架构师进阶,微服务设计与治理的 16 条常用原则
今天将从存储的上一层「服务维度」学习架构师的第二项常用能力 —— 微服务设计与治理。
-
如何设计合理的微服务架构?
-
如何保持微服务健康运行?
这是我们对微服务进行架构设计过程中非常关注的两个问题。
本文对微服务的生命周期定义了七个阶段,如下图所示。

围绕这七个阶段总结了 16 条常用原则。
1、微服务规划
原则 1:按照业务能力(business capabilities)来规划或拆微服务。
康威定律:Conway’s law: Organizations which design systems […] are constrained to produce designs which are copies of the communication structures of these organizations.
(设计系统的组织,其产生的设计和架构等价于组织间的沟通结构。)
组织的沟通和系统的设计之间紧密相连,特别是复杂系统,解决好人与人的沟通才能有一个更好的系统设计。
《人月神话》中总结出了随着人员的增加沟通成本呈指数增长的规律:沟通成本 = n (n-1)/2。举例说明:
-
5 人项目组,需要沟通的渠道是 5*(5–1)/2 = 10
-
15 人项目组,需要沟通的渠道是 15*(15–1)/2 = 105
-
50 人项目组,需要沟通的渠道是 50*(50–1)/2 = 1,225
系统越复杂,人手越多,沟通成本也呈指数增长。因此,分而治之便是大多数公司选择的解决方案。分不同的层级,分不同的小团队,让团队内部完成自治理。
原则 2: 按照领域驱动设计(Domain-Driven Design,DDD)来规划或拆解微服务。
领域驱动设计是微服务领域的热门话题,本文不展开说明,仅说明几点重要事项:
-
基本过程:抽象业务、分析流程、识别边界、建立模型、映射到服务和代码
-
避免过度耦合、存在贫血领域对象等情况
-
划分界限上下文,厘清上下文之间的映射关系,比如合作关系、共享内核、客户方 - 供应方开发、防腐层、开放主机服务等等。
-
细化上下文对象,区分实体、值对象、聚合根、领域服务、领域事件
原则 2 与原则 1 的区别在于,原则 1 关注组织架构领域,原则 2 更偏向软件工程设计领域。
2、微服务设计
原则 3:微服务的设计应该遵循「单一职责」原则
所谓单一职责原则,就是对一个服务而言,它的功能要单一,只做与它相关的事情。在微服务的设计过程中要按职责进行设计,彼此保持正交,互不干涉。
什么样的单一领域对象的单一职责微服务才是有价值的?就是不断有业务变化,能够维持业务持久性,有业务生命力的领域对象。举例来说:
-
与别的功能点相比,调用频率非常高
-
或者其数据量存量大,数据增速快,TB 级甚至是 PB 级的。
那么就很有价值独立为一个微服务,实现独立演进、个性化的弹性伸缩。
所以,我们在进行微服务设计时,要能够分析、预测出需求变化的点在哪里?高并发的点在哪些?数据增长的位置在哪里?与 DDD 分析相结合,找出最有价值的那个单一职责,进行合理、适度的领域、子领域、有界上下文分解,才能更好的应对复杂的业务、不断变化的业务。
原则 4: 微服务的设计应该遵循「高内聚」原则
过度追求「单一职责」,或者拆分微服务过细,往往会带来不良后果。微服务的设计并不是越细越好,过度拆分会导致调用性能变差、数据一致性难以保障、系统可用性降低等问题。
因此,「高内聚」原则要求:
-
完全独立。微服务粒度的下界是它至少应满足独立,能够独立发布、独立部署、独立运行与独立测试
-
足够内聚。强相关的功能与数据在同一个服务中处理
-
足够完备。一个服务包含至少一项业务实体与对应的完整操作
原则 5:微服务的设计应该遵循「低耦合」原则
-
避免数据过度暴露
-
避免数据库共享
-
最小化同步调用,如有必要,引入事件驱动进行异步调用
3、微服务实现
原则 6:服务无状态。
什么是「状态」?如果一个数据需要被多个服务共享,才能完成一笔交易,那么这个数据被称为状态。
依赖这个「状态」数据的服务被称为有状态服务,反之称为无状态服务。
「无状态」原则并不是说在微服务架构里就不允许存在状态,而是要把有状态的业务服务改变为无状态的计算类服务,那么状态数据也就相应的迁移到对应的 “有状态数据服务” 中。

场景说明:例如我们以前在本地内存中建立的数据缓存、Session 缓存,到现在的微服务架构中就应该把这些数据迁移到分布式缓存中存储,让业务服务变成一个无状态的计算节点。迁移后,就可以做到按需动态伸缩,微服务应用在运行时动态增删节点,就不再需要考虑缓存数据如何同步的问题。
只有服务无状态,才能实现快速弹性扩缩容,应对流量峰谷。
原则 7:服务高可用。
接入高可用中间件(如 sentinal),实现限流、熔断、降级,增强可用性
原则 8:服务可观测。
除了默认系统监控外,微服务需要梳理并定义必要的「业务监控指标」。
原则 9:服务配置可管理。
微服务相关配置需要统一接入配置中心进行管理、控制。
4、微服务调用
原则 10:避免「分布式大单体」
只做单向调用,避免循环调用。
多个服务循环依赖调用形成集中式 “分布式大单体”,违背微服务的原则。
原则 11:异步解耦。
按需接入消息队列,实现「依赖解耦」、「流量削峰」
-
串行同步调用异步化,提高响应能力和响应速度
-
应对突发流量,实现流量削峰与流量控制
-
解耦核心业务逻辑不必要的依赖
-
业务设计中的最终一致性
原则 12:引入 BFF 层,降低客户端与后端微服务之间的耦合
尽量设计 BFF 层,把前端的特殊需求交给 BFF 层,使后端服务逻辑具有高内聚、高复用性的精简核心逻辑。
5、微服务发布
原则 13:服务发布遵循安全发布三板斧
保证「可灰度」、「可监控」、「可回滚」。
6、微服务治理
原则 14:正视「架构腐化」,遵循「持续演进」原则
「架构腐化」的常见场景:
-
多人维护一个微服务,出现「频繁代码冲突」,影响快速迭代,那么这个微服务就需要拆分了。
-
当你修改了一个边角的小功能,但是你不敢马上上线,因为你依赖的其他模块才开发了一半,出现大量「功能耦合」,那么这个微服务就需要拆分了。
-
当你发现微服务 A 内聚合 a 的功能变成了海量高频业务。这时聚合 a 就会拖累整个微服务 A,并且因为聚合 a 面临性能瓶颈,在微服务 A 进行弹性扩缩时,也会造成资源浪费。这时,我们就可以将聚合 a 从微服务 A 中整体拆分,独立为一个新微服务 B。在资源配置方面也可以更加有针对性的投入到微服务 B,可以随时满足高频访问的性能要求了。
-
当你发现在领域建模时错误地将聚合 d 放到了微服务 C 里,或者随着业务发展聚合 d 更适合放在微服务 D 里。由于领域模型的不合适,可能会导致微服务之间出现频繁调用,进而导致微服务之间出现「紧耦合关系」。这时,我们就可以对领域模型做出调整,将聚合 d 从微服务 C 整体迁移到微服务 D 里。
原则 15:参考「AKF 扩展立方」模型,服务除了「水平扩容」外,还可以考虑「功能拆分」或者 「数据分区」
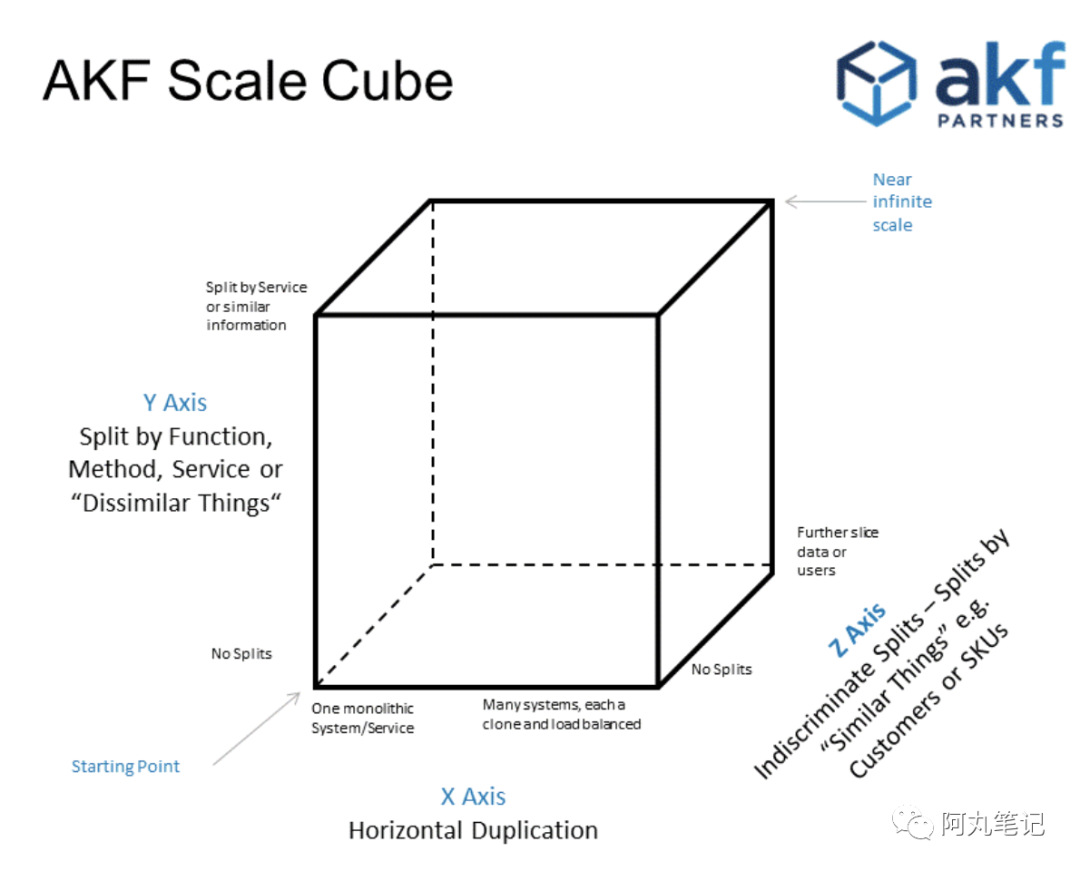
-
X 轴:服务和数据的水平扩容。
-
Y 轴:功能 / 业务拆分
-
Z 轴:沿客户边界的服务和数据分区
「水平扩容」比较容易理解,直白点说就是加机器。根据 AKF 模型,除了加机器外,我们还可以考虑「功能拆分」或者 「数据分区」。
「功能拆分」相对复杂,一般包括几种模式:
-
微服务拆分。根据具体业务模型、领域模型拆分更细粒度的微服务。
-
业务隔离拆分。利用消息队列,将在线业务(OLTP)和耗费大量资源的计算任务拆分隔离。
-
核心与非核心隔离。对于一个微服务,可以将 SKA 客户与普通客户进行隔离,SKA 客户使用独立的集群资源,提高稳定性。
「数据分区」往往指的是数据库层面。需要引入数据库中间件,像 sharding-jdbc、mycat 等,在数据层面需要配置相应的分片逻辑。正确的拆分对提高系统的容量有很大的帮助,失败的拆分可能会造成热点集中,得不偿失。常用的分区逻辑包括 按照时间分区、按照用户 id 取模分区等。
7、微服务下线
原则 16:对于「废弃服务」,需要做好「下线」工作,包括服务下线、存储释放等。
清理无效代码、环境,减少维护成本。同时释放资源,节约成本。
8、总结
架构师在进行微服务设计和微服务治理时,可以围绕微服务生命周期的七个阶段展开。
本文总结了 16 条常用原则,希望能提供一些思路和启发。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!