BLIP-2 官方库学习
文章目录
Overview
《BLIP-2:Bootstrapping Language Image Pre-training with Frozen Image Encoders and Large Language Models》 中提出了BLIP-2模型。BLIP-2通过在冻结的预训练图像编码器和大型语言模型(LLM)之间训练一个轻量级的12层Transformer编码器,利用它们,在各种视觉语言任务中实现最先进的性能。最值得注意的是,BLIP-2在可训练参数减少54倍的零样本VQAv2上比Flamingo(800亿参数模型)提高了8.7%。
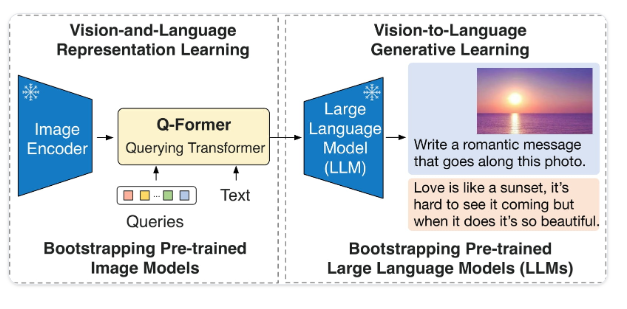
论文摘要如下:
由于大规模模型的端到端训练,视觉和语言预训练的成本变得越来越高。本文提出了 BLIP-2,这是一种通用且高效的预训练策略,可从现成的冻结预训练图像编码器和冻结大型语言模型 引导视觉语言预训练【 bootstraps vision-language pre-training】。 BLIP-2 通过轻量级查询转换器弥补了模态差距,该转换器分两个阶段进行预训练。第一阶段从冻结图像编码器引导视觉语言表示学习【 The first stage bootstraps vision-language representation learning from a frozen image encoder. 】。第二阶段从冻结的语言模型引导视觉到语言的生成学习。尽管可训练参数比现有方法少得多,但 BLIP-2 在各种视觉语言任务上实现了最先进的性能。例如,我们的模型在零样本 VQAv2 上的性能比 Flamingo80B 高出 8.7%,可训练参数减少了 54 倍。我们还展示了该模型的新兴功能,即可以遵循自然语言指令的零样本图像到文本生成功能。
Blip2Config
( vision_config = None, qformer_config = None, text_config = None, num_query_tokens = 32, **kwargs )
-
vision_config(dict,可选)–用于初始化Blip2VisionConfig的配置选项字典。
-
qformer_config (dict,可选)-用于初始化Blip2QFormerConfig的配置选项字典。
-
num_query_tokens (int,可选,默认为32)-通过transformer传递的查询令牌数。
-
kwargs (可选)-关键字参数词典。
Blip2Config是用于存储Blip2ForConditional Generation的配置的配置类。它用于根据指定的参数实例化BLIP-2模型,定义视觉模型、Q-Former模型和语言模型配置。
Blip2Config {
"initializer_factor": 1.0,
"initializer_range": 0.02,
"model_type": "blip-2",
"num_query_tokens": 32,
"qformer_config": {
"model_type": "blip_2_qformer"
},
"text_config": {
"model_type": "opt"
},
"transformers_version": "4.35.2",
"use_decoder_only_language_model": true,
"vision_config": {
"model_type": "blip_2_vision_model"
}
}
Blip2VisionConfig
( hidden_size = 1408, intermediate_size = 6144, num_hidden_layers = 39, num_attention_heads = 16, image_size = 224, patch_size = 14, hidden_act = 'gelu', layer_norm_eps = 1e-06, attention_dropout = 0.0, initializer_range = 1e-10, qkv_bias = True, **kwargs )
-
hidden_size(int,可选,默认为1408)——编码器层和池器层的维度。
-
intermediate_size(int,可选,默认为6144)——Transformer编码器中“中间”(即前馈)层的维度。
-
num_hidden_layers(int,可选,默认为39)–Transformer编码器中的隐藏层数。
这是用于存储Blip2 VisionModel配置的配置类。
from transformers import Blip2VisionConfig, Blip2VisionModel
# Initializing a Blip2VisionConfig with Salesforce/blip2-opt-2.7b style configuration
configuration = Blip2VisionConfig()
# Initializing a Blip2VisionModel (with random weights) from the Salesforce/blip2-opt-2.7b style configuration
model = Blip2VisionModel(configuration)
# Accessing the model configuration
configuration = model.config
输出:
Blip2VisionConfig {
"attention_dropout": 0.0,
"hidden_act": "gelu",
"hidden_size": 1408,
"image_size": 224,
"initializer_range": 1e-10,
"intermediate_size": 6144,
"layer_norm_eps": 1e-06,
"model_type": "blip_2_vision_model",
"num_attention_heads": 16,
"num_hidden_layers": 39,
"patch_size": 14,
"qkv_bias": true,
"transformers_version": "4.35.2"
}
Blip2QFormerConfig
( vocab_size = 30522, hidden_size = 768, num_hidden_layers = 12, num_attention_heads = 12, intermediate_size = 3072, hidden_act = 'gelu', hidden_dropout_prob = 0.1, attention_probs_dropout_prob = 0.1, max_position_embeddings = 512, initializer_range = 0.02, layer_norm_eps = 1e-12, pad_token_id = 0, position_embedding_type = 'absolute', cross_attention_frequency = 2, encoder_hidden_size = 1408, **kwargs )
- vocab_size(int,可选,默认为30522)–Q-Former模型的词汇大小 Vocabulary size。定义调用模型时传递的inputs_ids可以表示的不同令牌的数量。
- num_hidden_layers(int,可选,默认为12)–Transformer编码器中的隐藏层数。
from transformers import Blip2QFormerConfig, Blip2QFormerModel
# Initializing a BLIP-2 Salesforce/blip2-opt-2.7b style configuration
configuration = Blip2QFormerConfig()
# Initializing a model (with random weights) from the Salesforce/blip2-opt-2.7b style configuration
model = Blip2QFormerModel(configuration)
# Accessing the model configuration
configuration = model.config
输出:
Blip2QFormerConfig {
"attention_probs_dropout_prob": 0.1,
"cross_attention_frequency": 2,
"encoder_hidden_size": 1408,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "blip_2_qformer",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.35.2",
"vocab_size": 30522
}
Blip2Model
outputs = model(inputs)
from PIL import Image
import requests
from transformers import Blip2Processor, Blip2Model
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2Model.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16)
model.to(device)
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
prompt = "Question: how many cats are there? Answer:"
inputs = processor(images=image, text=prompt, return_tensors="pt").to(device, torch.float16)
outputs = model(**inputs)
get_text_features
text_features = model.get_text_features(inputs)
import torch
from transformers import AutoTokenizer, Blip2Model
model = Blip2Model.from_pretrained("Salesforce/blip2-opt-2.7b")
tokenizer = AutoTokenizer.from_pretrained("Salesforce/blip2-opt-2.7b")
inputs = tokenizer(["a photo of a cat"], padding=True, return_tensors="pt")
text_features = model.get_text_features(**inputs)
get_image_features
image_outputs = model.get_image_features(inputs)
import torch
from PIL import Image
import requests
from transformers import AutoProcessor, Blip2Model
model = Blip2Model.from_pretrained("Salesforce/blip2-opt-2.7b")
processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
image_outputs = model.get_image_features(**inputs)
get_qformer_feature
qformer_outputs = model.get_qformer_features(inputs)
import torch
from PIL import Image
import requests
from transformers import Blip2Processor, Blip2Model
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2Model.from_pretrained("Salesforce/blip2-opt-2.7b")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
qformer_outputs = model.get_qformer_features(**inputs)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!