AI | 大模型推理参数解析(进行中)
控制模型输出Logits的参数
temperature
用于控制模型输出的结果的随机性,这个值越大随机性越大。一般我们多次输入相同的prompt之后,模型的每次输出都不一样。
- 设置为 0,对每个prompt都生成固定的输出
- 较低的值,输出更集中,更有确定性
- 较高的值,输出更随机(更有创意 )
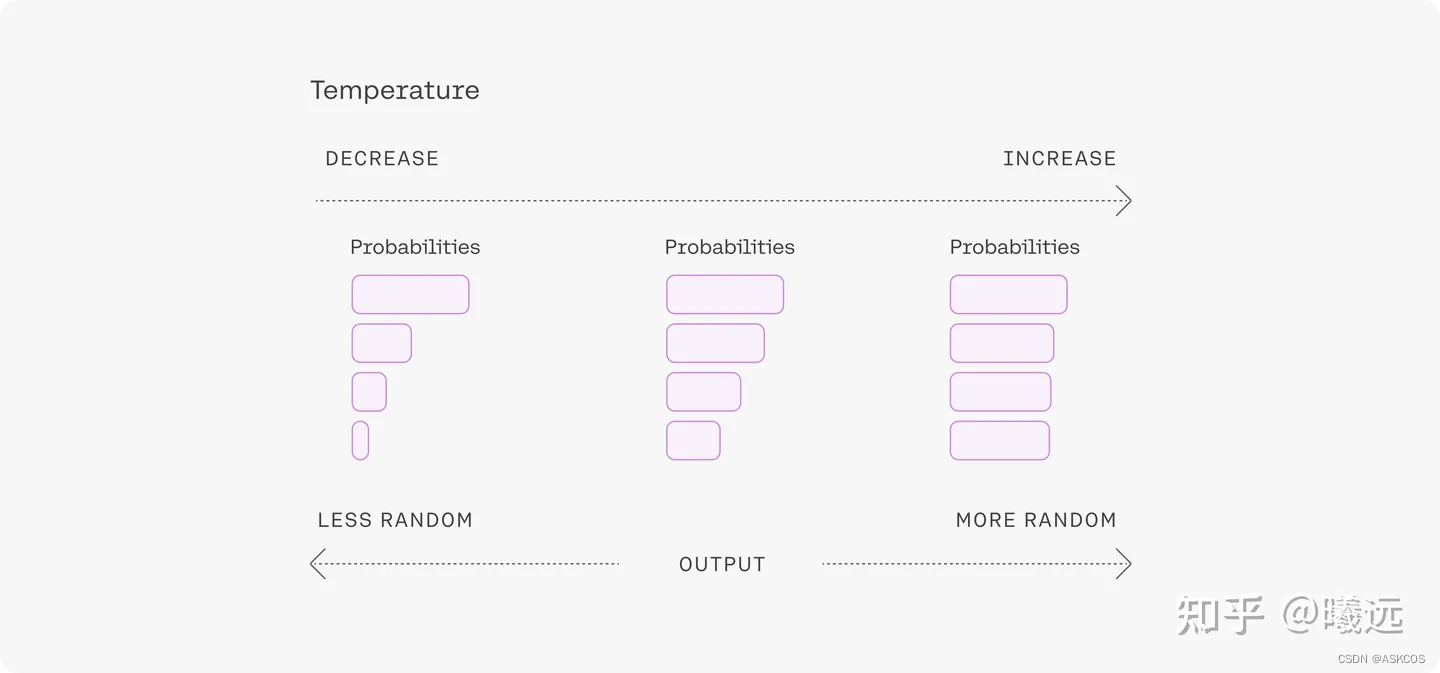
一般来说,prompt 越长,描述得越清楚,模型生成的输出质量就越好,置信度越高,这时可以适当调高 temperature 的值;反过来,如果 prompt 很短,很含糊,这时再设置一个比较高的 temperature 值,模型的输出就很不稳定了。
https://zhuanlan.zhihu.com/p/631786282
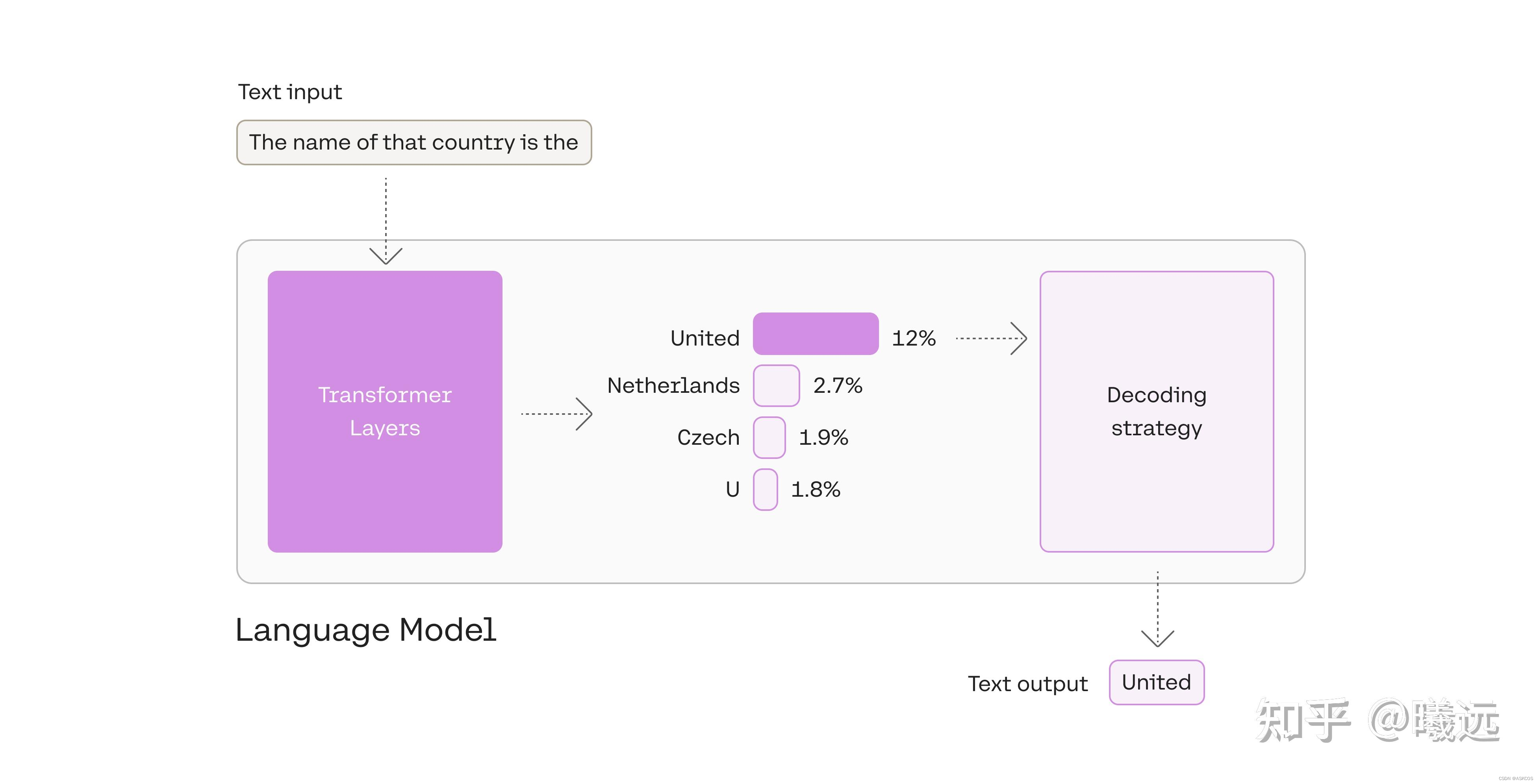
top_k
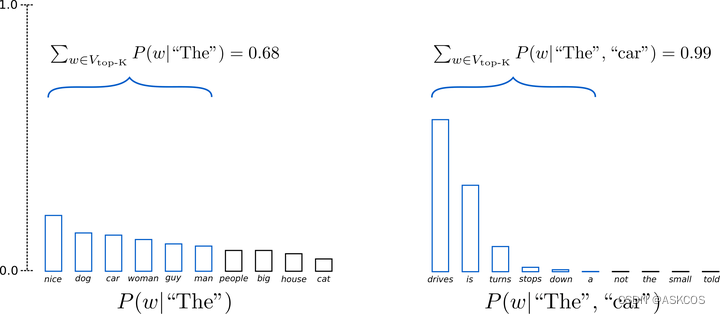
这个参数比较简单,简单来说就是用于在生成下一个token时,限制模型只能考虑前k个概率最高的token,这个策略可以降低模型生成无意义或重复的输出的概率,同时提高模型的生成速度和效率。
top_p
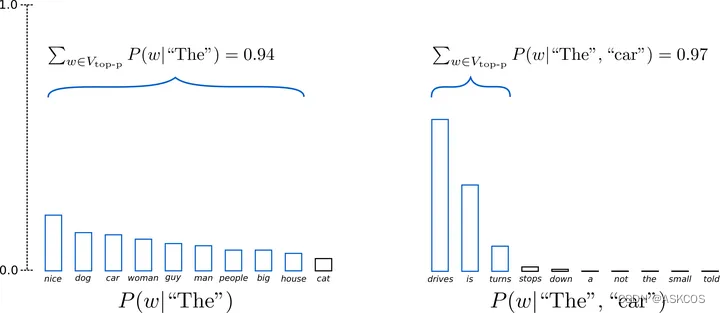
已知生成各个词的总概率是1(即默认是1.0)如果top_p小于1,则从高到低累加直到top_p,取这前N个词作为候选。
这里可能会有一点疑问,当top-p设置的很小,累加的概率没超过怎么办?一般代码中都会强制至少选出一个token的。注:top_p=1时表示不使用此方式。
控制输出策略的参数
do_sample
(bool, optional, defaults to False)
是否使用采样,否则使用贪婪解码 。
generate默认使用贪婪的搜索解码,所以你不需要传递任何参数来启用它。这意味着参数num_beams被设置为1,do_sample=False。
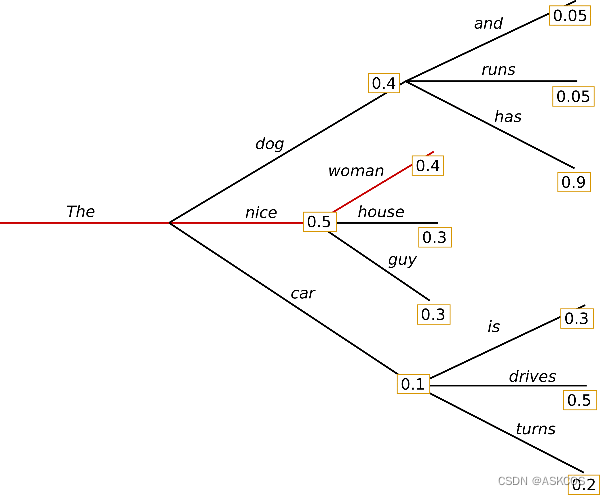
如图上所属,每次选择概率值最高的词。贪心搜索的主要缺点是它错过了隐藏在低概率词后面的高概率词,比如has=0.9不会被选择到。
https://zhuanlan.zhihu.com/p/624845975
控制输出长度的参数
max_length
(int, optional, defaults to 20) - 生成的tokens的最大长度。对应于输入提示的长度
+max_new_tokens。如果还设置了max_new_tokens,则其作用被max_new_tokens覆盖。
max_new_tokens
(int, optional) - 要生成的最大数量的tokens,忽略提示中的tokens数量。
min_length
(int, optional, defaults to 0) - 要生成的序列的最小长度。对应于输入提示的长度+min_new_tokens。如果还设置了min_new_tokens,它的作用将被 min_new_tokens覆盖。
min_new_tokens
(int, optional) - 要生成的最小数量的tokens,忽略提示中的tokens数量。
early_stopping
(bool or str, optional, defaults to False) - 控制基于beam-based的停止条件,比如beam-search。是否在至少生成 num_beams 个句子后停止 beam search,默认是False。
max_time
(float, optional) - 你允许计算运行的最大时间,以秒为单位。在分配的时间过后,生成仍然会完成当前的传递。
定义generate输出变量的参数
num_return_sequences
(int, optional, defaults to 1) - 批次中每个元素独立计算的返回序列的数量。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!