零停机升级Postgres
零停机升级Postgres
我们是Knock 团队。我们提供了一组简单的 API,开发人员可以使用它们将通知接入到他们的产品中,而无需自己构建和维护通知系统。
最近我们使用逻辑复制、一系列工具脚本以及 Elixir & Erlang 的 BEAM 虚拟机中的工具,将 Postgres 11.9 升级到 15.3,实现了零停机。
这篇文章将详细介绍我们是如何做到这一点的,以及如果您尝试这样做时可能需要考虑的事项。
它更像是一本手册,包含了我们一路上学到的东西,而我们希望事先就知道这些东西。
Knock 依靠 Postgres 来支持我们的通知工作流引擎。从存储工作流程配置和消息模板,到摄取数百万条日志和大量排队的后台作业,Postgres 是我们系统所做的一切工作的核心。我们在 AWS RDS Aurora 上运行的 Postgres 数据库始终可靠、高性能且可扩展。 这作为Knock 服务的基础让我们能够有信心支持每一位加入我们平台的客户。
与可以在后台不断升级而无需通知的 SaaS 软件不同,升级像 Postgres 这样的关系数据库通常至少需要重新启动数据库。在大版本升级的情况下,数据库通常需要完全关闭几分钟,以升级数据在磁盘上的存储和索引方式。
数据越多,升级所需的时间就越长。
以 Knock 为例,自公司成立以来,我们一直在运行 Postgres 11.9。尽管 Postgres 11.9 在整个过程中为我们提供了可靠的服务,但它将于 2024 年 2 月 29 日由 Amazon RDS 服务退役。如果不采取行动(即与 RDS 安排长期支持合同),使用 Postgres 11.9 的团队将无法继续使用 Postgres 11.9。届时 AWS RDS 将被强制升级,可能会导致强制停机。
对于像 Knock 这样的服务来说,无论是计划的还是其他的停机时间都是不可接受的。我们的客户依赖我们 24/7 在线。尽管没有任何服务可以保证完美的正常运行时间,但负责任的开发团队会努力在服务问题发生之前主动解决它们。
我们于今年 6 月将此升级添加到我们的路线图中,但有以下限制:
- 尽可能升级主版本,可跳至最新的可用版本(当时为 Aurora 的 Postgres 15.3)。
- 任何超过 60 秒的停机时间都是完全不可接受的,理想情况下我们应该实现零系统停机时间。
- 升级必须在亚马逊二月份的截止日期之前进行。
- 最大限度地减少对客户的影响(例如零 API 错误响应)。
- 实施该流程,以便下次我们需要升级数据库时,它是一个完善的操作手册。
我们的每个 Postgres 数据库都需要运行这个过程,从 11.9 到 15.3 将包括四个主要版本升级。如果对每个主要版本进行就地升级都会引发停机,那么连续进行四个升级是不可能的。
为了满足我们的要求,我们必须发挥创造力。
升级Postgres 的准备工作
最重要的是,寻求以任何方式升级 Postgres 的团队应该专注于尽可能降低升级过程的风险:
-
列出迁移过程中涉及的风险。例如:
- 停机时间长得令人无法接受
- 数据丢失
- 应用程序工作负载的数据库性能变化
- 真空(vacuum)频率或行为的变化
- 是否有任何复制槽(replication slots)需要迁移(这可能很棘手 - 见下文)
-
找出哪些风险对项目最关键,哪些风险可能最容易提前探索/排除/修复。
对列表进行排序,使影响最大但最容易解决的风险位于顶部。
-
在开发解决方案时,请考虑您的风险清单:
- 有没有完全排除风险的解决方案?
- 哪些解决方案可以随着时间的推移分散风险? (因此我们可以逐步解决迁移的每个步骤,而无需立即承担太多风险。)
-
当您完成该项目时,请始终重新审视您的风险列表,并在学习新事物时保持最新 - 包括发现新风险!
逐步并持续地降低此类项目的风险,直到您有信心能够实现项目目标。
为了规划升级,我们从 Postgres’ release notes开始,了解数据库版本之间将发生哪些变化。这帮助我们识别更多风险(例如 Postgres 真空(vacuum)工作方式的变化、执行某些升级时重新构建数据库索引的要求),同时排除其他风险。
当我们完成规划过程时,我们维护了这份风险列表,随着收集更多信息,添加新的问题并更新旧的问题。在升级过程中,我们系统地解决了每个问题,直到我们确信可以在不影响可靠性的情况下实现项目目标。
关于监控和指标
拥有全面的工具(感谢 DataDog!)来监控系统和数据库的运行状况,使得监控迁移的每个步骤成为可能。
需要关注的几个关键指标:
-
最大的 TXN ID 以避免事务回绕 - 如果该值太高,数据库可能会关闭并进入紧急维护模式
-
数据库CPU利用率
-
writer 实例上的等待会话
-
查询延迟
-
您的应用程序的 API 响应延迟
在 Knock,我们监控所有这些指标以及应用程序特有的一些指标,例如将 API 请求转换为通知所需的时间。
如果没有实时的指标,你就会盲目前进。
升级 Postgres 的可选项
我们研究过程的一部分包括寻找数据库迁移的先前示例以及 Postgres 文档如何建议执行更新。以下是一些策略:
就地升级( in-place upgrade)(零停机升级不可能实现)
Postgres 最基本的升级选项是就地升级。在 AWS RDS 上,此升级是从 AWS 控制台执行的。执行就地升级时,AWS 将关闭数据库,运行升级脚本,然后使系统重新上线。执行此操作通常需要一些准备工作,包括删除 Postgres 复制槽,例如用于与数据仓库或其他系统同步的复制槽。
这个就地升级过程可能需要几分钟到几个小时或更长时间——这完全取决于 Postgres 版本之间需要更新的数据量。
通常,系统上线时仍不处于完全可用状态,管理员必须运行维护任务,例如 Postgres 的 VACUUM 命令或 REINDEX 来更新索引以支持新版本版本的格式。
因为就地升级需要的停机时间远远超出我们的承受范围,所以这对我们来说是不可能的。
与就地升级类似的方法是使用 pg_dump 和 pg_restore 在数据库关闭后传输数据库的内容。由于需要停机,这种转储和恢复方法也不适合我们,主要是因为您需要断开所有应用程序与旧数据库的连接以获得可靠的数据库备份。即使这样,对于大型数据库,转储和恢复数据库也可能需要很长时间。
基于复制的升级
这种方法依赖于 Postgres 出色的复制原语: PUBLICATION 和 SUBSCRIPTION 。
它的工作原理是这样的:
- 在您的目标 Postgres 版本上启动一个新数据库
- Copy over settings, extensions, table configurations, users, etc.
复制设置、扩展、表配置、用户等。 - Set up a publication on the old database and a subscription to that publication on the new database
在旧数据库上设置publication,并在新数据库上设置对该发布的subscription - 将您的table 添加到publication 中(这里有很多细微差别 - 更多内容见下文)
- 完全复制后,运行测试以满足任何剩余风险
- 当您对新数据库的配置充满信心,请将您的应用程序指向新数据库
- 删除旧数据库
最后,我们在 Knock 中选择了这种方式,原因如下:
- 它为我们提供了逐步迁移的步骤,而不是一次重大升级
- 我们可以使用真实工作负载和真实数据测试新数据库,以避免任何回归
- 它使我们能够最大程度地控制何时以及如何执行升级:一旦新数据库完全准备好,切换到新数据库只需几秒钟
尽管这听起来很简单,但在此解决方案中需要考虑几点,具体取决于您的应用程序和环境。
配置源数据库和目标数据库
发布(Publications)和订阅(subscriptions)取决于一些用于设置复制槽(replication slots)的配置参数(数据库如何跟踪需要从主数据库复制到从属数据库的内容)。 The Postgres docs有很多关于这些参数的详细信息。这些参数需要针对您的特定应用进行调整。对于简单的应用程序,唯一需要的更改是将 wal_level 设置为 logical 。
如果您已使用复制槽(例如,管理只读副本、数据库故障转移或保持数据仓库同步),请考虑根据文档中的指导设置 max_replication_slots 和其他参数。
配置基本复制
-
启动一个新的目标版本的 Postgres 服务器(在我们的示例中为 v15.3)。
-
配置所需的数据库、模式、表、分区、用户和密码以及其他所有内容。
目标数据库的表必须与源数据库具有相同的表结构,但这些表必须为空。
要获取数据库架构的快照,请在旧数据库上运行
pg_dumpall(传递--schema-only和--no-role-passwords选项以保留其主要部分),然后进行调整新数据库的命令。然后,您可以比较生成的 SQL 文件,以识别并修复新旧数据库之间的差异。定期比较两个数据库以检测任何偏差可能是值得的,特别是如果源数据库中发生架构迁移。考虑对两个数据库运行迁移以保持它们同步。
-
在旧数据库的主实例上,运行
CREATE PUBLICATION pg_upgrade_pub;。
尽管您可以附加FOR ALL TABLES并为每个表设置发布,但我们发现对于大型数据库,这可能会导致性能问题。
相反,我们发现通过 ALTER PUBLICATION pg_upgrade_pub ADD TABLE table_name 一次增量地将一个表添加到发布中效果更好。下面详细介绍这一点。
- 在新数据库的主实例上,配置指向该发布的新订阅:
-- Note the _sub suffix, you can call this whatever you like
CREATE SUBSCRIPTION pg_upgrade_sub
-- The connection string can be any standard Postgres connection string.
-- More details here:
-- https://www.postgresql.org/docs/current/libpq-connect.html#LIBPQ-CONNSTRING
CONNECTION 'host=old-db.cloud.com dbname=your_app user=root password=<password>'
-- The publication name MUST match the publication created on the old database
PUBLICATION pg_upgrade_pub with (
-- This subscription will not start syncing until you enable it,
-- which can be helpful when getting started
enabled = false,
-- Replication slots track the subscription's progress.
-- By default, you want Postgres to manage this.
-- If you don't create a slot here, you will need to supply one yourself.
create_slot = true,
-- Generally you want Postgres to copy the contents of each table,
-- however for very large tables you may not want this option.
-- More details below.
copy_data = true,
-- This will halt the subscription if something unexpected happens.
-- This is usually because of a unique constraint violation, or
-- a mismatched schema (e.g. a missing or renamed column).
-- We found it helpful to halt the subscription on error so we could
-- fix the problem and then resume replication.
-- Errors are logged to the database's logs.
disable_on_error = true
);
此时,您现在拥有从旧数据库到新数据库的复制管道。
启用订阅:
ALTER SUBSCRIPTION pg_upgrade_sub ENABLE;
-- To check the status of the subscription...
-- Watch out for subenabled - if it turns false,
-- replication is stopped and potentially backing up on the primary!
SELECT * FROM pg_subscription;
-- More details on monitoring subscriptions using that table here:
-- https://www.postgresql.org/docs/16/catalog-pg-subscription.html
选择要复制的表
下一步是构建想要复制的表的列表。您将需要一次添加一个表,观察每个表,直到所有表都完全复制。在这篇文章的后面,我们将向您展示如何监视所有表的复制。
一般来说,表会根据磁盘大小和数据库中存储的元组数量分为三类。
- 小到足以在几分钟内同步:只需将它们添加到发布并刷新订阅即可复制它们
- 大型仅附加表:可以通过首先仅复制未来的更改,然后从备份或快照单独回填旧数据来同步这些表
- 大型且频繁更新的表:这些是最难同步的,需要额外小心
对于我们来说,“小”是指使用少于 50 GB 存储空间和 1000 万个元组的任何表。
任何超过这些阈值的东西我们都认为是“大”的。
什么是元组?
对 Postgres 表的每次插入或更新都存储为“元组”。如果一个表有 3 次插入,然后有 2 次更新,则该表将有 5 个元组。元组由 Postgres 的并发机制(mvcc)使用(更多内容请参阅文档)。 Postgres 的 VACUUM 过程会清理不再需要的旧元组。
当我们复制表时,我们会复制构成表内容的所有元组 - 插入的和更新的,而不仅仅是有效的数据行。具有少量数据行但有许多尚未清理的元组的表将比具有较少元组的类似表花费更长的时间来复制。
以下查询可以帮助确定数据库表在磁盘空间和元组计数方面的大小:
SELECT
relname AS tablename,
n_live_tup + n_dead_tup + n_mod_since_analyze as total_tuple_count,
pg_size_pretty(pg_total_relation_size(quote_ident(relname))) AS simple_size,
pg_relation_size(quote_ident(relname)) as size_in_bytes
FROM pg_stat_user_tables;
准备源数据库进行复制的一种方法是 VACUUM 表,这应该有助于源数据库减少需要复制到目标数据库的元组数量。这有助于减少复制表所需的时间。
在使用 VACUUM 之前,请参阅 Postgres docs.。
为什么table的大小很重要?
同步表所需的时间与其在磁盘上的大小及其包含的元组数量直接相关。表越大,复制所需的时间就越长。这是因为 Postgres 需要将整个表复制到新数据库,然后应用初始复制后发生的任何更改。
同步时间过长的问题是,它可能会阻止您的主 Postgres 实例执行 VACUUM 操作,这可能会导致性能随着时间的推移而下降。如果不加以控制,它甚至可能导致事务回绕和数据库强制关闭。
出于这些原因,我们一次添加一个表到复制中,根据每个表的大小和写入模式使用不同的策略,并密切监视系统的性能,以确保我们不会降低服务质量。
如果迁移表出现问题,您可以随时从复制中删除表,然后稍后重新添加它(尽管您需要截断目标表并从头开始)。
如何复制“小”表
要迁移小表,只需将其添加到发布中,然后刷新订阅:
-- On the old database
ALTER PUBLICATION pg_upgrade_pub ADD TABLE my_table_name;
-- ON the new database
ALTER SUBSCRIPTION pg_upgrade_sub REFRESH PUBLICATION;
Postgres 将处理表的复制、同步以及对表应用任何进一步的操作。对于非常小的表,同步可以在不到一秒的时间内完成。
大型、仅附加表
太大但通常仅追加且没有更新的表(或者,如果更新始终在最近的行上,例如过去一周内),那么您可以设置单独的 PUBLICATION 和 SUBSCRIPTION 按照与上述相同的步骤操作,但将订阅的 copy_data 选项设置为 false。在新发布和新订阅的名称后添加 _nocopy 以便区分。
当您准备好迁移这些大型仅追加表时,可以将它们添加到此 nocopy 发布中,并使用 copy_data = false 选项刷新目标上的订阅:
-- On the old database
ALTER PUBLICATION pg_upgrade_pub_nocopy ADD TABLE my_append_only_table_name;
-- On the new database
ALTER SUBSCRIPTION pg_upgrade_sub REFRESH PUBLICATION WITH ( copy_data = false );
我们发现这种方法对于为客户存储各种类型日志的分区表非常有效。我们不需要迁移分区表的根,我们只迁移底层表,这似乎工作得很好。
订阅运行后,您应该可以看到目标数据库表上出现日志:
SELECT COUNT(*) FROM my_append_only_table_name; -- Returns more than zero
从这里,您可以使用您喜欢的任何方式(例如 pg_dump )恢复比数据库中现在可见的记录更旧的任何记录。
以下是我们在 AWS RDS Aurora 上的做法:
-
在 AWS 控制台中生成生产数据库的快照
-
将该快照恢复到新的数据库实例(快照数据库)
-
通过添加后缀(例如
_snapshot)来重命名快照数据库上要复制的表。这可以防止我们有两个复制管道输入目标数据库上的同一个表。 -
在目标数据库上创建与快照数据库具有相同架构的相同表。使用与上面相同的后缀。
-
在快照数据库上创建发布并在目标数据库上创建订阅,以将这些快照表从快照数据库复制到目标数据库
-
启用订阅并监控其进度
-
订阅完成后,您可以使用
INSERT...ON CONFLICT将表合并在一起:
INSERT INTO my_append_only_table_name
SELECT * FROM my_append_only_table_name_snapshot
ON CONFLICT (id) DO NOTHING;
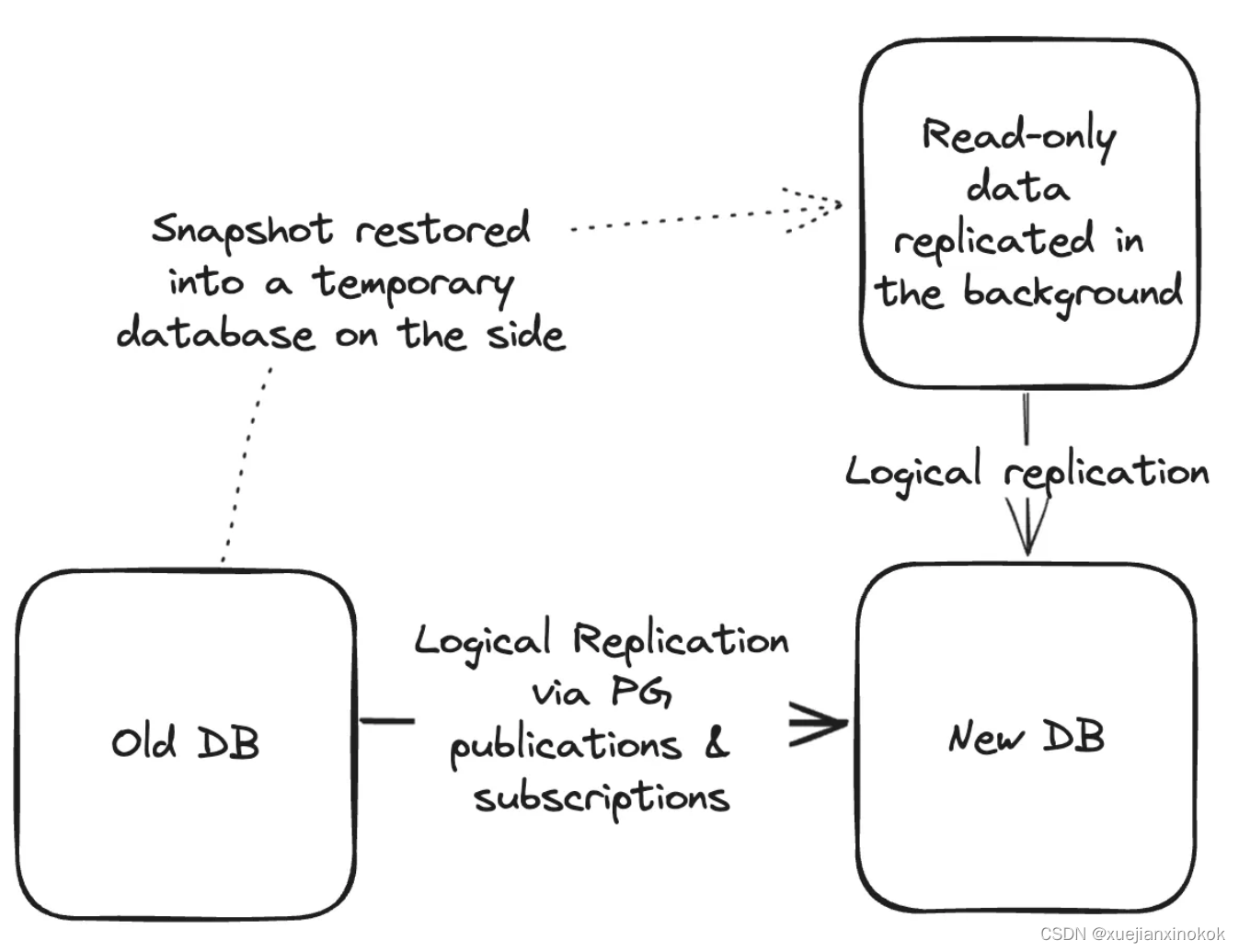
对于非常大的表,这仍然可能需要几天的时间,但因为它全部在后台,所以不会影响您的生产环境。
表完全合并后,对它们进行比较以确保行数一致(稍后会详细介绍)。一旦您确信这些表相同,请删除目标数据库上的快照表,删除对快照数据库的订阅,然后终止快照数据库实例。
大型表且大部分行都有更新
这些是比较困难的表。由于它们包含大量数据,因此可能需要很长时间才能复制,如果阻止 AUTOVUACUUM 运行,可能会影响源数据库上的系统性能。因为它们有如此多的更新,所以我们不能将其视为仅附加表。
需要考虑的几点:
- 您可以做一些整理工作来缩小table的大小吗?
- 你最近用vacuum 清理过table吗?
- 你能把table分成更小的部分吗?
- 在可靠的时间范围(例如 1 周)之后,行是否停止接收更新 - 这可以用于将表视为仅追加表,然后在该时间范围过去后,您可以从快照回填旧行。
如果您的源数据库不在 PG 15 或更高版本上,您的选择将受到限制。请按照“小表”部分中的步骤进行操作。依靠您现有的监控(您确实有监控,对吧?)来确保复制不会降低您的服务。如果需要,您可以通过从发布中删除表并刷新订阅来回滚(见下文)。
如果表仍然太大,请尝试在低流量时间启动复制,以减少负载和写入活动。这有望最大限度地减少对您系统的影响。
来源于PG15或高于PG15中的大型table
如果您的源数据库位于 PG 15 或更高版本上,您也许能够跨多个发布分割复制(类似于分区或分片)。然后,您可以以更小的块的形式迁移表,但代价是使用更多的复制槽。 The Postgres docs提供了有关设置这些参数的更多信息。
因为我们从 11.9 迁移到 15.3,所以我们没有可用的选项。因此,我们尚未测试这种方法。即便如此,当我们考虑我们的选择时,我们注意到这种方法可能是可行的。如果您尝试一下,请告诉我们,我们很想听听效果如何!
目标是拥有足够的publication 来将最大的表分割成可管理的部分(对于我们来说,这大约存储了 100 GB 的非索引数据)。在此示例中,我们假设我们分为三个分区。技巧是添加一个 WHERE 子句来分割每个订阅处理的行:
-- On the source database
-- For three partitions...
CREATE PUBLICATION pg_upgrade_pub_0;
CREATE PUBLICATION pg_upgrade_pub_1;
CREATE PUBLICATION pg_upgrade_pub_2;
ALTER PUBLICATION pg_upgrade_pub_0 ADD TABLE big_table
-- id must be the primary key.
-- Use hashint4 for int IDs, hashint8 for bigint IDs
-- Use hashtext(id::text) for UUID or other key types
-- If you have a composite PK, concatenate the columns together before hashing as text
-- Postgres' hash functions return positive & negative numbers - we abs() the result to make it positive
-- % 3 is used to pick which of three partitions. Adjust the integer for the number of partitions you will create.
-- = 0 assigns rows to the first partition (zero-indexed, so we will finish with partitions 0, 1, and 2)
WHERE abs(hashint4(id)) % 3 = 0;
-- Repeat the above ALTER statement for each publication, adjust the where clause accordingly.
在目标数据库上,为每个分区创建订阅。
您一次只想迁移每个表的一个分片。通常,您将遵循与添加“小”表相同的说明,但在为每个发布设置表时添加额外的 WHERE 子句。
通过这种方式,您可以将大表分割成更小、更实用的部分。
如果存在太多复制槽问题,请仅考虑使用此方法:您仍然可以使用此方法添加“小”表,只需将表添加到 _0 发布中,而无需 WHERE 子句。这有助于减少迁移时所需的复制槽数量。
检查表的复制状态
将表添加到订阅时,它会经历五种不同的状态(在目标数据库的系统表 pg_subscription_rel的 srsubstate 列中可见):
- 初始化表的订阅(状态代码
i) - 通过一次高效操作复制表的内容(状态代码
d)
此步骤需要保留旧的 Postgres 事务 ID,这会阻止 Vacuum 有效运行,并可能导致系统性能问题,并且(如果运行时间足够长)甚至 Postgres 事务 ID 回绕可能会导致系统停止运行。
此步骤一次只需要复制一个表。
- 复制完成,等待最终同步(状态代码
f) - 完成初始同步(状态代码
s) - 在正常复制下就绪并运行(状态代码
r)
为了防止上述步骤 2 中发现的问题,我们发现有必要一次添加一张表进行复制,并密切关注系统的性能。必须避免最坏的情况(事务回绕)。
如果您接近回绕,最好中止迁移并将其分解为更小的部分。
如果我们使用 FOR ALL TABLES 选项创建发布,Postgres 将立即开始同步我们非常大的源数据库,从而阻止自动 VACUUM 操作完成必要的维护。我们发现这会随着时间的推移逐渐降低数据库性能,从而导致系统稳定性风险增加。
一次添加一个表具有允许团队增量迁移每个表的额外优势。复制确实会带来源数据库和目标数据库的 CPU 成本和其他成本。通过一次添加一张表,管理员可以控制复制如何影响正在运行的系统。
中止一张表的复制
如果您需要停止表的复制,请首先反转添加发布表的说明:
-- On the old database
ALTER PUBLICATION pg_upgrade_pub_nocopy DROP TABLE my_append_only_table_name;
-- ON the new database
ALTER SUBSCRIPTION pg_upgrade_sub REFRESH PUBLICATION;
在紧急情况下,您还可以完全放弃publications和subscriptions,然后重新开始该过程。 Postgres 将清理作为发布和订阅的一部分创建的所有复制槽,这应该可以减轻源数据库的压力。
请注意,如果您只是禁用订阅而不从发布中删除表并刷新订阅,则源数据库将继续保留旧的事务 ID,这可能会导致事务回绕并强制关闭数据库。
仅禁用订阅并不能解决任何与复制相关的性能问题。
关于移动复制槽的注意事项
Postgres 中的复制槽存储可以在另一个数据库或另一个应用程序中使用的数据库活动日志。 Postgres 使用日志序列号 (LSN) 跟踪槽进度。 LSN 对于主 Postgres 数据库来说是唯一的。这意味着,如果您的数据库上有复制槽(例如,将更改复制到数据仓库或作为您自己的应用程序的一部分),您将无法将复制槽的 LSN 从旧数据库复制到新数据库。
您将需要查阅使用复制槽的应用程序的文档来决定如何最好地迁移(例如,对于数据仓库工具,它们可能有办法合并两个数据库之间的重复信息)。如果您使用复制槽作为自己的应用程序的一部分,那么您已经知道您需要自己推出自己的解决方案。拥有一些幂等机制来删除旧数据库和新数据库中的重复事务肯定会有所帮助。
完成迁移
将所有表添加到发布中并且订阅已赶上所有内容后,您现在需要验证表是否匹配。
不幸的是,最终一致性(应用于旧数据库的写入与显示在新数据库上的写入之间的滞后)将阻止两个数据库同时完美匹配,您仍然可以计算表行数以确保您足够接近以知道它正在工作。
在 Knock,我们编写了一个脚本来迭代每个表,并要求两个数据库计算新旧数据库中每个表中的总行数,并比较结果。对于具有 inserted_at 列的表,我们筛选出早于 10 秒的行。假设剩余 10 秒将在短时间内复制,此间隔足以证明表匹配。
您可能需要制定适合您的应用程序需求的策略。我们认为,只要行计数在几秒钟内准确,我们就可以假设 Postgres 复制是可靠的。
在某些情况下,我们还抽查了一些表的内容,以确保它们匹配,从而证实了这一假设。从表中收集行的随机样本并在新旧数据库之间进行比较可以帮助验证表是否相同。
应用程序级别的更改
与所有这些数据库工作并行,您可能需要更改应用程序以连接到这两个数据库。当您最终准备好切换时,您需要一个策略将流量转移到新数据库。
当最终切换发生时,您可以更改应用程序的配置以指向新数据库,然后重新启动应用程序。这很简单、直接,也正是我们迁移低流量数据库之一的方法。
对于具有大量并发活动的应用程序,您可能需要发挥创意。我们希望避免新旧数据库之间出现写入冲突的情况。此类冲突可能会导致我们的服务中断,需要手动协调数据库状态。
在 Knock,我们将应用程序配置为连接到两个数据库。当我们准备好执行切换时,我们运行了一个执行以下操作的脚本:
-
告诉我们应用程序的所有实例将新查询发送到新数据库
-
当前正在运行的所有数据库查询在被强制取消之前还有 500 毫秒的时间才能完成
-
在翻转标志后的第一秒,我们的应用程序人为地将任何新的数据库请求暂停一秒钟。这允许待处理的事务复制到新数据库,以便新查询不会有过时的读取
500 毫秒远远高于我们的大多数数据库查询,并且由于强制断开连接,我们看到了零错误
-
在其一秒之后,数据库活动恢复正常行为,但指向新数据库。
-
在切换过程中,我们有一些专门的数据库工作负载,脚本将其关闭并重新启动,以便重新连接到新数据库。
还有一件事:序列
复制不同步的一件事是任何 Postgres 序列。序列是单调递增的整数,保证永远不会重复。不幸的是,它们在新数据库上不会增加??,因为旧数据库上的序列值已用完。
幸运的是,这很容易控制。我们切换过程的一部分是在翻转我们的功能标志之前运行一个脚本,该脚本执行以下操作:
-
连接到两个数据库
-
使用
SELECT nextval('sequence_name')获取数据库中所有序列的下一个值 -
使用
SELECT setval('sequence_name', value::int4 + 100000)在新数据库中设置该值以推进序列并提供一点缓冲区(在这种情况下,在新数据库上设置该值和切换之间可以添加 100k 行)。这会在序列中引入间隙,但这通常不是问题。对于我们来说,我们的序列是 bigint。在这种情况下,序列中跳过的 100k 个值是 0% 用完的序列值的舍入误差。您需要调整引入的间隙有多大,这样就不会使用过多的序列可用空间。如果您只希望序列在切换窗口期间使用几百个值,那么可能只需将其提前 5000。
切换前的最终检查表
以下是我们在执行最终切换之前考虑的一些事项:
- 所有表上的行是否符合预期?
- 所有订阅是否均已启用并运行且没有错误?
- schemas 匹配吗?您能否冻结任何新架构迁移的发布,以降低迁移时发生更改的风险?
- 您的新数据库的大小是否适合您的工作负载?
- 您是否必须添加任何只读副本以使新旧数据库之间的数据库集群拓扑相同?
- 您是否对新数据库重新索引并执行了基本的 VACUUM 维护,以确保它是最新的并准备好用于生产流量?
- 您是否仔细检查了 Postgres 的发行说明中是否有任何可能导致应用程序回归的内容?
- 您是否对新版本上的临时数据库运行了自动和手动测试以验证系统性能?
- 您是否使用
pg_bench针对新版本运行了最苛刻的查询的负载测试以验证性能? - 如果有一件事你仍然可以降低风险,那是什么?
- 在临时或测试环境中进行练习运行,直到您多次完全执行了切换过程。像这样的试运行将有助于在投入生产之前发现计划中的差距。
- 在切换之前,进行数据库备份 - 以防万一。
切换
在 Knock,我们花了几周时间一次复制一张表。我们通常在工作时间之后和流量最低的时间段内进行此操作。我们在临时环境中进行了多次切换练习,完善了流程,直到无需太多操作员参与即可正常工作。
一旦我们有了运行 PG 15 的副本并准备好了从旧数据库切换到新数据库的应用程序代码,我们就运行最后一组检查并翻转标志。
经过几个月的准备,实际的切换很顺利:我们的应用程序在几秒钟内就切换了,当查询等待允许复制时,我们有一个短暂的(故意的)延迟,并且我们的应用程序继续运行,没有跳过。阅读本段花费的时间比切换本身还要长。
从那里,我们回滚了引入的应用程序更改,将所有内容永久指向新数据库,删除了新数据库上的订阅,并拆除了旧数据库。我们已成功从 Postgres 11.9 升级到 15.3,且停机时间为零!
Conclusion 结论
虽然一次跨越 Postgres 的四个主要版本是一个艰苦的过程,但它是可以完成的,而且在很多方面它比预定的停机时间更安全:在执行实际的切换之前可以多次练习、测试和返工。在这个过程中的任何时候,我们都可以从旧数据库中删除publications并重新开始,而不会降低我们的服务。
现代客户期望 100% 的可用性。虽然这在技术上是不可能的,但零停机迁移可以更轻松地保持系统平稳运行,而不会造成重大服务中断。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!