【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax类图
【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax概述?
【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax快速入门?
?【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax类图
【大数据进阶第三阶段之Datax学习笔记】使用阿里云开源离线同步工具Datax实现数据同步?
3、 DataX类图
整个流程大致如下
?
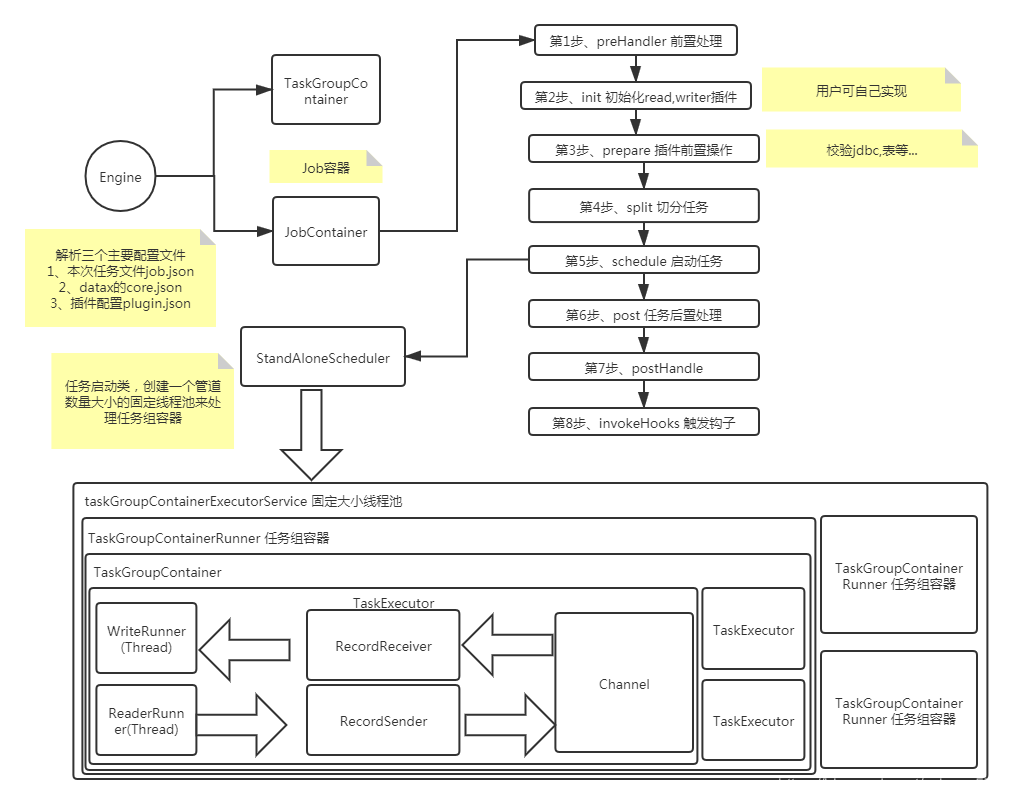
启动步骤解析:
1、解析配置,包括job.json、core.json、plugin.json三个配置
2、设置jobId到configuration当中
3、启动Engine,通过Engine.start()进入启动程序
4、设置RUNTIME_MODEconfiguration当中
5、通过JobContainer的start()方法启动
6、依次执行job的preHandler()、init()、prepare()、split()、schedule()、- post()、postHandle()等方法。
7、init()方法涉及到根据configuration来初始化reader和writer插件,这里涉及到jar包热加载以及调用插件init()操作方法,同时设置reader和writer的configuration信息
8、prepare()方法涉及到初始化reader和writer插件的初始化,通过调用插件的prepare()方法实现,每个插件都有自己的jarLoader,通过集成URLClassloader实现而来
9、split()方法通过adjustChannelNumber()方法调整channel个数,同时执行reader和writer最细粒度的切分,需要注意的是,writer的切分结果要参照reader的切分结果,达到切分后数目相等,才能满足1:1的通道模型
10、channel的计数主要是根据byte和record的限速来实现的,在split()的函数中第一步就是计算channel的大小
11、split()方法reader插件会根据channel的值进行拆分,但是有些reader插件可能不会参考channel的值,writer插件会完全根据reader的插件1:1进行返回
12、split()方法内部的mergeReaderAndWriterTaskConfigs()负责合并reader、writer、以及transformer三者关系,生成task的配置,并且重写job.content的配置
13、schedule()方法根据split()拆分生成的task配置分配生成taskGroup对象,根据task的数量和单个taskGroup支持的task数量进行配置,两者相除就可以得出taskGroup的数量
14、schdule()内部通过AbstractScheduler的schedule()执行,继续执行startAllTaskGroup()方法创建所有的TaskGroupContainer组织相关的task,TaskGroupContainerRunner负责运行TaskGroupContainer执行分配的task。scheduler的具体实现类为ProcessInnerScheduler。
15、taskGroupContainerExecutorService启动固定的线程池用以执行TaskGroupContainerRunner对象,TaskGroupContainerRunner的run()方法调用taskGroupContainer.start()方法,针对每个channel创建一个TaskExecutor,通过taskExecutor.doStart()启动任务
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!