一些想法:关于行人检测与重识别

本文主要是介绍我们录用于 ECCV'18 的一个工作:Person Search via A Mask-guided Two-stream CNN Model. 这篇文章着眼于 Person Search 这个任务,即同时考虑行人检测(Pedestrian Detection)与行人重识别(Person Re-identification),简单探讨了一下行人检测与行人重识别这两个子任务之间的关联性,并尝试利用全景图像中的背景信息来辅助 Re-ID. 最后我们的模型在 CUHK-SYSU 和 PRW 这两个数据集上都取得了不错的效果。
什么是 Person Search?
目前大家的焦点大都集中在 Person Re-ID 之上,比如 CVPR'18 的 Re-ID 相关文章数目就达到了惊人的三十多篇。Person Re-ID 处理的对象:probe image 和 gallery image 都是已经切好块了的,即图像中基本只包含了我们所感兴趣的这个人,其他可能的干扰信息(比如背景、遮挡、另外的行人等)已经尽可能降到了最低。当然了,这是为了创建一个统一的、标准化的研究课题而做的一个实验室环境下的约束。随着 Person Re-ID 的性能被逐渐刷高,是时候考虑一下与实际应用更接近一些的任务了,比如 Person Search.
Person Search 处理的对象中,probe image 与 Re-ID 一样,依然是切好块的图像;而 gallery image 变成了未切块的全景图像,也就是一般相机拍出来的未经过处理的图像。一张全景图像中通常包含了多个行人,如果要将已有的 Re-ID 技术用起来的话,那就得事先找到各个行人在全景图像中的位置。因此,Person Search = Pedestrian Detection + Person Re-ID.

行人检测与行人重识别;图片来自 Zheng et al. [1]
Pedestrian Detection 与 Person Re-ID 两者作为相对独立的课题已经被研究多年,两者的研究现状已经相对比较成熟;因此我认为 Person Search 并不着眼于这两者的具体技术,而应该考虑这两个任务之间相互关系,将这关系中的先验信息融入到模型中去。
那么?Pedestrian Detection 与 Person Re-ID 有什么关系呢?或者说?Person Search 与 Person Re-ID 相比有何不同?本文主要就针对这两个问题给出了两个粗浅的答案。
1. Pedestrian Detection 与 Person Re-ID 的目标函数相互矛盾。
对于一个 Pedestrian Detector 来讲,它的目标是正确地区分一个 proposal 是背景还是行人。理想的情况下,detector 会把所有的背景归为一类,所有的行人归为另一类,不管这个行人他是谁,发型怎么样,衣服包包什么颜色,或高或矮或胖或瘦,描述这些行人的特征向量的距离都必须足够小。因此,detector 关注的是行人之间的共性,比如人体轮廓。
但是 Re-ID 模型就不一样了,它的(训练)目标是正确地区分一个已知是行人的 proposal 是谁。既然要分辨这个行人是谁,那么高矮胖瘦发型衣服之类的信息就变得及其重要了。同时也要求描述不同身份的行人的特征向量的距离尽可能大。因此,Re-ID 模型关注的是行人之间的个性。
State-of-the-art 的模型 [2, 3, 4] 都将 detection 与 Re-ID 融合到了同一个框架中, Re-ID 的多分类 loss 与 Faster R-CNN 的二分类 loss 混在一起联合训练,因此不可避免的会碰到目标函数上的矛盾,让可怜的神经网络迷迷糊糊摸不着头脑。于是我们决定:
分成两个模型独立训。。。
是的,简陋粗暴,一点都不优雅。黑是黑了点,好歹还是能抓老鼠的。来看个简单的对比:

表 (a) 描述的是 detector 性能的对比。OIM-ours 是我们用 Pytorch 重新实现的 OIM 模型 [2], 在最终的 person search performance 与论文中的 performance 一致的情况下,它的 detector AP 为 69.5%; 在相同的情况下,我们把 OIM 模型中的 OIMLoss 去掉,用相同的参数仅训练一个 Faster R-CNN, 通过调整 detection threshold 使两者的 recall 相同的情况下,后者的 AP 比前者高了将近 10 个点。 因此可以得出结论一:Re-ID 的分类 loss 会干扰到 detector 的训练。
表 (b) 描述的是在撇开 detector 最终性能的情况下,Re-ID 的 performance 比较。两者都基于 ResNet-50, 以 OIMLoss 为分类 loss; 区别是前者基于 Faster R-CNN, 与 detection loss 一起训练,而后者 IDNetOIM 则是用 ground truth bounding box 训练和测试。后者的 performance 微微高于前者,因此可以得出结论二:Detector 的分类 loss 会干扰到 Re-ID 的分类 loss.
综合两个结论,可以认为 Pedestrian Detection 与 Person Re-ID 这两个任务确实互有干扰。因此我们最终的模型采用了 detector 与 Re-ID feature extractor 分离的策略。尽管这么做是粗糙了点,后续如果能想办法显式地建模两个任务之间的关联性,并融入到 Faster R-CNN 中去,将会是个更有意思的工作。
2. Person Search 有背景!更多的背景!
Person Search 的数据集中都是全景图片,相比 Re-ID 数据集中切好块的图像多了很多背景信息。然而,背景信息对行人重识别是否有用?这个问题却不太好回答,毕竟我们人类自己也搞不太清楚自己是怎么认人的。试想一下,一分钟前我看到了一个推着婴儿车的老人走过,一分钟后我在另一个地点同样看到了一个推着婴儿车的老人经过,那么「婴儿车」这个背景信息很可能会作为一个很强的暗示,使得自己认为这两个老人是同一个人;另一方面,我们的目标是为了「认人」,然而当前这个老人完全可以在你没看到他的时候扔下婴儿车,当我们下一次见到这个老人的时候,「有没有婴儿车」这个背景信息反而成为了我们作出判断的干扰因素。
目前在行人重识别领域,主流观点还是倾向于认为背景信息是一个干扰项,得想办法去掉,比如 CVPR'18 上的两篇文章 [5, 6]。但是 [5] 和 [6] 中却同时有一个相同的发现:将背景完全抹掉,只保留前景行人的话,Re-ID 的 performance 会略微下降。[5] 把这个现象归结为 background-bias, 认为是数据集不够好,得尽量避免这样的 bias; [6] 认为造成这种现象的原因是图像的结构信息和光滑性因去掉了背景而遭到了破坏。这两个解释确实非常有道理,而且两者基于各自的解释所做的处理方案都非常出色。然而,我们是否可以作出一个更加直接更加 spontaneous 的假设,认为「背景信息对 Re-ID 是有帮助的」呢?
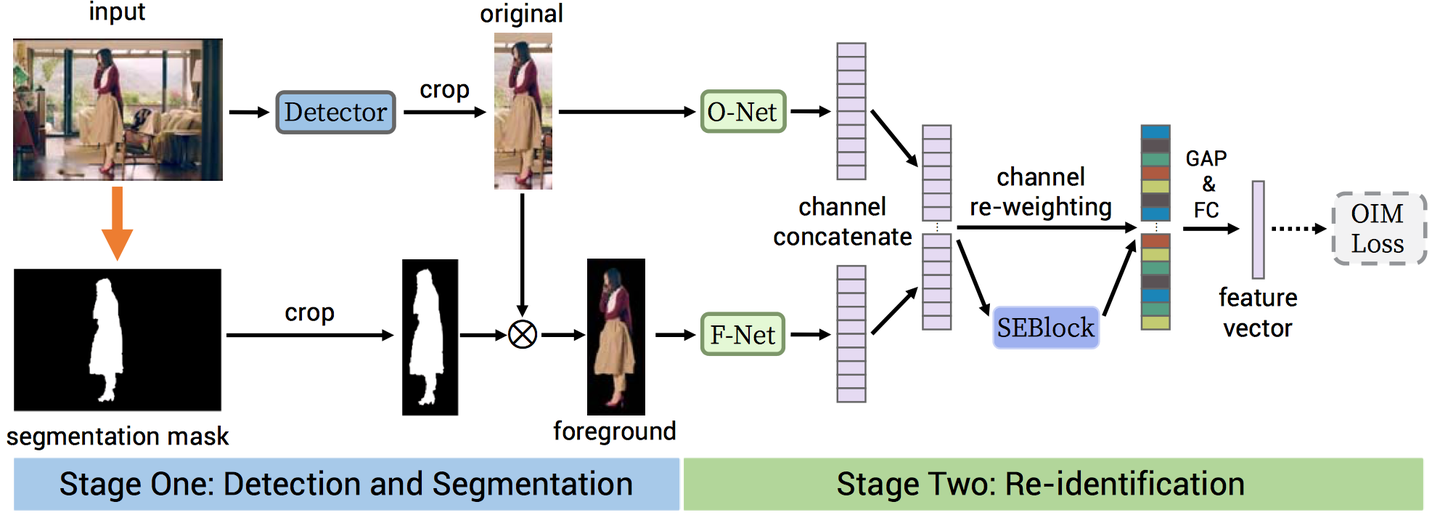
本文模型的后半部分即基于这个假设,显式地利用了背景信息并将其融入到最终的表示向量中。模型的大致框架如下图所示。一张全景大图经过 detector 检测到行人后,将 bounding box 扩大?γ倍以获取更多背景区域,从原图中扣出;用预训练好的 FCIS 模型分割出前景行人;接着将 (仅前景,原图) 这个图像对分别送入基于 ResNet50 的 F-Net 与 O-Net 中,前馈至最后一个卷积层后将 feature maps 按 channel 方向级联;用一个 SEBlock 给所有通道分配不同的权重后,作 global average pooling 并投影至一个?L2?标准化的低维空间,得到最终的特征向量。

先来看一个 ablation study:

表格中将 (原图,仅前景,仅背景,扩张 bounding box) 四个元素进行了各种组合的实验,能够得到以下两个结论:
- 在仅保留前景的情况下,mAP 比使用原图低了 2.8 个点,这个发现与前文提到的 [5, 6] 中的发现一致;在仅使用背景的情况下,扩张 RoI 能够将 mAP 提升 4.5 个点。因此我们认为背景是一种有用的指示信息。
- 同时考虑「前景+扩张后的背景」或者 「前景+扩张后的原图」能够极大地提升性能(其中后者可以认为是在同时考虑前景和背景的情况下强调了一遍前景)。我们最终的模型基于表中最后一行,将 ground truth boundinhg box 替换成 detector 生成的结果后,在 CUHK-SYSU 上的 mAP 和 top-1 accuracy 分别为 83.0 和 83.7.
OK, 那么在已知背景信息有用的情况下,背景信息对模型的影响有多大呢?为了回答这个问题,我们对 SEBlock 生成的 channel weights 进行了一个统计。SEBlock re-weight 的对象既有来自前景信息的通道,也有来自全图,即前景+背景信息的通道,因此生成的 weights 能够一定程度上反映前景信息和背景信息的相对重要程度。对于第?i?个样本,我们分别统计一下三个度量标准:1) 前景通道的权重平均值?Avgi(F); 2) 背景通道的权重平均值?Avgi(O); 3) 排名前20的最大的权重值中,对应于前景通道的权重值的个数?N20(F). 其中?N20(F)?的直方图如下图所示:

基于统计信息我们给出三个观察:
- 对于所有的样本?Avgi(F)>Avgi(O)?均成立,说明在 Re-ID 的表示向量中前景信息比既有前景又有背景的全图信息占有更重要的地位。
- 对于多数样本而言,最重要的前20个通道来自于前景信息的居多(?N20(F)>10?),结论与上一条相同。
- N20(F)?只是略大于 10 而不是极端地偏向 20, 说明最重要的前20个通道中有相当一部分来自全图信息,因此可以认为包含在全图信息中的背景信息的重要性仅略小于前景信息。
OK, 接下来的问题是:引入多少背景信息才合适呢?上文中我们的模型通过将 bounding box 扩大?γ?倍来引入更多的背景信息,?γ?的值越大,引入的背景信息越多。其中?γ?都直接设为了 1.3。?γ?取不同值时模型的 performance 变化如下图:

结论:小背怡情,大背伤身!
总结来讲,本文的模型和方法都略显简单粗暴,连 reviewer 给的意见也是 "straightforward", 倒幸好是 "... appreciate the straightforward..."。Anyway, 希望文中大量的分析能够给同行们提供一些好的参考吧。
感谢阅读!
References:
[1] Zheng, L., Zhang, H., Sun, S., Chandraker, M., Yang, Y., Tian, Q.: Person re-identi?cation in the wild. In: CVPR. (2017)
[2] Xiao, T., Li, S., Wang, B., Lin, L., Wang, X.: Joint detection and identi?cation feature learning for person search. In: CVPR. (2017)
[3] Xiao, J., Xie, Y., Tillo, T., Huang, K., Wei, Y., Feng, J.: Ian: The individual aggregation network for person search. arXiv preprint arXiv:1705.05552 (2017)
[4] Liu, H., Feng, J., Jie, Z., Jayashree, K., Zhao, B., Qi, M., Jiang, J., Yan, S.: Neural person search machines. In: ICCV. (2017)
[5] Tian, M., Yi, S., Li, H., Li, S., Zhang, X., Shi, J., … Wang, X.: Eliminating Background-Bias for Robust Person Re-Identification. in CVPR. (2018)
[6] Song, C., Huang, Y., Ouyang, W., & Wang, L.: Mask-Guided Contrastive Attention Model for Person Re-Identification. in CVPR. (2018)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!