一文弄懂kubernetes之Service
目录
Service
在 kubernetes 中,Pod 是有生命周期的,如果 Pod 重启 IP 很有可能会发生变化。如果我们的服务都是
将 Pod 的 IP 地址写死,Pod 的挂掉或者重启,和刚才重启的 pod 相关联的其他服务将会找不到它所关
联的 Pod,更重要的是,如果容器应用本身是分布式的部署方式,通过多个实例共同提供服务,就需要在这些实例的前端设置一个负载均衡器来实现请求的分发。为了解决这些问题,在 kubernetes 中定义了 service 资源对象,Service 定义了一个服务访问的入口,客户端通过这个入口即可访问服务背后的应用集群实例,service 是一组 Pod 的逻辑集合,这一组 Pod 能够被 Service 访问到,通常是通过 Label SelectorLabel Selector 实现的,Service会将符合Label规则的Pod进行管理
简单来说,通过创建Service,可以为一组具有相同功能的容器应用提供一个统一的入口地址,并且将请求负载分发到后端的各个容器应用上
Service工作流程
-
创建Service:首先,通过Kubernetes资源描述文件或命令行工具创建一个Service对象。Service对象定义了服务的名称、选择器和端口等信息。Kubernetes会为该Service分配一个唯一的ClusterIP地址。
-
与Pod关联:通过定义Service的选择器,将Service与后端的Pod关联起来。选择器可以使用标签(Label)来指定匹配的Pod。
-
Endpoints生成:Kubernetes会自动创建一个与Service关联的Endpoints对象,并将匹配选择器的Pod的网络地址记录在Endpoints中。Endpoints对象会动态地跟踪Pod的变化,并更新其中的网络地址。
-
ClusterIP暴露:Service会为集群内部提供一个稳定的ClusterIP地址。其他同命名空间的Pod或者Service可以通过该ClusterIP地址来访问该Service。
-
负载均衡请求:当有请求发送到Service的ClusterIP地址时,请求会被转发到Service关联的后端Pod上。kube-proxy组件负责实现转发和负载均衡的功能。
-
kube-proxy处理:kube-proxy会监听Kubernetes API服务器,监视Service和Endpoints对象的变化。当发生变化时,kube-proxy会更新节点上的网络规则,以确保请求能够正确地路由到后端Pod上。
-
请求转发:根据负载均衡策略,kube-proxy将请求转发到后端Pod上。负载均衡策略可以是RoundRobin、LeastConnections等。
-
更新规则:如果有新的Pod加入或现有Pod退出,Endpoints对象会相应地更新,kube-proxy会检测到这些变化,并动态地更新网络规则,以确保新的Pod也能够参与请求的负载均衡。
kube-proxy
kube-proxy负责监听Kubernetes API服务器的Service和Endpoints对象,并根据它们的变化来动态更新本地节点的iptables规则或ipvs规则,以实现对Service IP地址的转发和负载均衡。kube-proxy支持三种模式:userspace、iptables和ipvs模式,三种模式各有不同,下面介绍一下
userspace
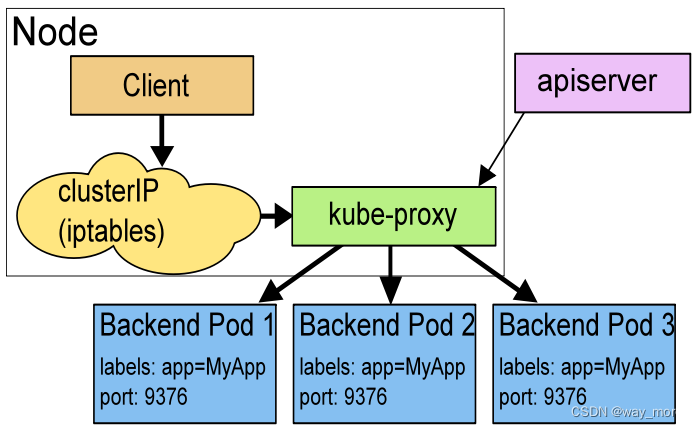
在 Userspace 模式下,对每个 Service,它会在本地 Node 上打开一个端口(随机选择)。 任何连接到“代理端口”的请求,都会被代理到 Service 的某个后端 Pods 上面。 使用哪个后端 Pod,是 kube-proxy 基于 SessionAffinity 来确定的。
它配置 iptables 规则,捕获到达该 Service 的 clusterIP 和 Port 的请求,并重定向到代理端口,代理端口再代理请求到后端Pod。
简单来说:就是kube-proxy创建了一个监听端口,然后根据 iptables 规则,将请求到 Service clusterIP 和 Port 的请求重定向到监听端口,然后kube-proxy根据负载均衡算法选择后端pod,将请求转发到该pod
默认情况下,userspace 模式下的 kube-proxy 通过轮询算法选择后端pod。
Userspace 模式的优点是兼容性较好,可以在几乎所有的环境中运行。然而,它的性能相对较差,因为每个请求都需要经过用户空间代理程序的处理。在大规模集群或高负载情况下,可能会成为性能瓶颈。
iptables
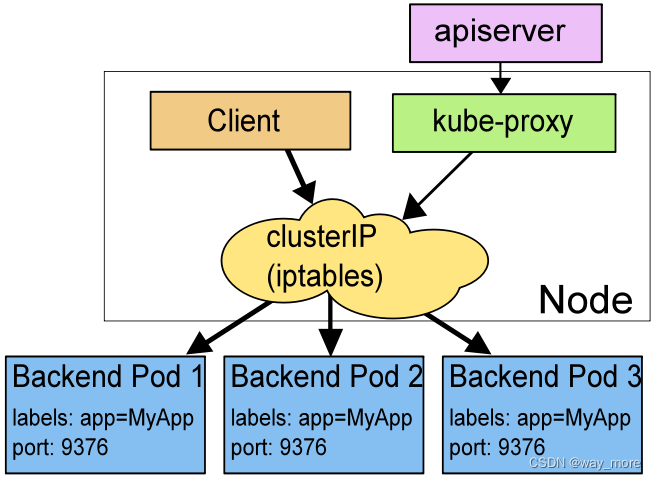
在 iptables 模式下,对每个 Service,它会配置 iptables 规则,当捕获到达该 Service 的 clusterIP 和端口的请求时,就会将请求重定向到 Service 的某个 Pod 上面。
简单来说,kube-proxy为service后端的每个Pod创建对应的iptables规则,直接将发向Cluster IP的请求重定向到一个Pod上面
IPTABLES 模式相对于 Userspace 模式来说,在性能方面更加高效,因为流量不需要经过用户空间的代理程序处理。
如果 kube-proxy 在 iptables 模式下运行,所选的第一个 Pod 没有响应,那么就会连接失败。 这与userspace 模式不同:在userspace 模式下,kube-proxy 与第一个 Pod 连接失败, 会自动使用其他后端 Pod 重试。
默认情况下,iptables 模式下的 kube-proxy 通过随机算法选择后端pod。
IPVS
Kubernetes v1.11 版本稳定
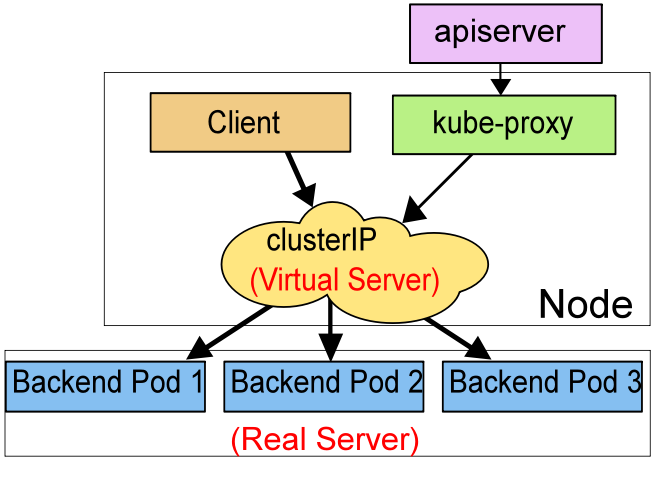
在 ipvs 模式下,kube-proxy 监视 Kubernetes 服务和端点,调用 netlink 接口(Linux 内核提供的一种用于内核与用户空间之间进行通信的机制)相应地创建 IPVS 规则, 并定期将 IPVS 规则与 Kubernetes 服务和端点同步。访问服务时,IPVS 将请求重定向到一个后端 Pod上 。
IPVS 支持以下的负载均衡策略
- rr:轮替(Round-Robin)
- lc:最少链接(Least Connection),即打开链接数量最少者优先
- dh:目标地址哈希(Destination Hashing)
- sh:源地址哈希(Source Hashing)
- sed:最短预期延迟(Shortest Expected Delay)
- nq:从不排队(Never Queue)
在 IPVS 模式下,kube-proxy 通过与内核交互,创建和管理 IPVS 规则和服务。与 IPTABLES 模式相比,负载均衡的计算是由 Linux 内核完成,IPVS 模式具有更高的性能和可扩展性,特别适用于大规模集群或高负载情况。
说明:
要在 IPVS 模式下运行 kube-proxy,必须在启动 kube-proxy 之前使 IPVS 在节点上可用。
当 kube-proxy 以 IPVS 代理模式启动时,它将验证 IPVS 内核模块是否可用。 如果未检测到 IPVS 内核模块,则 kube-proxy 将以 iptables 代理模式运行。
Endpoints
Endpoint是用于将服务(Service)与后端的Pod相关联的对象。Endpoints定义了一个服务对应的一组IP地址和端口,这些IP地址和端口用于实际转发到服务后端的Pod。
当创建一个Service时,Kubernetes会自动创建并更新与该服务关联的Endpoints对象。Endpoints对象中包含了服务所代理的一组后端Pod的IP地址和端口信息。
当添加、删除或更新后端Pod时,Kubernetes会自动更新对应的Endpoints对象,确保服务能够正确地将请求转发到有效的后端Pod。这就意味着,你无需手动管理Endpoints对象,Kubernetes会自动维护它们的状态。
Kubernetes 1.17版本开始引入EndpointSlice,并逐渐替代Endpoints资源
Service负载分发策略
目前Kubernetes提供了两种负载分发策略:未定义和SessionAffinity,具体说明如下。
未定义:默认情况下,Kubernetes会使用 kube-proxy的负载均衡算法,比如轮询、随机等,具体要看 kube-proxy的工作模式。
SessionAffinity:基于客户端IP地址进行会话保持的模式,即第1次将某个客户端发起的请求转发到后端的某个Pod上,之后从相同的客户端发起的请求都将被转发到后端相同的Pod上。
在默认情况下,Kubernetes采用kube-proxy对客户端请求进行负载分发,但我们也可以通过设置service.spec.sessionAffinity=ClientIP来启用SessionAffinity策略(默认值是 “None”)。这样,同一个客户端IP发来的请求就会被转发到后端固定的某个Pod上了。
Service属性
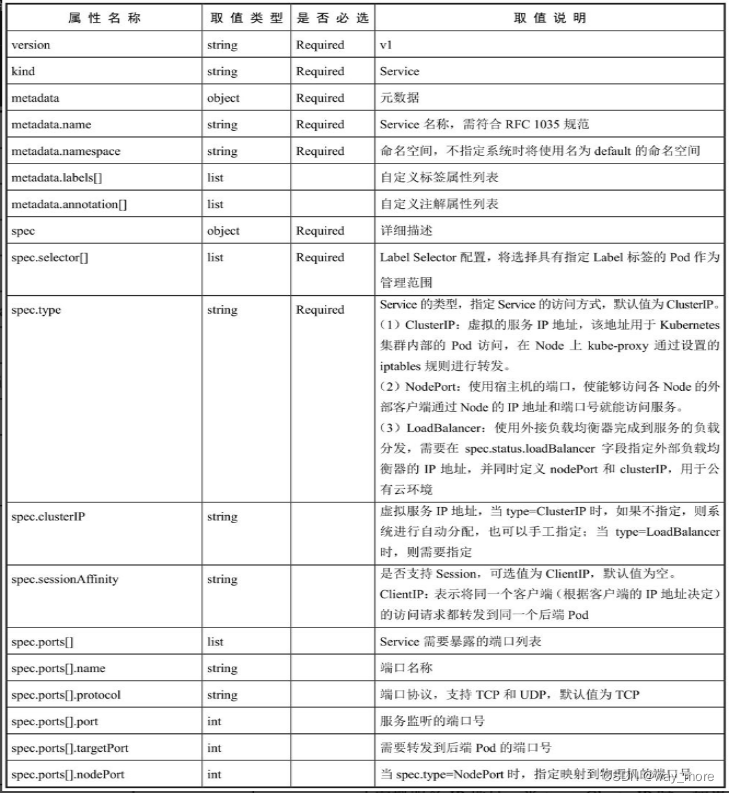
下面是service的属性说明
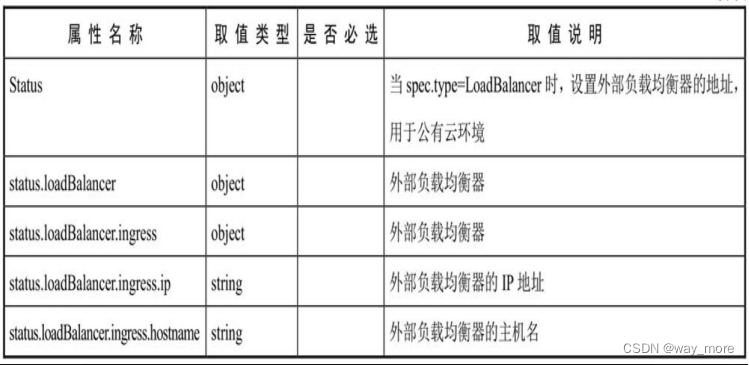
Service定义
Service 在 Kubernetes 中是一个 REST 对象,和 Pod 类似。所以我们创建Service,一般也是通过编写一个service文件,然后使用kubecctl create命令将service文件创建成service
下面是一个简单的service文件
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
上述配置创建一个名称为 “my-service” 的 Service 对象,它会将发送到my-service:80的请求代理到使用 TCP 端口 9376,并且具有标签 app.kubernetes.io/name=MyApp 的 Pod 上。
服务选择算符的控制器会不断扫描与其选择算符(selector)匹配的 Pod,然后将所有更新发布到称为 “my-service” 的 Endpoint 对象。
Service定义中的关键字段是ports和selector。本例中ports定义部分指定了Service所需的虚拟端口号为80,由于与Pod容器端口号9376不一样,所以需要再通过targetPort来指定后端Pod的端口号。selector定义部分设置的是后端Pod所拥有的label:app.kubernetes.io/name=MyApp 。
Service默认类型为ClusterIP,它为集群内的其他Pod提供了一个虚拟IP地址来访问该服务。
在创建一个ClusterIP类型的服务时,会为该服务分配一个虚拟的ClusterIP地址。当其他Pod想要访问这个服务时,可以通过该虚拟IP地址进行访问,而无需关注具体的后端Pod地址和端口号。
需要注意的是,ClusterIP类型的Service只能在集群内部使用,外部无法访问。如果需要从集群外部访问服务,则需要创建其他类型的Service,例如NodePort或LoadBalancer类型。
类型可以通过spec.type来设置
下面是一个NodePort类型的service示例
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: NodePort
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8080
nodePort: 30000
上述示例中,我们定义了一个名为"my-service"的Service资源,并将其类型设置为NodePort。该Service将会选择具有标签"app: my-app"的Pod作为后端。
在spec部分,我们定义了一个TCP协议的端口映射。将容器内的端口8080映射到Service的端口80上。此外,我们还指定了nodePort属性为30000,这意味着通过任何节点的IP地址和30000端口都可以访问该Service。
多端口Service
有时一个容器应用也可能提供多个端口的服务,那么在Service的定义中也可以相应地设置为将多个端口对应到多个应用服务。在下面的例子中,Service设置了两个端口号,并且为每个端口号都进行了命名:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
- name: https
protocol: TCP
port: 443
targetPort: 9377
说明:与一般的Kubernetes名称一样,端口名称只能包含小写字母数字字符 和 -, 端口名称还必须以字母数字字符开头和结尾。例如,名称 123-abc 和 web 有效,但是 123_abc 和 -web 无效。
外部服务Service
在某些环境中,应用系统需要将一个外部数据库作为后端服务进行连接,或将另一个集群或Namespace中的服务作为服务的后端,这时可以通过创建一个无Label Selector的Service来实现:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
由于此服务没有选择算符,因此不会自动创建相应的 EndpointSlice(和旧版 Endpoint)对象。 你可以通过手动添加 EndpointSlice 对象或者Endpoint对象,将服务手动映射到运行该服务的网络地址和端口:
EndpointSlice
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: my-service-1 # 按惯例将服务的名称用作 EndpointSlice 名称的前缀
labels:
# 你应设置 "kubernetes.io/service-name" 标签。
# 设置其值以匹配服务的名称
kubernetes.io/service-name: my-service
addressType: IPv4
ports:
- name: '' # 留空,因为 port 9376 未被 IANA 分配为已注册端口
appProtocol: http
protocol: TCP
port: 9376
endpoints:
- addresses:
- "10.4.5.6" # 此列表中的 IP 地址可以按任何顺序显示
- "10.1.2.3"
Endpoints
apiVersion: v1
kind: Endpoints
metadata:
name: my-service
subsets:
- addresses:
- ip: 10.0.0.1
- ip: 10.0.0.2
ports:
- port: 8080
protocol: TCP
在上述示例中,Endpoints对象名为my-service,它定义了一组IP地址和端口,即10.0.0.1:8080和10.0.0.2:8080。这意味着服务my-service将请求转发到这两个IP地址和端口上的后端Pod。
Headless Services
在某些情况下,我们希望自己控制service的负载均衡,不使用service默认提供的负载均衡,或者应用程序希望知道属于同组服务的其他实例。Kubernetes提供了Headless Service来实现这种功能,即不为Service设置ClusterIP(入口IP地址),仅通过Label Selector将后端的Pod列表返回给调用的客户端。
通过指定 Cluster IP(spec.clusterIP)的值为 “None” 就可以创建 Headless Service。
对于Headless Services,不会分配 Cluster IP,kube-proxy 不会处理它们, 而且平台也不会为它们进行负载均衡和路由。 DNS 如何实现自动配置,依赖于 Service 是否定义了选择算符。
apiVersion: v1
kind: Service
metadata:
name: my-headless-service
spec:
clusterIP: None
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8080
对于有选择符的Headless Services,Kubernetes DNS 将会返回与 Service 匹配的所有后端 Pod 的 IP 地址列表。这样客户端可以直接使用这些 IP 地址来与后端 Pod 进行通信。
对于无选择算符的 Headless Services ,当客户端使用 Service 名称进行 DNS 解析时,将会返回所有匹配的 Pod 的 IP 地址,客户端需要自行处理这些 IP 地址的使用方式,无选择算符的 Headless Services 适用于需要直接与所有 Pod 直接通信的场景,例如数据库集群、分布式存储系统等。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!