自然语言处理阅读第一弹
2023-12-15 21:48:36
Transformer架构
Embeddings from Language Model (ELMO)
- 一种基于上下文的预训练模型,用于生成具有语境的词向量。
- 原理讲解
- ELMO中的几个问题
Bidirectional Encoder Representations from Transformers (BERT)
- BERT就是原生transformer中的Encoder
- 两个学习任务:MLM和NSP
-
Masked Language Model:将输入句子中的某些token随机替换为[MASK],然后基于上下文预测这些被替换的token。学习局部语义和上下文依赖关系。这有助于BERT理解每个词的表达。
-
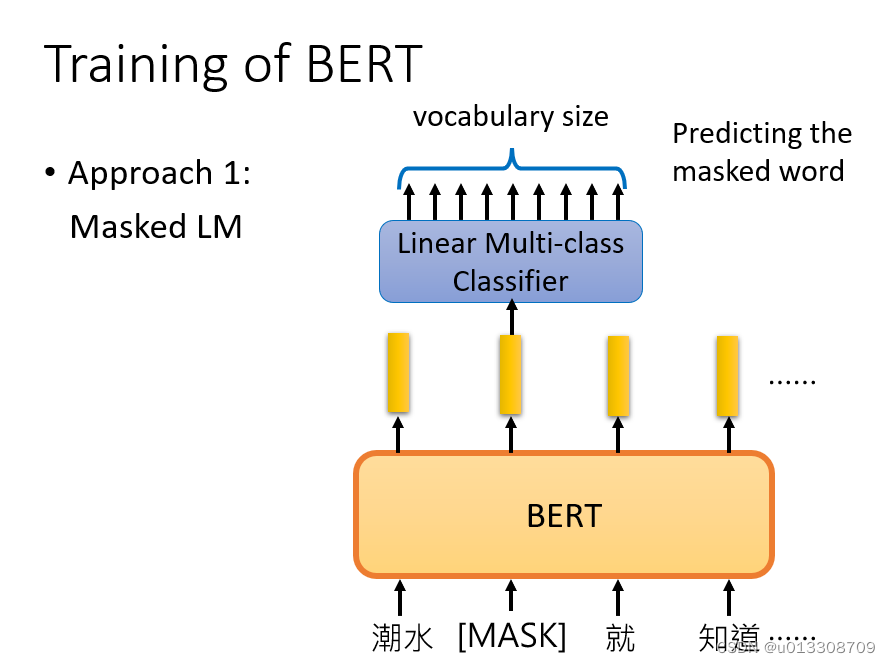
-
Next Sentence Prediction:给定一对句子A和B,判断B是否是A的下一句。这可以学习句子之间的关系,捕获上下文信息,有助于BERT在文档层面上理解语言。
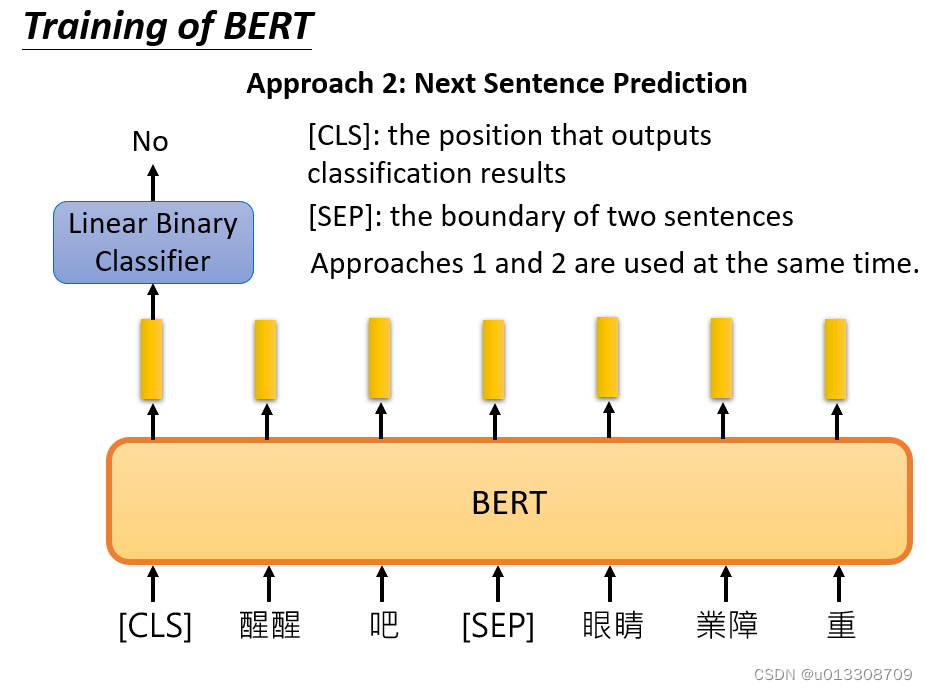
-
- 李宏毅BERT
- BERT
Enhanced Representation through Knowledge Integration (ERNIE)
- ERNIE提出了Knowledge Masking的策略,ERNIE将Knowledge分成了三个类别:token级别(Basic-Level)、短语级别(Phrase-Level) 和 实体级别(Entity-Level)。通过对这三个级别的对象进行Masking,提高模型对字词、短语的知识理解。
- 预训练模型ERINE
- ERINE的改进
Generative Pre-Training (GPT)
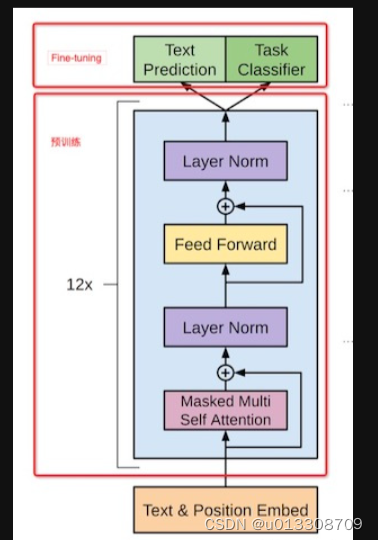
文章来源:https://blog.csdn.net/u013308709/article/details/134959117
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!