我常用的几个经典Python模块
Python常用的模块非常多,主要分为内置模块和第三方模块两大类,且不同模块应用场景不同又可以分为文本类、数据结构类、数学运算类、文件系统类、爬虫类、网络通讯类等多个类型。
大家常用的内置模块比如:math、re、datetime、urllib、os、random等,第三方模块比如pandas、numpy、requests、matplotlib等。
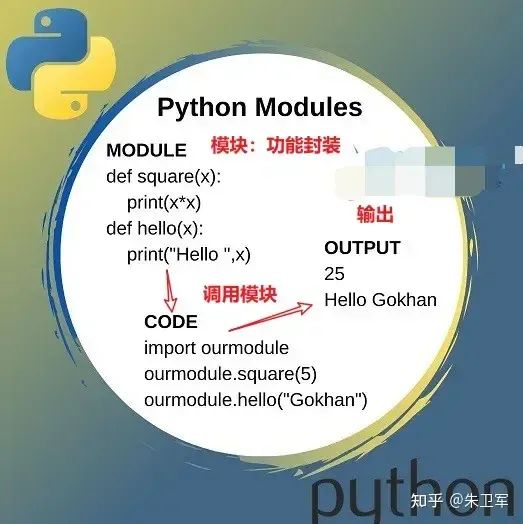
什么是Python模块?
模块是将复杂的、同一应用领域的功能代码进行封装,你只需要调用接口,输入相应参数,便可以轻松拿到结果,类似瑞士军刀、万能工具箱。
常用内置模块,约200多个
内置模块,顾名思义就是Python软件内嵌的模块,无需额外安装。
想要了解详细的内置模块,最好去Python官网看,挺详细的
https://docs.python.org/zh-cn/3/library/index.html
你也可以在代码行输入print(help(modules)),会显示全部的内置模块
这里举几个常用的内置模块,并附上代码:
「math 模块」
用来进行数学计算,它提供了很多数学方面的专业函数,适合科研、算法
import?math
#?计算平方根
sqrt_value?=?math.sqrt(25)
print("Square?Root:",?sqrt_value)
#?计算正弦值
sin_value?=?math.sin(math.radians(30))
print("Sine?Value:",?sin_value)
「re 模块」
正则表达式在Python中的扩展实现,该模块能支持正则表达式几乎所有语法,对于文本处理来说必不可少
import?re
#?查找匹配的字符串
pattern?=?r"\d+"
text?=?"There?are?123?apples?and?456?oranges."
matches?=?re.findall(pattern,?text)
print("Matches:",?matches)
「datetime 模块」
用于处理日期和时间,这个模块非常实用!!!
import?datetime
#?获取当前日期和时间
current_datetime?=?datetime.datetime.now()
print("Current?Date?and?Time:",?current_datetime)
#?格式化日期时间
formatted_datetime?=?current_datetime.strftime("%Y-%m-%d?%H:%M:%S")
print("Formatted?Date?and?Time:",?formatted_datetime)
「urllib 模块」
用于进行网络请求,获取网页HTML,所谓的爬虫就是这个模块
import?urllib.request
#?发起HTTP?GET请求
response?=?urllib.request.urlopen("https://www.example.com")
html?=?response.read()
print("HTML?Content:",?html[:100])
「os 模块」
提供了与操作系统交互的功能,比如文件和目录操作
import?os
#?获取当前工作目录
current_dir?=?os.getcwd()
print("Current?Directory:",?current_dir)
#?列出目录中的文件和子目录
files_and_dirs?=?os.listdir(current_dir)
print("Files?and?Directories:",?files_and_dirs)
「random 模块」
用于生成伪随机数
import?random
#?生成随机整数
random_integer?=?random.randint(1,?10)
print("Random?Integer:",?random_integer)
#?从列表中随机选择元素
random_element?=?random.choice(["apple",?"banana",?"cherry"])
print("Random?Element:",?random_element)
「json 模块」
专门用来处理 JSON 格式数据
import?json
#?将字典转换为?JSON?格式的字符串
data?=?{"name":?"Alice",?"age":?25}
json_string?=?json.dumps(data)
print("JSON?String:",?json_string)
#?将?JSON?格式的字符串转换为字典
parsed_data?=?json.loads(json_string)
print("Parsed?Data:",?parsed_data)
「collections 模块」
提供了一些除list、dict之外有用的数据容器,比如 defaultdict、Counter 等
from?collections?import?defaultdict,?Counter
#?创建默认字典
word_counts?=?defaultdict(int)
words?=?["apple",?"banana",?"apple",?"cherry",?"banana",?"apple"]
for?word?in?words:
????word_counts[word]?+=?1
print("Word?Counts:",?word_counts)
#?统计元素出现的次数
element_counts?=?Counter(words)
print("Element?Counts:",?element_counts)
「csv 模块」
专门用于处理逗号分隔值(CSV)文件
import?re
#?查找匹配的字符串
pattern?=?r"\d+"
text?=?"There?are?123?apples?and?456?oranges."
matches?=?re.findall(pattern,?text)
print("Matches:",?matches)
「sys 模块」
提供了与Python解释器交互的功能,例如访问命令行参数
import?sys
#?获取命令行参数
arguments?=?sys.argv
print("Command-line?Arguments:",?arguments)
常用的第三方模块,十几万个
Python之所以这么受欢迎,很大一部分原因得益于强大的第三方工具生态,几乎各个领域都有对应的模块可以使用。
比如
-
数据科学领域:pandas、numpy、scipy、sympy
-
可视化领域:matplotlib、seaborn、plotly、bokeh、pyecharts
-
机器学习领域:scikit-learn、keras、Tensorflow
-
大数据领域:pyspark、pyflink
-
爬虫领域:requests、scrapy、bs4
-
金融量化领域:ta-lib、zipline、pyfolio
其他各领域都有相应的模块可以使用,这里就不一一列举
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!