LRM:单幅图像到三维的大型重建模型
原创 | 文 BFT机器人?

不可否认,从任何物体的单个图像中即时生成3D图像的概念非常吸引人。这一突破有望显著推动工业设计、动画、游戏以及增强现实(AR)和虚拟现实(VR)领域的应用。
此外,在自然语言处理和图像处理方面的显著成就激发了研究人员深入研究学习通用3D基础的领域,以便从单个图像重建对象。

在一篇新论文《LRM: Large Reconstruction Model for Single Image to 3D》中,来自Adobe研究院和澳大利亚国立大学的研究团队介绍了一种创新的大型重建模型(LRM)。这个开创性的模型具有非凡的能力,可以在短短5秒内从单个输入图像中预测物体的3D模型。
LRM方法采用强大的基于transformer的编码器-解码器架构,以数据驱动的方式从单个图像中获取3D对象表示。该模型将图像作为输入,并以三平面表示的形式回归神经辐射场(NeRF)。
为了实现这一点,LRM使用预训练的视觉转换器DINO作为图像编码器来生成图像特征。随后,该算法学习图像到三平面转换器解码器,通过交叉注意力将二维图像特征投射到三维三平面上,通过自注意力有效地模拟空间结构三平面令牌之间的关系。
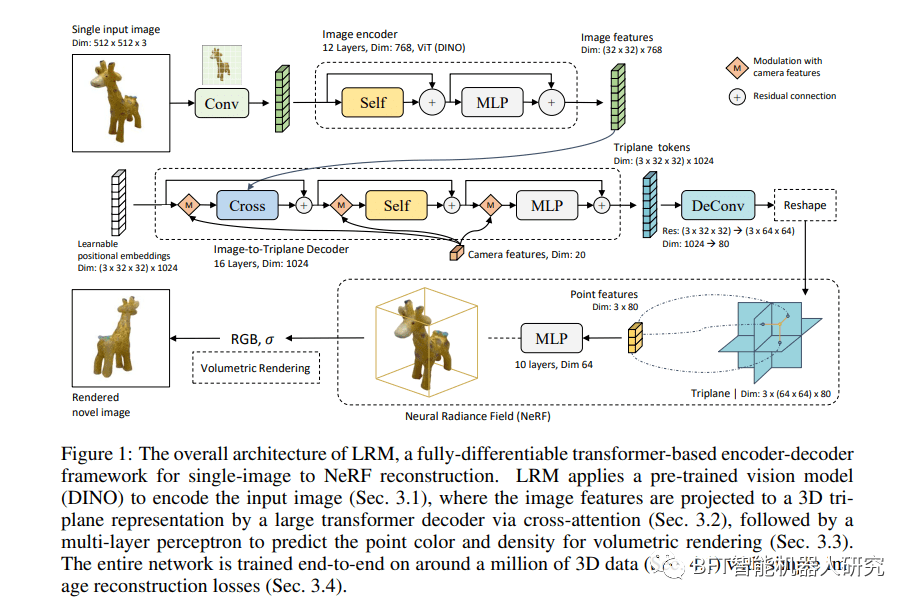
然后,解码器的输出标记被重新调整和上采样,以创建最终的三平面特征图。这使得LRM能够通过解码每个点的三平面特征从任何视点渲染图像。它借助额外的共享多层感知器(MLP)来确定颜色和密度,从而促进体积渲染。
LRM的与众不同之处在于其设计具有很高的可扩展性和效率。
除了采用完全基于变压器的管道外,它采用的三平面NeRF还以简洁且可扩展的3D表示形式脱颖而出。与体积和点云等其他替代方案相比,它的计算效率很高。此外,它相对于输入图像提供了优越的局部性。
LRM的一个显着方面是它的训练过程,它涉及在新颖的视角下最小化渲染图像和地面实况图像之间的差异。这不需要过多的3D感知正则化或复杂的超参数调整即可完成,这使得模型在训练过程中非常高效,并适用于各种多视图图像数据集。

实证结果强调了LRM在处理各种输入时的非凡保真度,包括真实世界的图像、合成创作和具有不同纹理的不同主题的渲染图像。与One-2-3-45相比,它是单图像到3D重建的最先进的解决方案。
总之,这项开创性的工作展示了LRM的潜力,可以从野外发现的单个任意图像中快速预测任何物体的3D模型。这一发展开辟了广泛的实际应用,可以从这种快速准确的3D重建功能中受益。
论文网站:https://arxiv.org/abs/2311.04400
视频演示:https://yiconghong.me/LRM/
若您对该文章内容有任何疑问,请与我们联系,我们将及时回应。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!