图片速览 OOD用于零样本 OOD 检测的 CLIPN:教 CLIP 说不
| PAPER | CODE |
|---|---|
| https://arxiv.org/pdf/2308.12213v2.pdf | https://github.com/xmed-lab/clipn |
文章创新 以往由CLIP驱动的零样本OOD检测方法,只需要ID的类名,受到的关注较少。 本文提出了一种新的方法,即CLIP说“不”(CLIPN),它赋予了CLIP中说“不”的逻辑。
主要动机 我们的主要动机是使 CLIP 能够使用积极语义提示和否定语义提示来区分 OOD 和 ID 样本。
实现方法 具体来说,我们设计了一种新颖的可学习的“不”提示和“不”文本编码器,以捕获图像中的否定语义。随后,我们引入了两个损失函数:图像文本二进制相反的损失和文本语义相反的损失,我们用它来教导 CLIPN 将图像与“否”提示相关联,从而使其能够识别未知样本。此外,我们提出了两种无阈值推理算法,利用来自“no”提示和文本编码器的否定语义来执行 OOD 检测。
实验结果 在9个基准数据集(3个ID数据集和6个OOD数据集)上用于OOD检测任务的实验结果表明,基于ViT-B-16的CLIPN在ImageNet-1K上零样本OOD检测方面,在AUROC和FPR95方面比7种常用算法至少高出2.34%和11.64%。
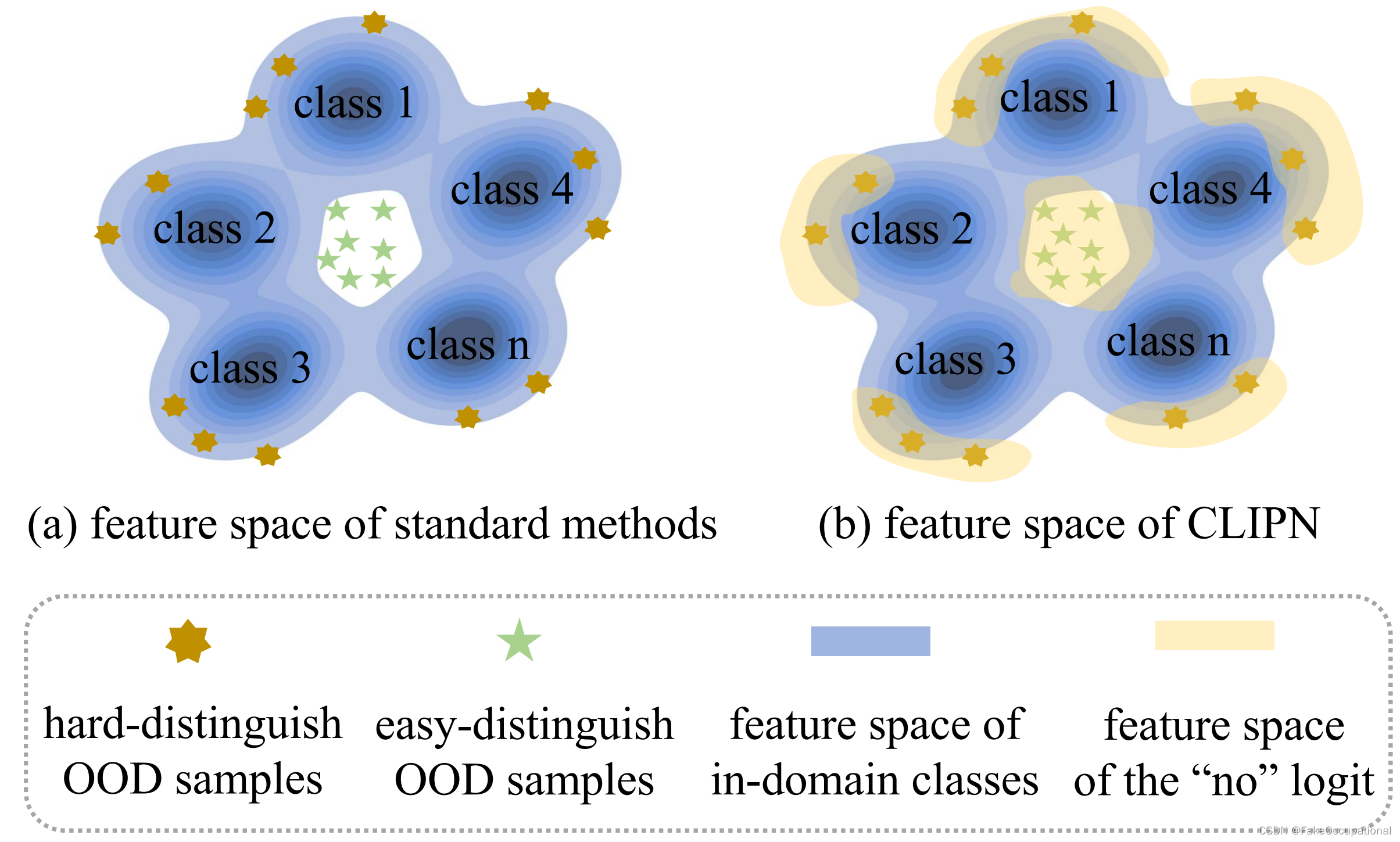
????????标准OOD检测算法和所提出的CLIPN之间的特征空间的玩具比较图。我们的方法涉及一个“否”逻辑,它提供了一个新的特征空间(黄色区域)来直接识别 OOD 样本。定性实验可视化如图所示。
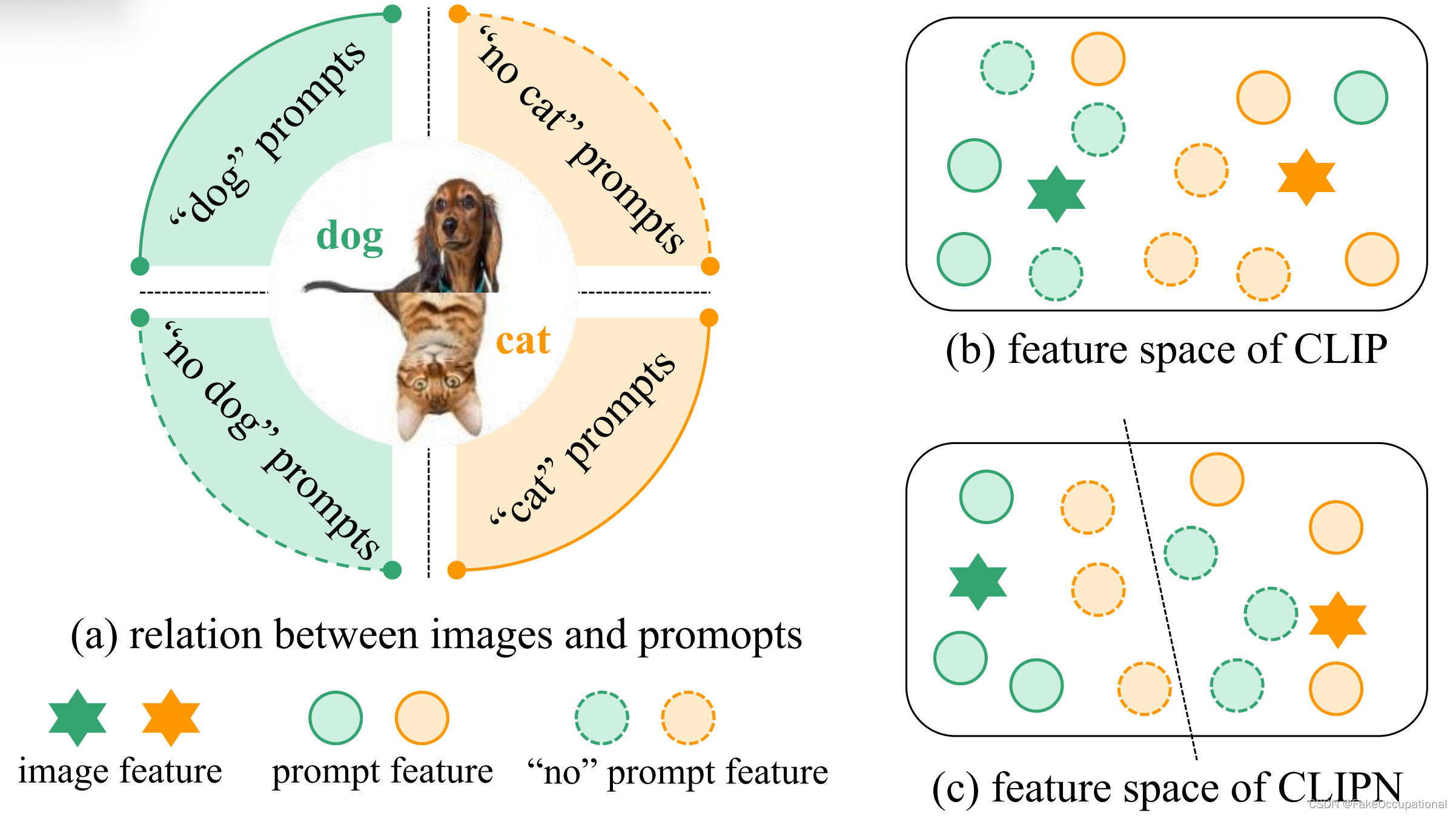
????????用于确定原始 CLIP 缺少“否”逻辑的示例插图。如图(a)所示,给定一个狗图像和一个猫图像,我们设计了四组提示。两组包含带有(with,of,having)狗(或猫)的照片的类提示,而另外两组使用“no()”提示的照片。我们在 CLIP 上进行了一项实验,将图像与四个提示相匹配。不幸的是,结果显示 CLIP 无法准确匹配图像,这意味着它缺乏“无”逻辑;
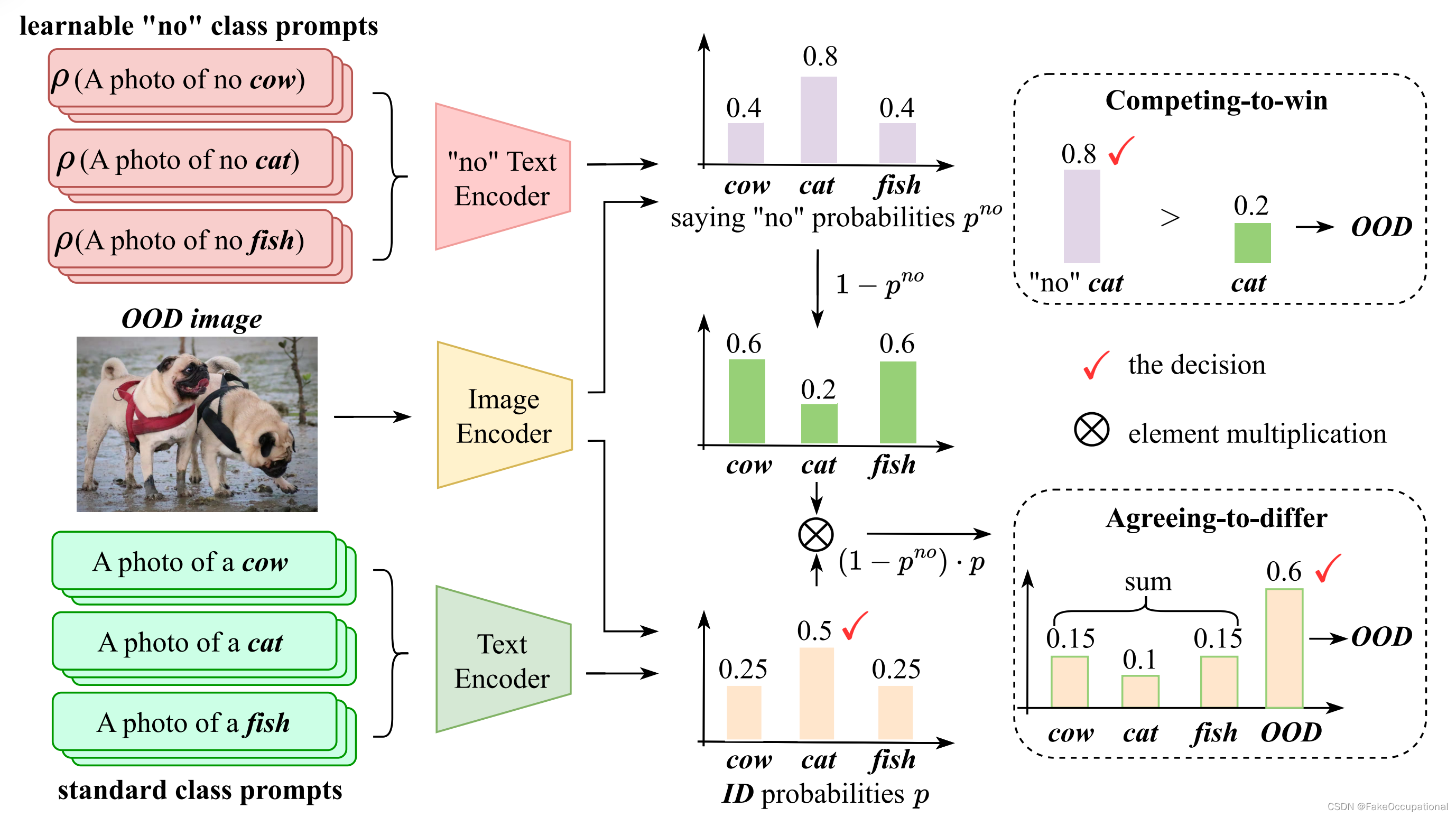
????????CLIPN 的推理流水线。它由三个网络组成:图像编码器、文本编码器和带有可学习的“no”提示 ρ 的“no”文本编码器。在推理阶段,使用两个文本编码器共同确定结果。这里的 ID 类是牛、猫、鱼,OOD 类是狗。
????????(1)图像编码器 φ φ φ: CLIPN 的图像编码器φ与预训练 CLIP 的图像编码器保持相同的结构和参数。(2)文本编码器 ψ ψ ψ: CLIPN的文本编码器ψ与预训练的CLIP的文本编码器保持相同的结构和参数。(3)“no”文本编码器 ψ " n o " ψ^{"no"} ψ"no": 由预训练的CLIP的文本编码器初始化。但与ψ的区别在于我们设置了 ψ " n o " ψ^{"no"} ψ"no"可学习。

????????匹配 x 和 t " n o " t^{"no"} t"no" 的图示。绿色和粉红色框分别表示标准文本 t 和“否”文本 t " n o " t^{"no"} t"no" 。 m ( x i , t j " n o " ) = 1 m(x_i, t_j^{"no"}) = 1 m(xi?,tj"no"?)=1 表示它们匹配但不相关(即,“no”文本不是错误的描述,但在语义上无关紧要)。 m ( x i , t j " n o " ) = 0 m(x_i, t_j^{"no"}) =0 m(xi?,tj"no"?)=0 表示它们是反向匹配的(即,“no”文本与图像具有相反的语义)。
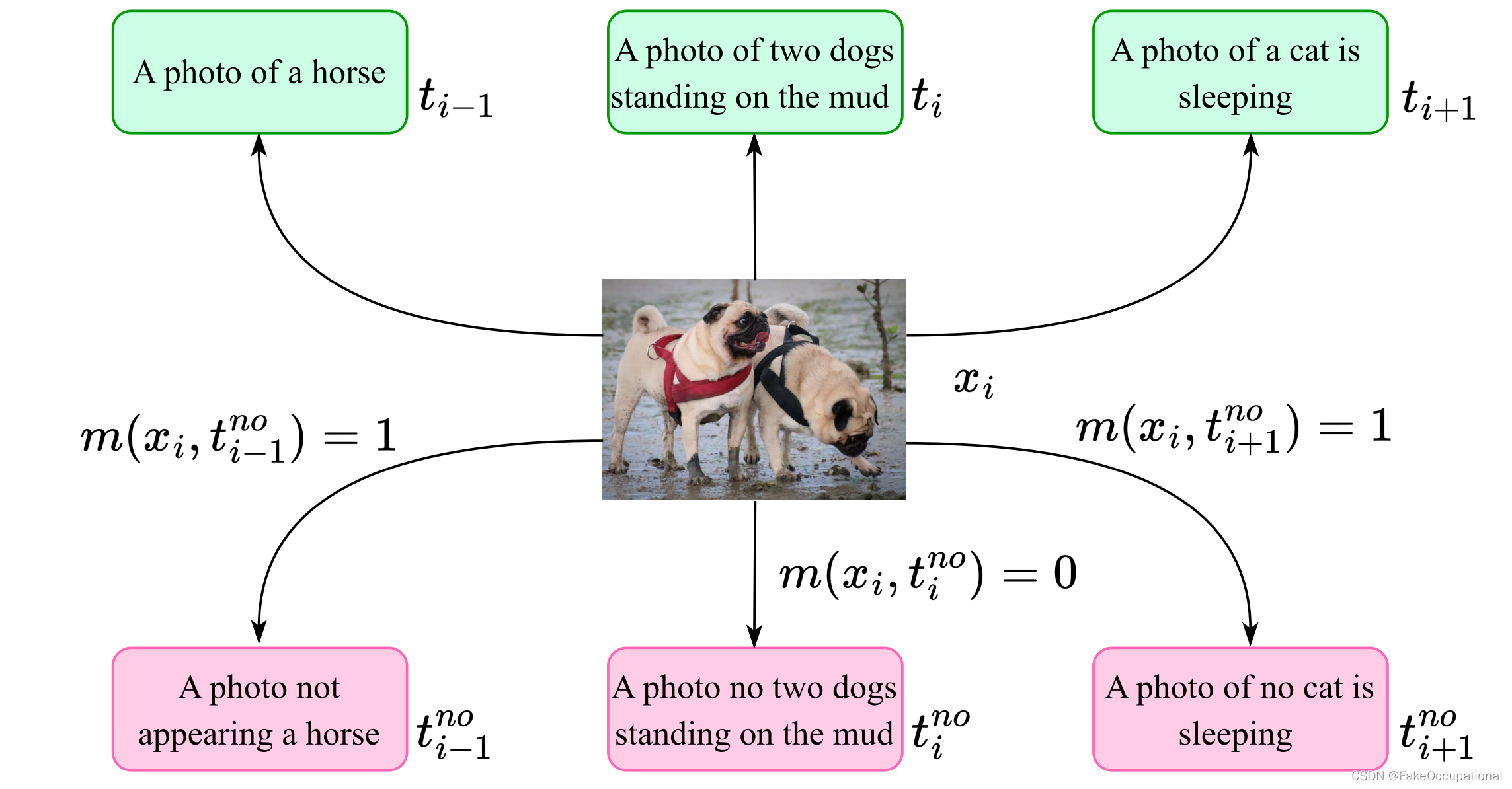
Image-Text Binary-Opposite Loss (ITBO) 此损失函数可帮助模型将图像特征与正确的“否”文本特征进行匹配。第 i 个图像和第 j 个“no”文本之间的匹配度可以定义如下:
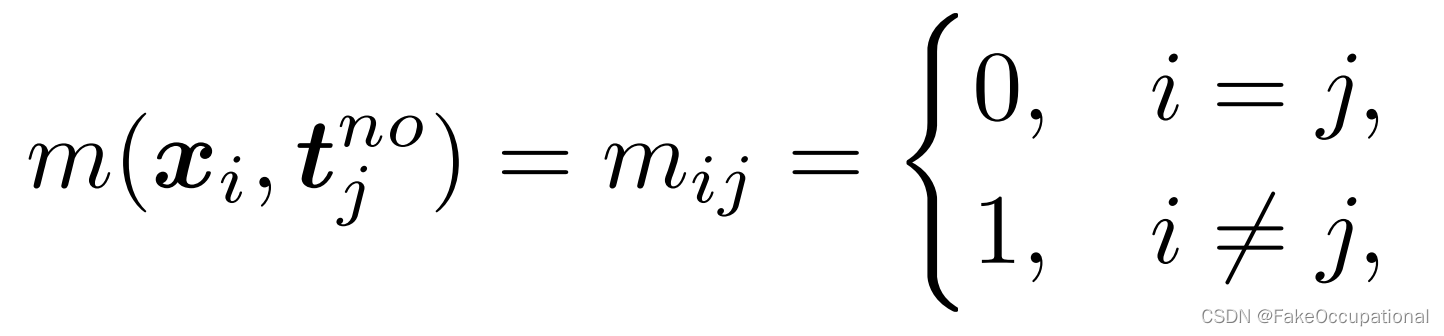
????????其中 m(x, t) = 0 表示它们反向匹配,m(x, t) = 1 表示它们匹配但不相关。然后我们驱动CLIPN 来匹配图像和no文本,以匹配性为指导。损失表述为:

Text Semantic-Opposite Loss (TSO) 在特征空间中,g也应该彼此相距较远:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!