[LLM]nanoGPT---训练一个写唐诗的GPT
2023-12-13 15:37:21
原有模型使用的莎士比亚的戏剧数据集, 如果需要一个写唐诗机器人,需要使用唐诗的文本数据,
一个不错的唐诗,宋词数据的下载资源地址:
https://github.com/chinese-poet
这个数据集里面包含搜集到的唐诗,宋词,元曲小说文本数据。
一 数据准备
1. 先下载全唐诗数据,保存到 data/poemtext/tang-poetry下
2. 进行数据的预处理
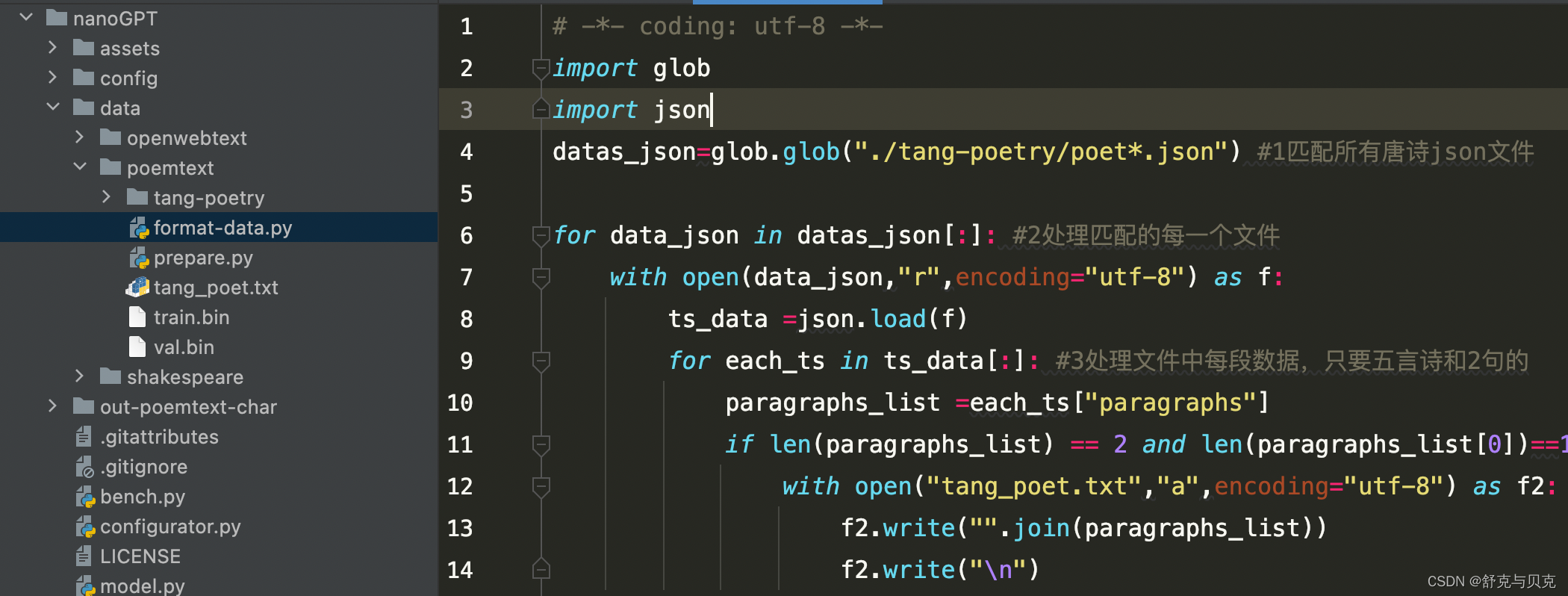
format-data.py
# -*- coding: utf-8 -*-
import glob
import json
datas_json=glob.glob("./tang-poetry/poet*.json") #1匹配所有唐诗json文件
for data_json in datas_json[:]: #2处理匹配的每一个文件
with open(data_json,"r",encoding="utf-8") as f:
ts_data =json.load(f)
for each_ts in ts_data[:]: #3处理文件中每段数据,只要五言诗和2句的
paragraphs_list =each_ts["paragraphs"]
if len(paragraphs_list) == 2 and len(paragraphs_list[0])==12 and len(paragraphs_list[1]) == 12:
with open("tang_poet.txt","a",encoding="utf-8") as f2:
f2.write("".join(paragraphs_list))
f2.write("\n")
f =open("tang_poet.txt","r",encoding="utf-8")
print(len(f.readlines()))prepare.py
import os
import requests
import tiktoken
import numpy as np
# download the tiny shakespeare dataset
input_file_path = os.path.join(os.path.dirname(__file__), 'tang_poet.txt')
with open(input_file_path, 'r') as f:
data = f.read()
n = len(data)
train_data = data[:int(n*0.9)]
val_data = data[int(n*0.9):]
# encode with tiktoken gpt2 bpe
enc = tiktoken.get_encoding("gpt2")
train_ids = enc.encode_ordinary(train_data)
val_ids = enc.encode_ordinary(val_data)
print(f"train has {len(train_ids):,} tokens")
print(f"val has {len(val_ids):,} tokens")
# export to bin files
train_ids = np.array(train_ids, dtype=np.uint16)
val_ids = np.array(val_ids, dtype=np.uint16)
train_ids.tofile(os.path.join(os.path.dirname(__file__), 'train.bin'))
val_ids.tofile(os.path.join(os.path.dirname(__file__), 'val.bin'))
二 配置文件准备
参考? ?train_shakespeare_char.py

三 开始训练
参考? ?train_shakespeare_char.py
# mac pro m1机器上 python3 train.py config/train_poemtext_char.py --device=mps --compile=False --eval_iters=20 --log_interval=1 --block_size=64 --batch_size=12 --n_layer=4 --n_head=4 --n_embd=128 --max_iters=1000 --lr_decay_iters=1000 --dropout=0.0

四 生成唐诗
python3 sample.py --out_dir=out-poemtext-char --device=mps
参考:
文章来源:https://blog.csdn.net/zwqjoy/article/details/134971216
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!