【没有哪个港口是永远的停留~论文解读】Polarized Self-Attention
Polarized Self-Attention : Towards High-quality Pixel-wise Regression
原文:https://arxiv.org/pdf/2107.00782.pdf
作者提出了一个即插即用的模块——极化自注意力机制( Polarized Self-Attention(PSA)),用于解决像素级的回归任务,相比于其他注意力机制,极化自注意力机制主要有两个设计上的亮点:
????????1)极化滤波( Polarized filtering):在通道和空间维度保持比较高的resolution(在通道上保持C/2的维度,在空间上保持[H,W]的维度 ),这一步能够减少降维度造成的信息损失;
????????2)增强(Enhancement):采用细粒度回归输出分布的非线性函数。

结构
通道注意力+空间注意力

逐像素回归问题面临着特殊的挑战:
- 在合理的成本范围内保持高分辨率
- 拟合输出分布,例如关键点热图或分割掩码。
差别比较

SM: softmax、SD: Sigmoid、ch:通道 、sp:空间?
内部分辨率与复杂性:
与现有的注意力块在其顶级配置下进行比较,PSA 为两者保留了最高的注意力分辨率,通道 (C/2) 和空间 ([W; H]) 维度。
此外,在我们的仅通道注意力中,Softmax重新加权与SE激励融合,利用 Softmax 作为大小 C/2 × W × H 的 bottleneck 处的非线性激活。
通道数 (C-C)/(2-C) 遵循SE模式,这比GC 和 SE 块都好。
我们不仅只关注空间的注意力,保持完整[W; H]空间分辨率,也关注内部,保持Wq 和 Wv 中的 2×C×C/2 个可学习参数,非线性 Softmax 重新加权,这是比现有块更强大的结构。
Polarized Self-Attention (PSA) Block
我们对上述挑战的解决方案是在注意力计算中进行“ polarized filtering 极化滤波”。
- 自我注意块对输入张量X进行操作以突出或抑制特征,这非常类似于滤光的光学透镜。
- 在摄影中,在横向方向上总是有随机光,产生眩光/反射。
- 偏振滤光,通过只允许光垂直于横向通过,可以潜在地提高照片的对比度。
由于总强度的损失,滤波后的光通常具有较小的动态范围,因此需要额外的提升,恢复原始场景的细节
我们借用摄影的关键要素,提出Polarized Self-Attention (PSA) 机制:
????????过滤:在一个方向上完全折叠特征,同时保持正交方向的高分辨率;
????????HDR:通过 Softmax 增加注意力的动态范围在瓶颈张量(注意力块中的最小特征张量)处进行归一化,然后进行色调映射Sigmoid 函数。

?
实验
实施细节。对于任何 带有瓶颈或基本残差块 的 baseline,例如 ResNet 和 HRnet,我们分别在每个残差块的第一个 3×3 卷积之后添加 PSA。
- 对于 2D 姿势估计,我们保持与 baseline 相同的训练策略和超参数。
- 对于语义分割,我们增加了 5000 次 iter 迭代的预热训练阶段,将总训练迭代拉伸了 30%,并保持 baseline? 其余训练策略和超参数。
PSA vs. Baselines
2D关键点实验,略
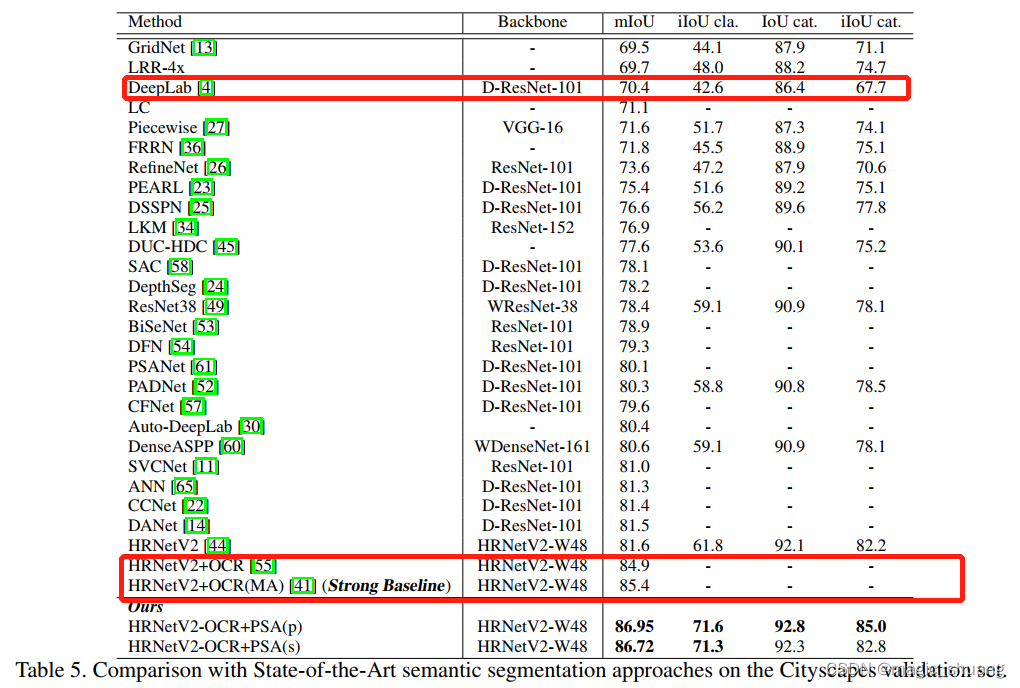
语义分割:
This task maps an input image to a stack of segmentation masks, one output mask for one semantic class. In Table 3, we compare PSA with the DeepLabV3Plus [4] baseline on the Pascal VOC2012 Aug [12] (21 classes, input image size 513 × 513, output mask size 513 × 513). PSA boosts all the baseline networks by 1.8 to 2.6mIoU(mean Intersection over Union) with minor overheads of computation (Flops) and the number of parameters (mPara). PSA with “Res50” backbone got 79.0 mIoU, which is not only 1.8 better than the DeepLabV3Plus with the Resnet50 backbone, but also better than DeepLabV3Plus even with Resnet101.

消融研究
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!