系列五、DQL
一、DQL
1.1、概述
? ? ? ? DQL的英文全称为:Data Query Language,中文意思为:数据查询语言,用大白话讲就是查询数据。对于大多数系统来说,查询操作的频次是要远高于增删改的,当我们去访问企业官网、电商网站,在这些网站中我们所看到的数据,实际都是需要从数据库中查询并展示的。而且在查询的过程中,可能还会涉及到条件、排序、分页等操作,所以为了提高我们业务系统的响应速度,还是很有必要熟练掌握DQL语言的。
1.2、查询的基本语法
SELECT
? ? 字段列表
FROM
? ? 表名列表
WHERE
? ? 条件列表
GROUP BY
? ? 分组字段列表
HAVING
? ? 分组后条件列表
ORDER BY
? ? 排序字段列表
LIMIT
? ? 分页参数1.3、条件查询
1.3.1、常见的比较运算符

1.3.2、常见的逻辑运算符

1.4、聚合函数
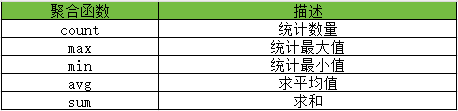
1.4.1、概述
? ? ? ? 聚合函数用于将一列数据作为一个整体,进行纵向计算的场景。
1.4.2、常见的聚合函数
1.4.3、语法
SELECT 聚合函数(字段列表) FROM 表名 ;
注意 : NULL值是不参与所有聚合函数运算的。
1.5、数据初始化
use vhr;
drop table if exists employee;
DROP TABLE IF EXISTS `employee`;
CREATE TABLE `employee` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`work_no` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '工号',
`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '姓名',
`gender` char(1) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '性别',
`age` int NULL DEFAULT NULL COMMENT '年龄',
`id_card` char(18) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '身份证号',
`work_address` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '工作地址',
`entry_date` date DEFAULT NULL COMMENT '入职日期',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '用户表' ROW_FORMAT = DYNAMIC;
?
INSERT INTO `employee`(`work_no`, `name`, `gender`, `age`, `id_card`, `work_address`, `entry_date`)
VALUES
('00001', '柳岩666', '女', 20, '123456789012345678', '北京', '2000-01-01'),
('00002', '张无忌', '男', 18, '123456789012345670', '北京', '2005-09-01'),
('00003', '韦一笑', '男', 38, '123456789712345670', '上海', '2005-08-01'),
('00004', '赵敏', '女', 18, '123456757123845670', '北京', '2009-12-01'),
('00005', '小昭', '女', 16, '123456769012345678', '上海', '2007-07-01'),
('00006', '杨逍', '男', 28, '12345678931234567X', '北京', '2006-01-01'),
('00007', '范瑶', '男', 40, '123456789212345670', '北京', '2005-05-01'),
('00008', '黛绮丝', '女', 38, '123456157123645670', '天津', '2015-05-01'),
('00009', '范凉凉', '女', 45, '123156789012345678', '北京', '2010-04-01'),
('00010', '陈友谅', '男', 53, '123456789012345670', '上海', '2011-01-01'),
('00011', '张士诚', '男', 55, '123567897123465670', '江苏', '2015-05-01'),
('00012', '常遇春', '男', 32, '123446757152345670', '北京', '2004-02-01'),
('00013', '张三丰', '男', 88, '123656789012345678', '江苏', '2020-11-01'),
('00014', '灭绝', '女', 65, '123456719012345670', '西安', '2019-05-01'),
('00015', '胡青牛', '男', 70, '12345674971234567X', '西安', '2018-04-01'),
('00016', '周芷若', '女', 18, null, '北京', '2012-06-01')1.6、统计函数案例
1.6.1、统计employee表中员工的数量
select count(*) from `employee`;?? ?-- 结果16
select count(1) from `employee`;?? ?-- 结果16
select count(id) from `employee`;?? ?-- 结果16
select count(`id_card`) from `employee`;?? ?-- 结果15题外话:count(*) VS count(1) VS count(id) VS count(`id_card`)?
1.6.2、统计employee表中员工的平均年龄
select avg(age) from employee;?
1.6.3、统计employee表中员工的最大 & 最小年龄?
select max(age) from employee;
select min(age) from employee;
1.6.4、统计employee表中西安员工的年龄之和
select sum(age) from employee where work_address = '西安';
1.7、 分组函数案例
1.7.1、语法
SELECT?
? ? 字段列表?
FROM?
? ? 表名?
[ WHERE 条件 ]?
GROUP BY?
? ? 分组字段名?
[ HAVING 分组后过滤条件 ];
1.7.2、where与having的区别
(1)执行时机不同: where 是分组之前进行过滤,不满足 where 条件,不参与分组;而 having 是分组 之后对结果进行过滤。
(2)判断条件不同: where 不能对聚合函数进行判断,而 having 可以。
? ? ? ??
注意事项:
? ? ? ? ? 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
? ? ? ? ? 执行顺序: where > 聚合函数 > having 。
? ? ? ? ? 支持多字段分组 , 具体语法为 : group by columnA,columnB
1.7.3、根据性别分组?,?统计男性员工和女性员工的数量
select gender, count(*) from employee group by gender ;
1.7.4、?根据性别分组?,?统计男性员工和女性员工的平均年龄
select gender,avg(age) from employee group by gender;
1.7.5、查询年龄小于45的员工?,?并根据工作地址分组?,?获取员工数量大于等于3的工作地址
select work_address,count(*) as 'empNumber' from employee where age < 45 group by work_address HAVING empNumber >= 3;
1.7.6、统计各个工作地址上班的男性及女性员工的数量
select work_address,gender, count(*) from employee group by work_address,gender;
1.8、排序查询
语法:select <column1,column2,column3,...>?from <tableName> order by <column1> desc;
asc(默认):升序
desc:降序
说明:比较简单,不再演示。
1.9、分页查询案例
1.9.1、语法?
语法:SELECT 字段列表 FROM 表名 LIMIT 起始索引 , 查询记录数 ;
注意事项 :
????????? 起始索引从 0 开始,起始索引 = (查询页码 - 1 ) * 每页显示记录数。
????????? 分页查询是数据库的方言,不同的数据库有不同的实现, MySQL 中是 LIMIT 。
????????? 如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 10 。
1.9.2、 查询employee表中第一页的数据,每页展示10条
select * from employee limit 10;
1.9.3、查询employee表中第二页的数据,每页展示10条?
select * from employee limit 10,10;
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!