Linux之缓冲区的理解
目录
一、问题引入
我们先来看看下面的代码:我们使用了C语言接口和系统调用接口来进行文件操作。在代码的最后,我们还使用fork函数创建了一个子进程。

?代码运行结果如下:

结果没有什么问题啊?结果很正确。但是我们再来看看下面的操作:我们对其进行输出重定向。然后,查看log.txt的代码。
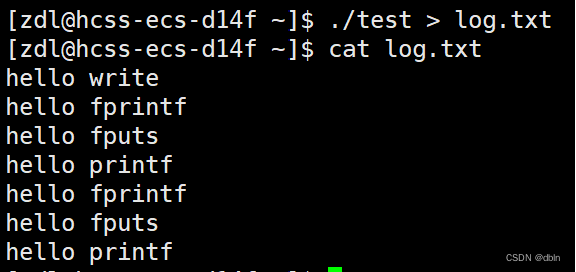
我们惊奇地发现,文件里面的内容和打印到显示器的内容是不一样的!我们再仔细观察,发现,C语言的函数都打印了两次,而系统调用接口只打印了一次。为什么呢??
这种现象就和fork函数以及我们下面要讲的缓冲区有关了。
二、缓冲区
1、什么是缓冲区
缓冲区的本质就是一段内存空间。
我们知道,内存的速度比磁盘的速度快了几个数量级。所以数据如果直接从内存写到磁盘,那么访问外设效率比较低,那就太消耗时间了。所以缓冲区的意义就是通过减少与外设的IO次数,来节省进程进行数据IO的时间。
所以C语言中就提供了缓冲区。而有了缓冲区的存在,可以提高整机效率,并提高用户的响应速度。
2、刷新策略
~ 立即刷新。
~ 行刷新(行缓冲)。(常见的对显示器进行数据刷新)以\n为标志
~ 满刷新(全缓冲)。(常见的对磁盘文件写入数据)
特殊情况:1、用户强制刷新(fflush)? ? ? ? ? 2、进程退出
注:所有的设备,永远都倾向于全缓冲,即缓冲区满了才刷新,因为这样只需要更少的IO操作,更少次的外设访问,效率更高。
当然,我们要根据实际情况去改变刷新策略。如:显示器是直接给用户看的,一方面要照顾效率,一方面要照顾用户体验。所以显示器一般使用行刷新。
3、缓冲区由谁提供
从上面的例子,我们发现直接往显示器上打印的结果为4条,往文件打印的结果为7条,这跟缓冲区有关,同时这也说明了缓冲区一定不在Linux内核中,为什么?因为write是系统接口,如果在内核中,write也应该打印两次。所以缓冲区是由C标准库提供的。
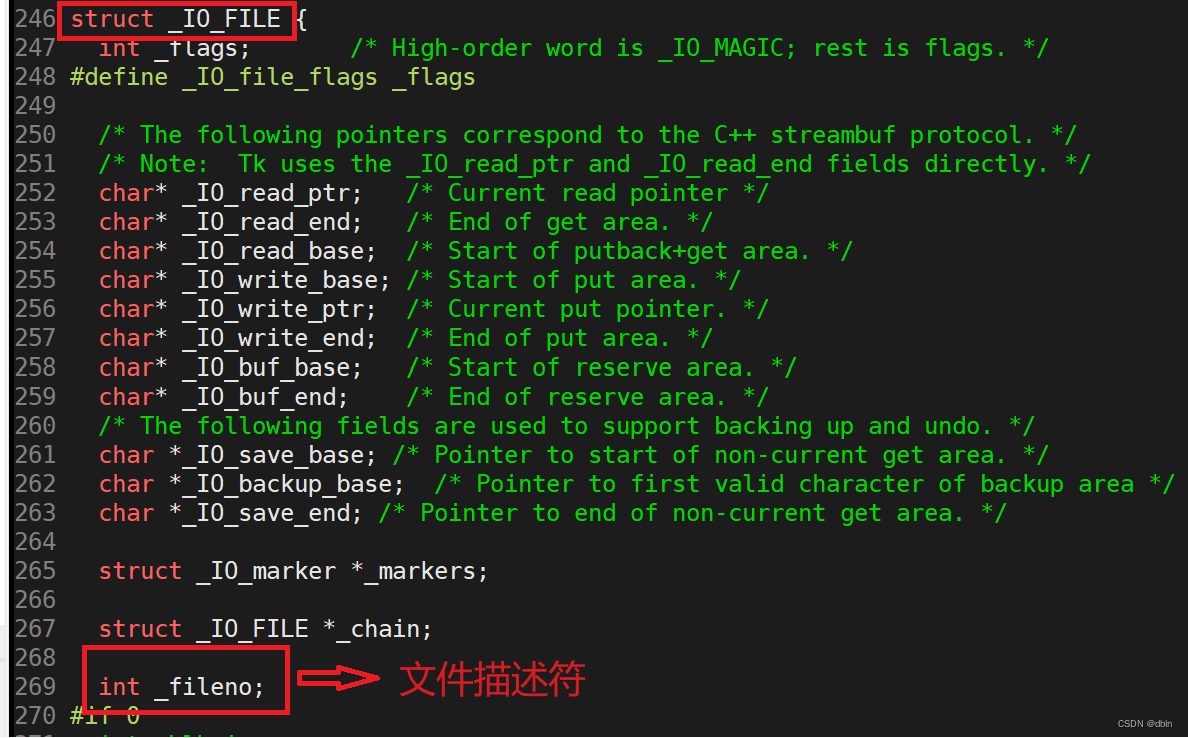
我们之前所说的所有缓冲区都指的是用户级语言层面提供的缓冲区。stdout,stdin,stderr对应的类型——FILE*,FILE是一个结构体,里面封装了fd,同时还包括了一个缓冲区。
从源码出发,我们可以来看一看FILE结构体:
4、重看问题
有了缓冲区的概念,我们就来解释解释问题引入中的现象。
首先,我们要先知道,代码运行完了,并不代表数据已经刷新了。上面代码中,使用C语言函数的操作在执行完了后,先将数据写入了缓冲区中,并没有直接向显示器上打印。
第一次运行,没有重定向操作,就是直接向显示器打印,而显示器的刷新策略是行刷新,且每个代码后面都有\n,所以在调用fork之前,代码不仅执行完了,而且数据都已经刷新了。所以fork对结果没有影响。
第二次运行,我们有了重定向操作,于是函数就由向显示器打印变成了向磁盘文件打印。所以刷新策略也由行刷新变成了满刷新。那么\n就已经没有意义了。所以代码在运行到fork时,之前的代码虽然已经运行完成了,但是数据还没有刷新到文件中。数据还在当前进程对应的C标准库中的缓冲区中,且该数据属于父进程。
于是最后,我们fork创建了子进程。接着,父进程或子进程退出,这时数据会强制刷新出来。我们假设父进程先退出:父进程退出后,其数据强制刷新,而刷新的过程也是一种写入,所以这时,为了父子进程的数据不会相互影响,就会发生写时拷贝!这样数据就会有两份,于是父子进程各自退出时都会刷新各自的数据。(当然,如果子进程先退出也是同样的)
所以,简单总结来说:重定向导致刷新策略发生了改变(由行缓冲变成了全缓冲)。同时发生了写时拷贝,父子进程各自刷新。
三、缓冲区的简单实现
有了缓冲区的一些基本概念。我们可以自己实现一个简单的带有缓冲区的struct file。
主函数:
int main
{
MyFILE* fp = fopen_("log.txt", "r");
if(fp==NULL)
{
printf("open file fail");
return 0;
}
fputs_("hello world", fp);
fclose_(fp);
return 0;
}struct file
struct MyFILE_
{
int fd;
char buff[NUM];
int end;//当前缓冲区的结尾
};
typedef struct MyFILE_ MyFILE;?fopen函数的简单实现
MyFILE* fopen_(const char* pathname, const char* mode)
{
assert(pathname);
assert(mode);
MyFILE* fp = NULL;
if(strcmp(mode, "w")==0)
{
int fd = open(pathname, O_WRONLY|O_TRUNC|O_CREAT);
if(fd>0)
{
MyFILE* fp=(MyFILE*)malloc(sizeof(MyFILE));
memset(fp,'\0',sizeof(MyFILE));
fp->fd = fd;
}
}
else if(strcmp(mode, "w+")==0)
{}
else if(strcmp(mode,"r")==0)
{}
else if(strcmp(mode,"r+")==0)
{}
else if(strcmp(mode,"a")==0)
{}
else if(strcmp(mode,"a+")==0)
{}
else
{}
return fp;
}fputs函数的简单实现
void fputs_(const char* message, MyFILE* fp)
{
assert(message);
assert(fp);
strcpy(fp->buff+fp->end, message);
fp->end += strlen(message);
if(fp->fd==0)
{}
else if(fp->fd==1)
{
if(fp->buff[fp->end-1]== '\n')
{
write(fp->fd, fp->buff,fp->end);
fp->end = 0;
}
}
else if(fp->fd==2)
{}
else
{}
}fclose函数简单实现和fflush函数
void fclose_(MyFILE* fp)
{
assert(fp);
fflush_(fp);
close(fp->fd);
free(fp);
}
void fflush_(MyFILE* fp)
{
assert(fp);
if(fp->end != 0)
{
write(fp->fd, fp->buff, fp->end);
syncfs(fp->fd);
fp-> end = 0;
}
}本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!