mysql使用全文索引+ngram全文解析器进行全文检索
表结构:表名? gamedb? ?主键? id? ?问题类型? type? 问题??issue? 答案?answer
需求
现在有个游戏资料库储存在mysql中,客户端进行搜索,需要对三个字段进行匹配,得到三个字段的相关性,选出三个字段中相关性最大的值进行排序,以此获取相关性最高的数据。如以上表,用户搜索的问题是 “如何获得更多游戏积分?”,然后我需要在(type,issue,answer)三个字段里面进行匹配,找到和这个问题相关性最高的数据。
思路
使用MySQL全文检索进行关键词搜索并按相关性得分排序的查询语句。本人mysql版本5.7.24
mysql全文检索,对mysql版本有什么要求?
- 从MySQL 5.6版本开始,InnoDB存储引擎开始支持全文索引。而在MySQL 5.7版本之后,通过使用ngram插件开始支持中文全文索引。在MySQL 5.7.6之前,全文索引只支持英文全文索引,不支持中文全文索引。
- 对于MySQL 5.6版本之前,只有MyISAM存储引擎支持全文索引,而从MySQL 5.6版本开始,InnoDB和MyISAM均支持全文索引。
- 需要注意的是,MySQL的全文索引对中文的支持存在一定限制,因此在实际应用中可能需要采用其它方案去替代。
ngram全文分析器
什么是ngram?
ngram是全文解析器能够对文本进行分词,中文分词用 ngram_token_size 设定分词的大小,ngram_token_size 的值就是连续n个字的序列
示例:使用ngram对于全文索引进行分词ngram_token_size =1,分词为 ‘全‘,’文‘,’索‘,’引‘
ngram_token_size =2,分词为 ‘全文‘,’文索‘,’索引‘
ngram_token_size =3,分词为 ‘全文索‘,’文索引‘
ngram_token_size =4,分词为 ‘全文索引‘
如何查看配置ngram_token_size?
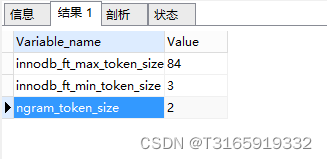
#查看默认分词大小 ngram_token_size=2 show variables like '%token%';查询结果
????????
innodb_ft_min_token_size
默认3,表示最小3个字符作为一个关键词,增大该值可减少全文索引的大小
innodb_ft_max_token_size
默认84,表示最大84个字符作为一个关键词,限制该值可减少全文索引的大小
ngram_token_size
默认2,表示2个字符作为内置分词解析器的一个关键词,如对“abcd”建立全文索引,关键词为’ab’,‘bc’,‘cd’
当使用ngram分词解析器时,innodb_ft_min_token_size和innodb_ft_max_token_size 无效
怎么配置ngram?
1、ngram可以作为启动字符串的一部分或者在配置文件中设置
启动字符串:mysqld --ngram_token_size=22、配置文件(my.ini):
以windos系统为例,首先找到my.ini文件(默认安装路径:C:\ProgramData\MySQL\MySQL Server 5.7\my.ini),编辑该文件,在文件后加上如下配置:# 设置mysql客户端默认字符集 default-character-set=utf8 [mysqld] #设置3306端口 port = 3306 server_id=100 # 设置mysql的安装目录 basedir=D:\mysql-5.7.24-winx64 # 设置mysql数据库的数据的存放目录 datadir=D:\mysql-5.7.24-winx64\data # 允许最大连接数 max_connections=200 # 服务端使用的字符集默认为8比特编码的latin1字符集 character-set-server=utf8 # 创建新表时将使用的默认存储引擎 default-storage-engine=INNODB # 全文检索分词数 ngram_token_size=2配置完成后重启服务
如何创建全文索引并且使用ngram?
1、通过建表语句建立
?CREATE TABLE `full_search_test` ( `id` int unsigned NOT NULL AUTO_INCREMENT, `author` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL, `title` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL, `content` text COLLATE utf8mb4_general_ci, PRIMARY KEY (`id`), FULLTEXT KEY `full_index_title` (`title`) WITH PARSER `ngram` ) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci2、通过 alter table 的方式来添加
ALTER TABLE full_search_test ADD FULLTEXT INDEX full_index_title(title) WITH PARSER ngram;3、直接通过create index的方式
#为title创建全文索引并且使用ngram全文解析器进行分词 CREATE FULLTEXT INDEX full_index_title ON full_search_test(title) WITH PARSER `ngram`;
实际案例
-
创建表?
CREATE TABLE gamedb (
id INT AUTO_INCREMENT PRIMARY KEY,
type VARCHAR(255),
issue VARCHAR(255),
answer VARCHAR(255)
);-
为type、issue和answer字段创建全文索引?
CREATE FULLTEXT INDEX gamedb_index_type ON gamedb(type); CREATE FULLTEXT INDEX gamedb_index_issue ON gamedb(issue); CREATE FULLTEXT INDEX gamedb_index_answer ON gamedb(answer);
检测这三个字段?
SELECT *,
(MATCH(type) AGAINST('我喜欢扩展包包')) AS score_type,
(MATCH(issue) AGAINST('我喜欢扩展包包')) AS score_issue,
(MATCH(answer) AGAINST('我喜欢扩展包包')) AS score_answer
FROM gamedb
WHERE MATCH(type) AGAINST('我喜欢扩展包包') OR
MATCH(issue) AGAINST('我喜欢扩展包包') OR
MATCH(answer) AGAINST('我喜欢扩展包包');
缺点
n-gram分词是一种基于统计的分词方法,它将文本按照n个连续的词为单位进行切分。虽然n-gram分词在很多应用中表现良好,但也存在一些缺点:
歧义处理困难: n-gram分词无法处理词汇歧义,因为它只考虑了相邻词汇之间的关系,而没有考虑上下文的语境。在一些语境下,同一个词可能有不同的含义,而n-gram分词无法准确捕捉这种语境。
未考虑词序信息: n-gram分词方法忽略了词汇之间的具体顺序信息,只考虑了相邻词的组合。然而,在自然语言中,词汇的排列顺序对于理解文本意义非常重要,而n-gram分词无法很好地捕捉这种词序信息。
数据稀疏性: 随着n的增大,n-gram模型需要更多的训练数据来准确地估计参数,但在实际应用中,获得大规模标注数据并不总是容易。这会导致模型对于较长的n-gram组合的泛化能力下降。
词汇变化问题: 对于一些具有词形变化、时态变化等特性的语言,n-gram分词可能面临词汇变化导致的困扰。例如,动词的不同时态形式可能被认为是不同的n-gram,导致模型难以正确处理这种变化。
无法处理未知词汇: n-gram模型无法处理未在训练数据中出现的词汇,因为它们在统计信息中没有相应的记录。对于生僻词、新词或专业名词等,n-gram分词可能表现较差。
效率问题:n-gram分词需要构建和维护大规模的n-gram模型,这可能导致内存消耗较大,并且在处理大量文本时可能会导致较慢的分词速度。
最后没有采纳这种方法,由于ngram分词不怎么灵活,不同的分词大小可能会在分词结果和性能方面有所差异。较小的n值(如2-gram)可能更适合处理短语和常见词语,而较大的n值(如4-gram)可能更适合处理长词和特定领域的术语。这里只是记录一下使用方法.........
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!