HBase-架构与设计
一、背景
HBase是一个基于java的NoSQL分布式列存储数据库,主要用于存储非结构化和半结构化的松散数据。将Hadoop中的HDFS作为底层文件存储系统,来提供容错和可靠性,以及存储系统的拓展性。
HBase的设计思想来自Google的Bigtable论文,是分布式数据库的实现。HDFS是一个高可靠、高延迟的分布式文件系统,但是不支持对数据的随机访问和更新,因此不适合实时计算系统。HBase是一个可以提供实时计算的大数据分布式数据库,支持对数据的随机访问和更新。
二、HBase概述
HBase的底层存储引擎是基于LSM-Tree数据结构设计的,存储是基于HDFS。而针对数据的更新和删除,不是修改原有记录而是新增一条记录,这样可以充分发挥顺序写的性能,但是查询的时候就需要查询磁盘中的文件和内存中的操作,读取所有数据版本。因此HBase写性能比读性能提高了两个数量级。
1.设计特点
- 强一致性读写:HBase时强一致性读写,适合高速计数聚合之类的任务。
- 自动分片:HBase表会按照水平方向拆分成Region分布在集群上,Region会随着数据增长自动拆分和重新均衡。
- 故障转移:RegionServer如果发生故障会自动恢复
- 集成HDFS:HBase内部集成HDFS作为其持久化存储组件
- 支持MapReduce:HBase支持MapReduce进行大规模并行处理,支持写入和读取。
- 查询优化:HBase通过块缓存和布隆过滤器来优化大容量查询
2.适用场景
2.1 海量数据
传递RDRMS当数据量增大时,需要读写分离策略来解决服务器压力。如果数据量继续增加就需要分库分表,这就限制了一些关联查询并引入中间层。每次变动都需要很多准备工作和业务代码修改验证。而且即使分库分表也无法解决一些数据倾斜和热点问题。HBase支持自动水平拓展,内部集成HDFS解决数据可靠性,还支持利用MapReduce进行海量数据分析。
2.2 稀疏数据
HBase作为列式存储适合稀疏数据,针对为null的列不会进行存储,这样可以节约存储空间并提高读性能。
2.3 多版本数据
HBase的更新和删除操作不会修改原有记录而是通过新增记录实现。通过RowKey和ColumnKey定位到多个TimeStamp相关的Value值,因此可以存储变动历史记录。可以通过设置版本数量,来确定HBase保留几次变动记录。
2.4 半结构或者非结构化数据
HBase无固定模式,不需要停机进行维护,支持半结构和非结构化的数据。
三、数据模型
作为一个面向列的分布式数据库,存储的数据是稀疏、多维、有序的。HBase表中的一条数据是由全局唯一的键(RowKey)和任意数量的列(Column),一列或者多列组成一个列族(Column Family)。
其中列族名和数量需要在建表确定,但一个列族下面可以增加任意个列限定名。一个列限定名代表了实际中的一列,HBase将同一个列族下面的所有列存储在一起,所以HBase是一种面向列族式的数据库。
1.表逻辑结构
以下是一个HBase表的实例。其中有一个唯一主键,包含PersonalInfo列族、其中包括三个列name、age、phone;包含OfficeInfo列族、其中包括列tel和city。并且根据时间戳TimeStamp会存储多版本数据。
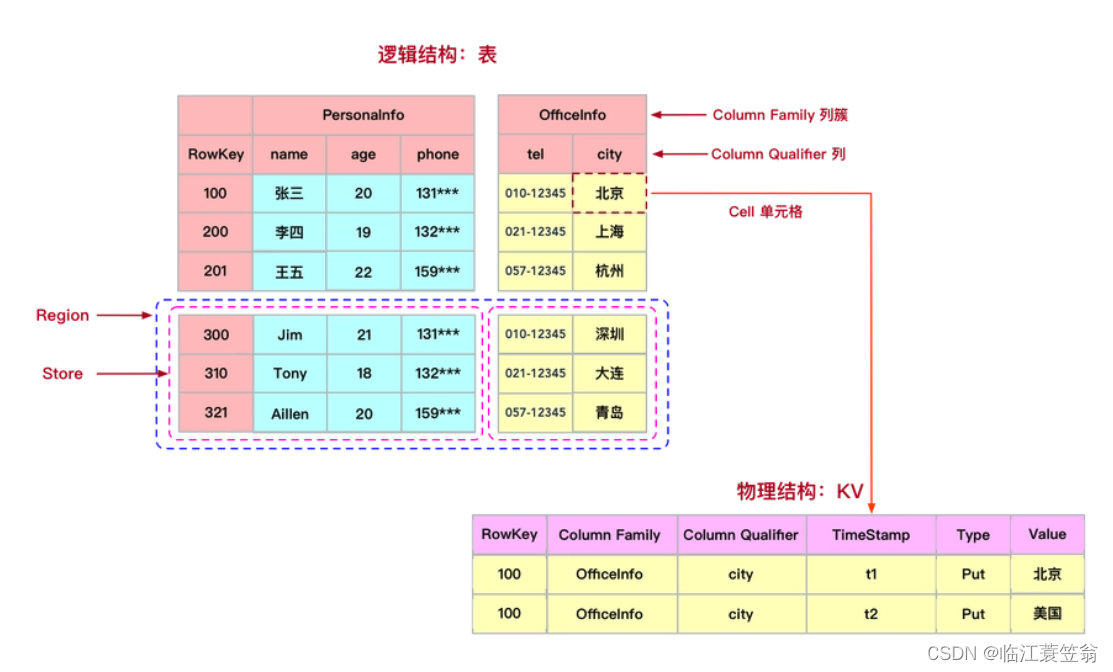
2.RowKey
RowKey与关系型数据库中的主键类似,用来唯一标识某行数据。整个表是按照RowKey进行排序。HBase按照RowKey划分为多个Region存储在不同的Region Server上,可以分布式对表进行存储和读取。
3.Column Family
Column Family是列族,一个列族可以包含多列。同一个列族中列数据都存储在Region的一个Store中。
4.TimeStamp
TimeStamp 是实现 HBase 多版本的关键。在HBase 中,使用不同 TimeStamp 来标识相同RowKey对应的不同版本的数据。
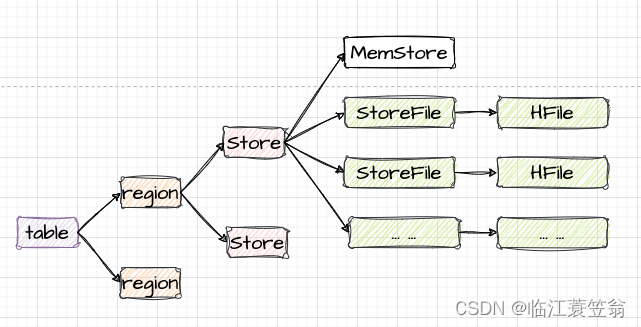
5.存储结构
HBase表根据主键水平拆分成多个region,每个region根据列族拆分为Store,每个Store包含一个内存MemStore和零个或者多个StoreFile,StoreFile以HFile文件形式存储在HDFS上。
HBase表的存储结构如下图:
四、HBase架构图
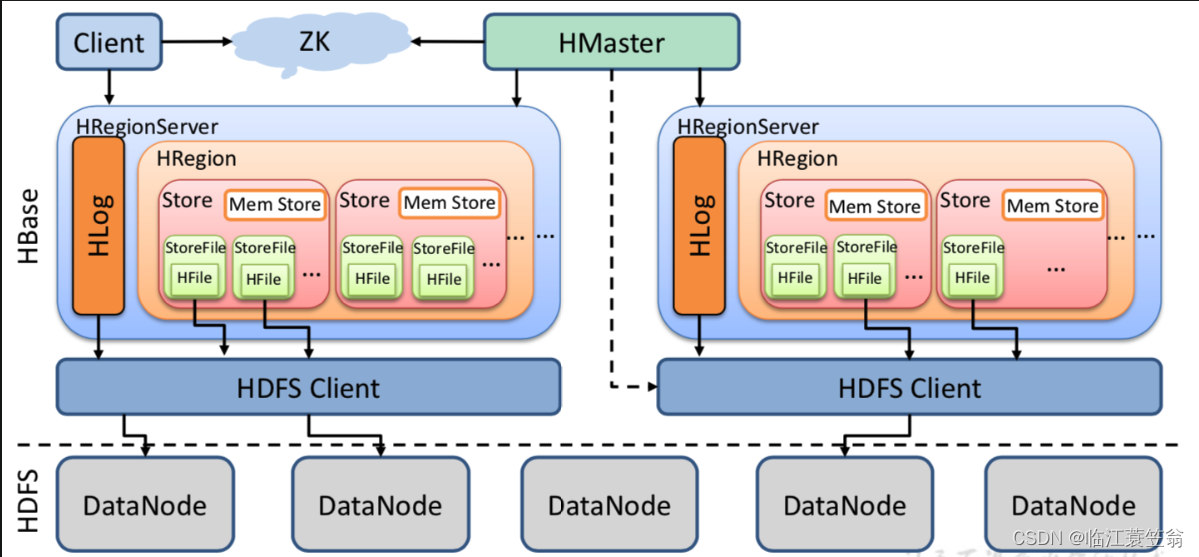
HBase采用Master/Slave架构搭建集群,属于Hadoop生态系统的一部分。由HMaster节点、HRegionServer节点、Zookeeper集群组成,而数据会存储在HDFS中。整体架构如下图:
对HBase架构组成的每一个部分介绍如下。
1.Client
用户访问HBase的客户端,主要是包含HBase的接口,会缓存元数据来加快对HBase的访问。
2.Zookeeper
Zookeeper主要协调和管理HMaster和HRegionServer。HMaster和HRegionServer启动时会向Zookeeper进行注册。作用如下:
- 保证任何时候,集群中只有一个HMaster。
- 存储所有HRegion的寻址入口。
- 实时监控HRegionServer的上线和下线信息,并通知给HMaster
- 存储HBase的Schema和Table元数据
3.HMaster
负责管理RegionServer并实现负载均衡,管理和分配Region,管理namespace和table元数据。
4.HRegionServer
用来维护HMaster分配的region,处理这些region的读写请求,并且负责将运行过程中过的region进行切分。
5.HRegion
Region是HBase中分布式存储和负责均衡的最小单位。HBase表按照行方向被拆分为多个Region。不同的Region可以分布在不同的HRegionServer上,同一个Region只能在同一个HRegionServer上。当Region的某个列族达到一定阀值会被拆分成两个新的Region。
6.Store
每个Region按照ColumnFamily拆分成Store,一个Region由一个或者多个Store组成。每个ColumnFamliy会建一个Store,一个Store由一个memStore和多个StoreFile组成。
7.StoreFile
memStore中的数据写到文件之后就是StoreFile。StoreFIle底层就是HFile的格式保存在存储系统中。
8.HLog
记录数据的所有变更和操作日志,用来故障恢复。当Region Server出现故障,可以通过HLog恢复数据
五、元数据存储
1.元数据表
HBase中有一个系统表hbase:meta来存储HBase元数据。该表保存了所有的Region信息,hbase:meta也是一个HBase表被HRegionServer管理,hbase:meta表的位置信息保存在Zookeeper中。
2.数据结构
元数据表有一个RowKey和一个ColumnFamily组成,其中RowKey包括表名、起始Key、region编号。只包含一个info列族,包含三列:
- info:regioninfo:regionId,tableName,startKey,endKey,offline,split,replicaId;
- info:server:HRegionServer对应的server:port;
- info:serverstartcode:HRegionServer的启动时间戳。
六、写流程
HBase的写入过程由于相当于添加新记录,因此写数据比读数据快,整体流程如下:
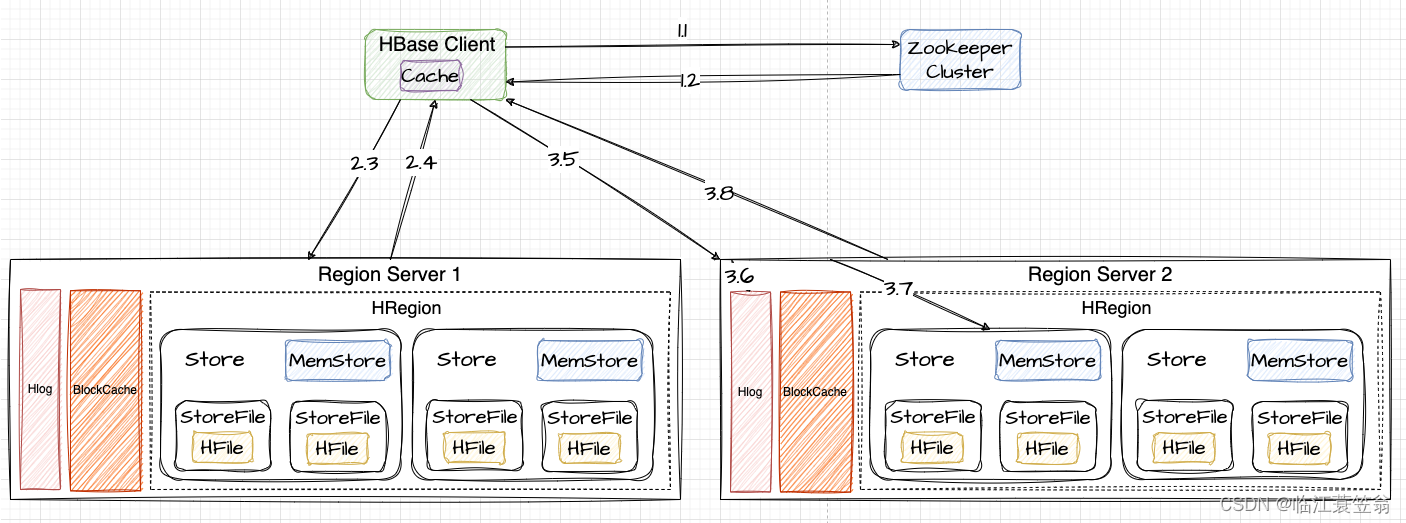
1.获取Meta元数据
首先需要知道表的元数据,也就是要知道表的region列表,这个信息时维护在meta表中。
1.1 client访问zookeeper获取Meta表所在的RegionServer信息
1.2 从zookeeper节点返回meta的RegionServer1信息
2.获取RegionServer
从Meta表中查询表的Region信息以及负责Region维护的RegionServer信息。
2.3 根据表名和RowKey向meta所在的RegionServer1发送查询请求
2.4 RegionServer1找到对应的meta的记录,返回对应Region信息,其中包括RegionServer2信息。Client会缓存此Region信息。
3.发送写入请求
向RegionServer2发送写请求。
3.5 向Region所在的RegionServer2发送写请求
3.6 RegionServer2将数据先写入到HLog,为了数据的持久化和恢复
3.7 RegionServer2将数据写入到MemStore。
3.8 RegionServer2返回给Client告知写入成功。
七、读流程
HBase读取数据需要返回所有版本数据,所以可能需要查询所有HFile文件,读性能比写慢了两个数量级。读取流程获取Meta元数据和RegionServer的过程和写过程一致。
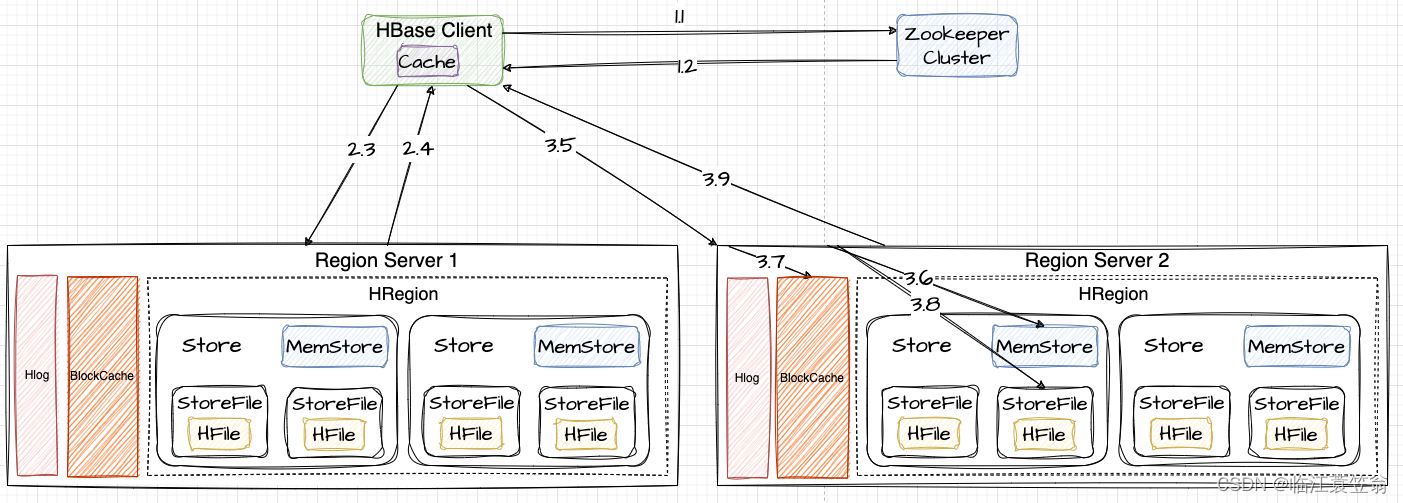
1.获取Meta元数据
跟写过程一致
2.获取RegionServer
跟写过程一致
3.发送读请求
向RegionServer2发送写请求。
3.5 向Region所在的RegionServer2发送写请求
3.6 先在MemStore进行查找
3.7 如果MemStore没有,则需要在BlockCache中查找
3.8 如果BlockCache没有,则需要在StoreFile上查找
3.9 如果StoreFile查到到数据,需要将数据写入到BlockCache,再返回给Client。
八、持久化
1.恢复机制
上边的写请求过程可知,数据会先写入到HLog,然后再写入到内存MemStore。
- HLog保存的是RegionServer上所有的日志操作,是记录操作的一种日志。当MemStore数据还没有持久化时,可以通过HLog进行故障恢复,保证数据正确性和持久化。
- MemStore是在内存中维持列族数据按照RowKey顺序排列,然后顺序写入到磁盘中。主要是为了将来检索优化,将数据写入到HDFS之前在内存中将数据完成排序。
2.MemStore 刷盘
MemStore维持当前在内存中的同一个列族数据按照RowKey有序,当MemStore达到一定时机时会将MemStore中数据以HFile形式持久化到文件系统中。Flush触发条件如下:
2.1 Memstore级别限制
当Region中任意一个MemStore的大小达到了上限(hbase.hregion.memstore.flush.size,默认128MB),会触发Memstore刷新
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
</property>
2.2 Region级别限制
当Region中所有Memstore的大小总和达到了上限(hbase.hregion.memstore.block.multiplier * hbase.hregion.memstore.flush.size,默认 2* 128M = 256M),会触发memstore刷新
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
</property>
<property>
<name>hbase.hregion.memstore.block.multiplier</name>
<value>4</value>
</property>
2.3 Region Server级别限制
当一个Region Server中所有Memstore的大小总和超过低水位阈值hbase.regionserver.global.memstore.size.lower.limit*hbase.regionserver.global.memstore.size(前者默认值0.95),RegionServer开始强制flush
<property>
<name>hbase.regionserver.global.memstore.size.lower.limit</name>
<value>0.95</value>
</property>
<property>
<name>hbase.regionserver.global.memstore.size</name>
<value>0.4</value>
</property>
- 先Flush Memstore最大的Region,再执行次大的,依次执行;
- 如写入速度大于flush写出的速度,导致总MemStore大小超过高水位阈值,此时RegionServer会阻塞更新并强制执行flush,直到总MemStore大小低于低水位阈值
2.4 HLog数量上限
当一个Region Server中HLog数量达到上限(可通过参数hbase.regionserver.maxlogs配置)时,系统会选取最早的一个 HLog对应的一个或多个Region进行flush
2.5 定期刷新Memstore
默认周期为1小时,确保Memstore不会长时间没有持久化。为避免所有的MemStore在同一时间都进行flush导致的问题,定期的flush操作有20000左右的随机延时。
2.6 手动flush
用户可以通过shell命令flush ‘tablename’或者flush ‘region name’分别对一个表或者一个Region进行flush。
3.HFile 合并
memstore每次刷新都会生成一个新的HFile文件,由于触发机制导致可能生成的大部分新HFile文件都是小文件。这样会导致查询过程中需要遍历非常多的小文件,导致维护困难、影响查询性能和效率。为了查询优化和清理过期数据,所以会对HFile进行合并。Compaction分为两类:Minor Compaction和Major Compaction。
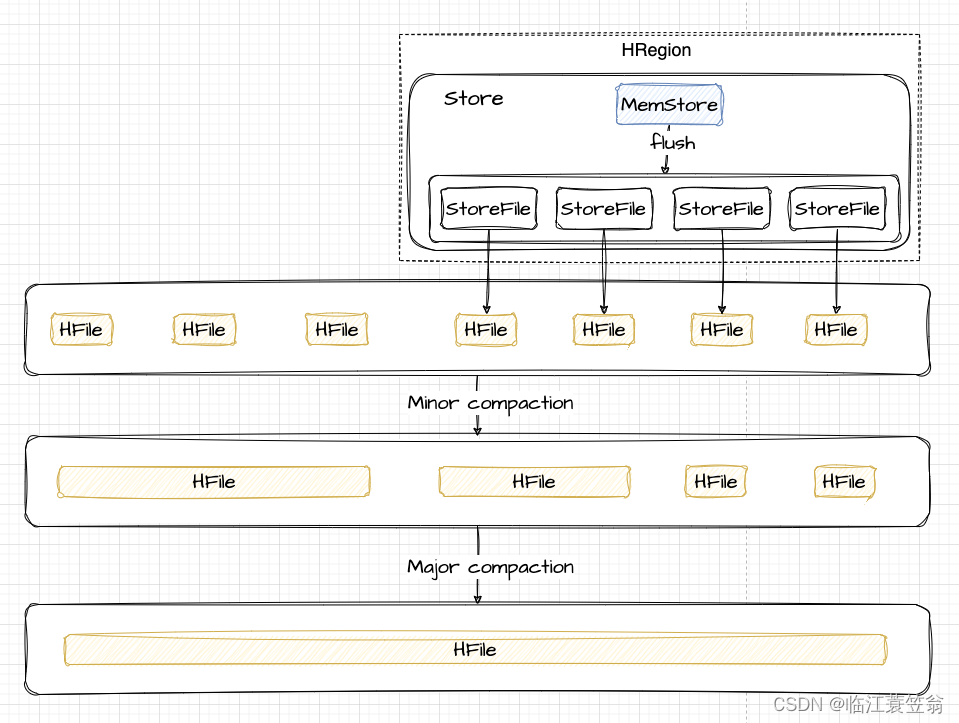
3.1 合并原理
合并原理是指从一个Store中的部分HFile文件整合成一个新的HFile文件,其中会从待合并数据从文件读出,然后按照由小到达排序后写入新文件。
3.2 Minor Compaction
选取部分小的相邻的HFile,将他们合并成一个更大的HFile。
3.3 Major Compaction
将一个Store中所有的HFile合并成一个HFile。同时会清理掉过期、删除、多版本数据。
总结
HBase是基于分布式文件系统HDFS构建的一个大数据、NoSQL、可拓展分布式数据库。采用Master/Slave架构、用Zookeeper进行元数据保存和协调工作。采用LSM-TREE作为存储引擎,由于HDFS不支持修改和更新,所以HBase中将修改和更新作为新记录存储到HDFS中。HBase用牺牲读性能来提升大数据写入能力。
参考链接
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!