实现List接口的常用三类
实现List接口的常用三类分别是ArrayList, vector, LinkedList,我们来看一下List接口的体系图:

这里我们可以查看类提供的相关方法,这里我们用代码实例来给大家演示一下常用的方法:
1.ArrayList
该方法在之前的博客中也写过相关实例但是这次我们要分析相关源码。
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Array {
@SuppressWarnings({"all"})
public static void main(String[] args) {
List list = new ArrayList();
for (int i = 0; i < 12; i++) {
list.add("hello" + i);
}
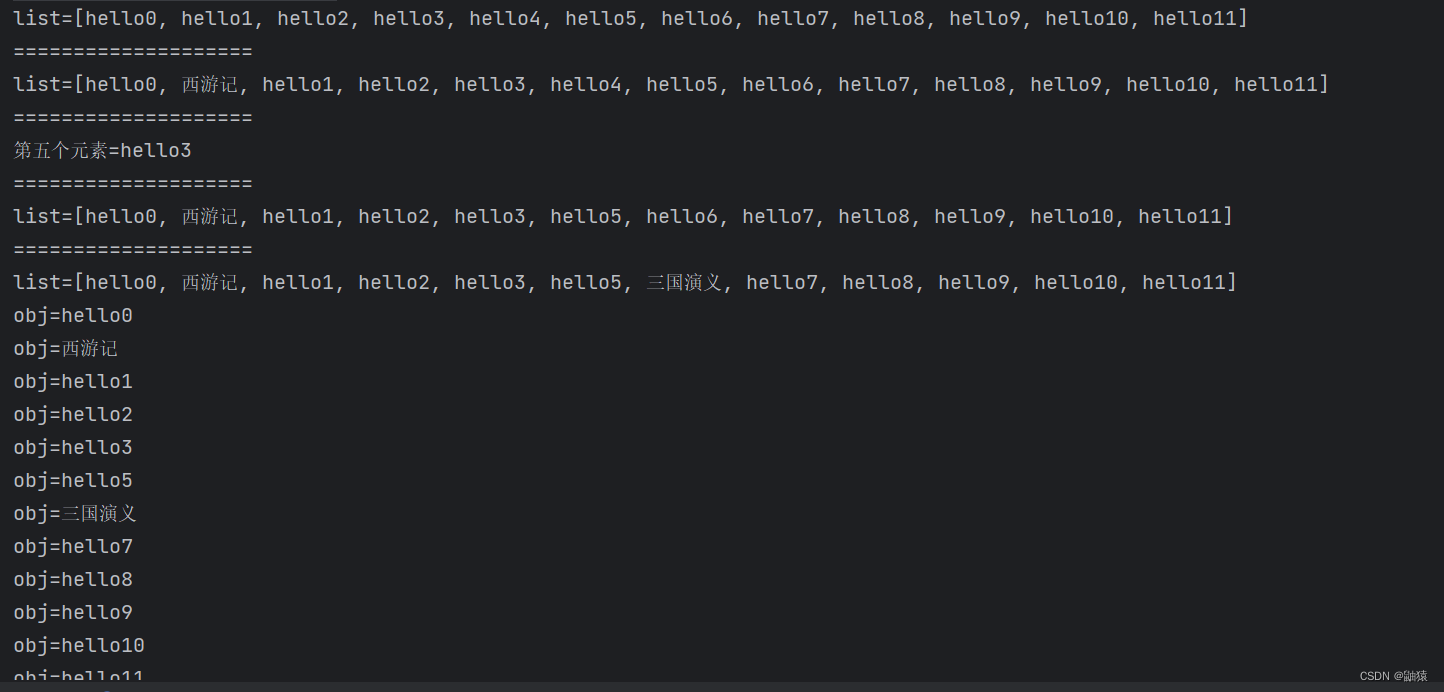
System.out.println("list=" + list);
//在 2 号位插入一个元素"西游记"
System.out.println("====================");
list.add(1, "西游记");
System.out.println("list=" + list);
//获得第 5 个元素
System.out.println("====================");
System.out.println("第五个元素=" + list.get(4));
//删除第 6 个元素
list.remove(5);
System.out.println("====================");
System.out.println("list=" + list);
//修改第 7 个元素
list.set(6, "三国演义");
System.out.println("====================");
System.out.println("list=" + list);
//在使用迭代器遍历集合
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
}
}
Vector,LinkedList方法和ArrayList的方法基本相似,这里也就不一一列举了。
接下来我们就要来解释一下集合是如何存储数据的,以及它的扩容机制,首先我们发现集合是不用进行长度的定义的,但是我们却可以存储很多数据,这里我们就来解释一些该原因:
import java.util.ArrayList;
import java.util.List;
public class Array {
@SuppressWarnings({"all"})
public static void main(String[] args) {
List list = new ArrayList();
list.add("红楼梦");
}
}这里我们选用的是ArrayList的无参构造器,ArrayList也有有参构造器但是机理是差不多的,待会分析,我们先来看一下无参构造器的扩容机理。?


当我们调用无参构造器时我们就会调用this.elementData这个方法

给this对象赋值的语句在源码中是一个空列表,而且是private static final修饰的,所以在初始化列表的时候一开始为空,接下来分析add方法的添加机制。

add方法调用的是该方法,我们看到有一个E e这个参数,这里的E类型是后面要提出的泛型知识,这里不进行深入讨论。
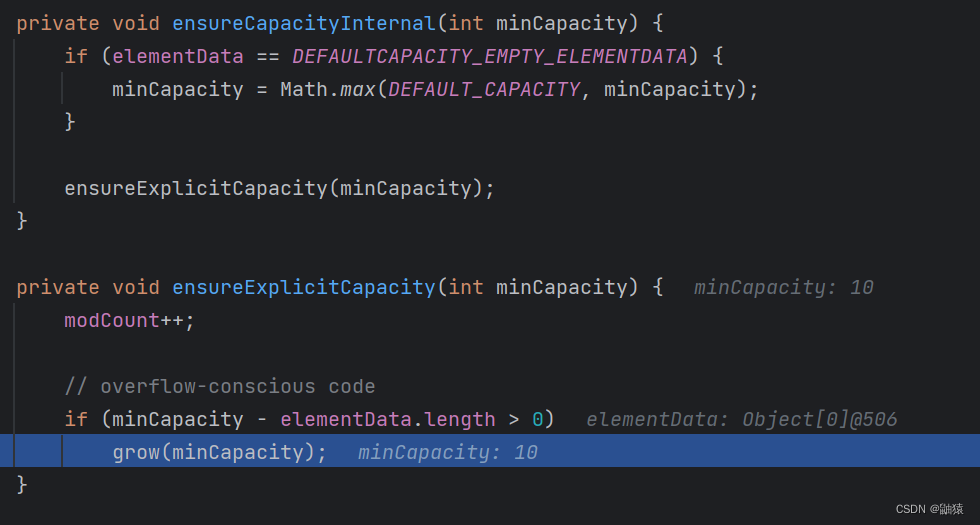
当我们进入到ensureCapacityInternal()这个方法中它会进行一系列的判断
if (minCapacity - elementData.length > 0)
最终调用到grow方法来进行扩容。接下来就来分析它的扩容过程:

这里我们会发现进入copyof方法的是newCapacity这个值,copyof才是真正对列表扩容的方法。


当我们进行add方法的时候,如果容量不够就会进入我们的扩容机制
if (minCapacity - elementData.length > 0)
这里就是进行是否扩容的判断条件,而且ArrayList扩容后的容量也和源码中的newCapacity的值一致,但是这里我们是否能添加相同的元素呢,这里我们也来看一下:

这里我们发现是可以添加相同的元素的,如果想限制相同方法的元素可以参考后续讲解的Set接口下的实现类。
这里我们知道一开始扩容到了10,如果添加的数据超过10个,后续是如何扩容的,其实调用的方法是差不多的只是newCapacity该值的更新不一样而已这里我们也查看一下:

这里我们的size变成了11,接下来我们看一下是如何扩容的:

我们发现newCapacity的值是oldCapacity用位运算符向右移动一个单位就相当于10/2然后它还又加上了原来的数值就相当于10/2 + 10,相当于原数值的1.5倍。我们发现初始化的扩容和后期的扩容机制是不相同的,我们来看一下后期的扩容是不是我们预期的一样是15:

跟我们的预期是一样的。Vector的扩容机制跟ArrayList很像,但是Vector的后期扩容是两倍扩容,Vector和ArraryList基本上是相同的,它们最主要的区别就是;
ArraryList:它是高效率,但是线程不安全的;
Vector:它是线程安全,但是效率比较低:
2.接下来我们来介绍LinkedList的相关细节:
该列表的存储对象跟前两个不同,它的底层实现了双向链表和双端队列的特点;
LinkedList底层维护了两个属性一个是frist和last,一个是头节点,一个是尾节点;
每个节点里面又维护了Node对象,对象里存在(prev,next,item)三个属性,对象与对象之间的连接是通过prev指向前一个对象,next指向下一个对象,最终实现双向链表。
LinkedList对元素的添加和删除不是通过数组来添加的,所以相对而言效率要更高一点;
这里我们来写一段实例来看一下如何操作该链表:
public class Array {
@SuppressWarnings({"all"})
public static void main(String[] args) {
Node jack = new Node("jack");
Node tom = new Node("tom");
Node mack = new Node("mack");
//连接三个结点,形成双向链表
//jack -> tom -> mack
jack.next = tom;
tom.next = mack;
//mack -> tom -> jack
mack.pre = tom;
tom.pre = jack;
Node first = jack;//让 first 引用指向 jack,就是双向链表的头结点
Node last = mack; //让 last 引用指向 mack,就是双向链表的尾结点
//演示,从头到尾进行遍历
System.out.println("===从头到尾进行遍历===");
while (true) {
if(first == null) {
break;
}
//输出 first 信息
System.out.println(first);
first = first.next;
}
//演示,从尾到头的遍历
System.out.println("====从尾到头的遍历====");
while (true) {
if(last == null) {
break;
}
//输出 last 信息
System.out.println(last);
last = last.pre;
}
//演示链表的添加对象/数据,是多么的方便
//要求,是在 tom --------- mack直接,插入一个对象 smith
//1. 先创建一个 Node 结点,name 就是 smith
Node smith = new Node("smith");
//下面就把 smith 加入到双向链表了
smith.next = mack;
smith.pre = tom;
mack.pre = smith;
tom.next = smith;
//让 first 再次指向 jack
first = jack;//让 first 引用指向 jack,就是双向链表的头结点
System.out.println("===从头到尾进行遍历===");
while (true) {
if(first == null) {
break;
}
//输出 first 信息
System.out.println(first);
first = first.next;
}
last = mack; //让 last 重新指向最后一个结点
//演示,从尾到头的遍历
System.out.println("====从尾到头的遍历====");
while (true) {
if(last == null) {
break;
}
//输出 last 信息
System.out.println(last);
last = last.pre;
}
}
}
//定义一个 Node 类,Node 对象 表示双向链表的一个结点
class Node {
public Object item; //真正存放数据
public Node next; //指向后一个结点
public Node pre; //指向前一个结点
public Node(Object name) {
this.item = name;
}
public String toString() {
return "Node name=" + item;
}
}
当我们使用迭代器对LinkedList链表进行遍历的时候要注意一下,当我们二次遍历的时候要将frist头节点重新定位到第一个元素。
ArrayList和LinkedList之间的区别:
ArrayList底层是可变数组,而LinkedList底层是双向链表,二者的性质不同,LinkedList对增删操作的效率比较高,ArrayList对查改的效率比较高,两者都是线程不安全的,但是在以后的编程中对数据的查改操作更多,所以ArrayList是比较实用的,根据不同情况来选择不同的方式。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!