网络:GoogleNet、ResidualNet、DenseNet
11、LSTM 时间复杂度高,但是效果比RNN好
12、RNN算法需要一定基础才能听懂,12、13课前尽量自己去了解下RNN算法的原理
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!