计算机体系结构流水线学习记录
一、知识点汇总
1.理想情况下,流水线能够实现 n 倍的吞吐率加速比(n为流水线深度),但是流水线深度并非越大越好,因为流水线的深度会影响到性能和功耗之间的平衡。
2.RISC:Reduced Instruction Set Computer(精简指令集计算机);
CISC:Complex Instruction Set Computer(复杂指令集计算机);
RISC更加有利于流水线的实现,RISC的典型代表是MISPS。
RISC特点:对数据的所有操作都应用于寄存器中的数据,通常会更改整个寄存器;影响内存的唯一操作是将数据从内存移动到寄存器或从寄存器移动到内存的加载和存储操作;指令格式的数量很少,所有指令通常都是一个大小。
RISC的三类指令:
3.RISC中每条指令最多执行五个周期:
| 周期 | 名称 | 操作 |
| 1 | IF (Instruction fetch) |
?
发送
PC
到内存单元,取回下一条指令;
?
更新
PC=PC+4
,为取下一条指令做准备。
|
| 2 | ID (Instruction decode/register fetch) |
?
根据指令中的源操作数标识符,从寄存器文件中读取源操作数;
?
对读取的源操作数进行比较,以为可能的跳转做准备;
?
对指令中的偏移量进行符号扩展,以防可能用到;
?
计算可能的跳转目的地址。
|
| 3 | EX (Execution/effective address) |
?
对于访存指令:将基址寄存器和偏移量相加形成访存地址;
?
寄存器
-
寄存器运算指令:对读取的
2
个源操作数执行指定操作;
?
寄存器
-
立即数运算指令:对读取的第一个源操作数和立即数执行指定的操作。
|
| 4 | MEM (Memory access) |
?
Load
:使用前一个周期计算出的访存地址读取内存;
?
Store
:将数据写入由前一个周期计算出的访存地址指向的内存。
|
| 5 | WB (Write back) |
?
对于寄存器
-
寄存器运算指令和
load
指令:将结果写入寄存器文件。
|
?
?
?

五个周期并行执行,其性能将是非流水线处理器的5倍;
ID取指,ID指令解码,EX执行,EME内存访问,WB写回。
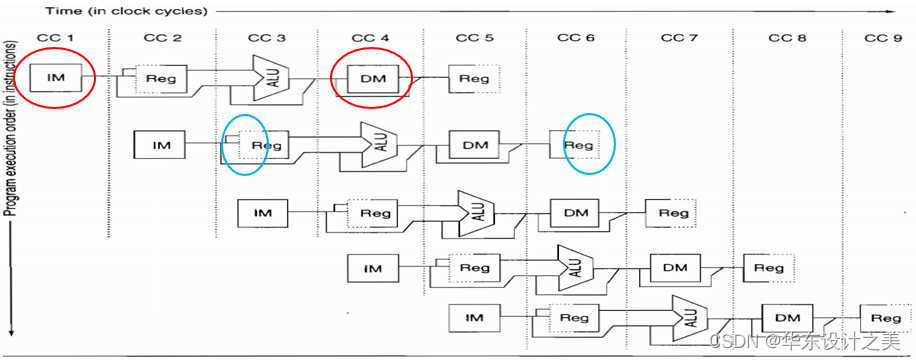
指令存储器的缩写是IM,数据存储器的缩写是DM,时钟周期的缩写是CC;
同时为了防止两相邻指令间的相互干扰,会在边缘增加寄存器特性。
指令流水线的两个主要性能指标:
CPI(Clock cycles Per Instruction)即每条指令所需的时钟周期数:在一个理想的流水线中,CPI=1。实际上,因为多种因素的影响,CPI会大于1;
CR(Clock Rate)时钟频率是指指令流水线每秒钟执行的时钟周期数。
MIPS(Millions of Instructions Per Second)=CR/CPI
影响流水线性能的几个因素:对CR的影响,时钟的运行速度要以最慢管道阶段所需的时间为准;流水线的控制开销,时钟偏移,时钟到达任意两个寄存器之间的最大延迟,主要影响CR;指令间的各种冲突(hazard)导致的流水线停顿(stall),对CPI和CR都有影响。
4.数据依赖指令间存在依赖关系,核心特征就是指令间具有数据流动,存在数据依赖的指令必须顺序执行,不能乱序,也不能完全并行;
名字依赖分为反向依赖(后续指令需要读取前导指令的正确值)和输出依赖(两条相邻指令写入共同的寄存器或内存位置),需要注意,其核心特征为指令间不存在数据流动,可以通过重命名技术消除;
控制依赖至一条指令同一条分支指令之间的相关性,这种相关性要求指令只能在应当被执行时才被执行(和分支指令绑定)。
依赖关系是程序的属性,不依运行它的CPU的结构设计而转移。
5.冲突的发生一般源于硬件无法支撑并发指令产生组合而导致的资源冲突;
冲突的成因有两个方面:部分功能部件没经过充分流水化,连续使用部件导致每周期一条长期占据端口;部分功能部件没有足够的端口,使用同一寄存器却只有一个写端口,导致资源冲突。
资源冲突只能靠停顿来解决。
数据冲突分为RAW(read after write)先读取写入结果,在写入寄存器,对应输出依赖;WAW(write after write)在写入指令前写入上一条指令,对应输出依赖;WAR(write after read)在读取指令前先写入上一条指令,对应反向依赖;
WAW/WAR冲突仅会在乱序执行流水线中出现
控制冲突是指分支指令带来的PC取值的不确定性,若不能妥善处理,控制冲突将会导致停顿时间变长,且分支指令的比例变高。

增加流水线的级数可以提高性能,但是会导致流水线控制开销,功耗增加,增加停顿,拉低性能;因此,降低Ideal CPI和各种stalls是提升性能的主要方向。
6.解决冲突的方法:
结构冲突:停顿;
数据冲突:前送(forwarding/bypassing);计分板;Tomasulo;
控制冲突:延迟槽(delayed slot);分支预测(branch prediction);高级分支预测(correlating branch predictors, tournament predictors);跳转地址预测(branch target buffers) ;返回地址预测(return address predictors)。
例如前送(forwarding/bypassing)是用来解决RAW冲突的,核心思想是将结果产生后第一时间送到需要他的功能部件里(一般是ALU也有可能是DM),而不是寄存器文件来传递;需要注意,数据要前送回去,多路输入要有一个选通器,且需要一个冲突检测电路来控制选通器。

而当load stall产生时,由于结果产生太晚,无法通过前送完全消除停顿。
为了解决上述问题,可引入stall,增加停顿来消除冲突,核心思想:软硬件协同;

| 时钟周期 | 操作 | |
| IF (Instruction fetch) | IR←Mem[PC]; NPC←PC+4; | |
| ID (Instruction decode/register fetch) | A←Regs[rs]; B←Regs[rt]; Imm←sign-extended immediate field of IR; | |
| EX (Execution/effective address) | Memory reference | ALUOutput←A+Imm; |
| Register-register ALU | ALUOutput←A func B; | |
| Register-immediate ALU | ALUOutput←A op Imm; | |
| Branch | ALUOutput←NPC+(Imm<<2); Cond←(A==0) | |
| MEM (Memory access/branch completion) | Memory reference | LMD←Mem[ALUOutput] or Mem[ALUOutput]←B; |
| Branch | if (Cond) PC←ALUOutput; | |
| WB (Write back) | Register-register ALU | Regs[rd]←ALUOutput; |
| Register-immediate ALU | Regs[rt]←ALUOutput; | |
| Load | Regs[rt]←LMD; | |
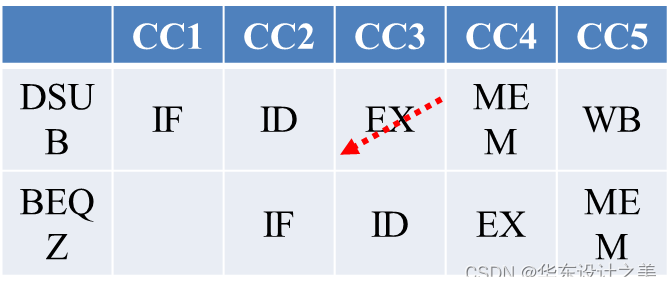
7.由于分支指令会导致3个周期的停顿,因此MEM阶段才会将目标地址写入PC;
冲突检测的目的:检测流水线中会导致停顿的数据冲突,保证流水线正确执行;而一般基本的五阶段流水线中,不存在资源冲突、WAR冲突和WAW冲突,控制冲突可通过延迟槽解决,普通的RAW冲突可通过前送解决,因此唯一会导致停顿的冲突是与Load相关的RAW冲突;
时机:当消费指令处在ID阶段时进行检测(此时相应的load指令一定处在EX阶段);
停顿的实现:将ID/EX寄存器清零(即向后传递一个空操作),同时保持住IF/ID寄存器的内容。

?8.分支处理
MIPS流水线中,控制冲突可以通过延迟槽消除。但这有一个条件:分支条件判定及目的地址计算必须在ID阶段完成,否则延迟槽指令之后的下一条指令仍不清楚从哪里取。为此,需要在ID阶段增加一个加法器和一个比较器;
但这也会带来一个问题:如果分支指令数据依赖于前一条指令,则会导致一个无法避免的停顿。
例如:
DSUB R1,R1,#8
BEQZ R1, LOOP
资源冲突可能存在(除法部件未流水化,多条指令同时到达WB阶段);
WAW冲突可能存在(WAR不可能存在);
RAW冲突更常见。
二、习题解答:
问题1.考虑以下代码片段:
Loop:?????? LD????????? R1, 0(R2)?????? ; load R1 from address 0+R2
?????????????? DADDI??? R1, R1, #1???? ; R1=R1+1
?????????????? SD????????? R1, 0(R2)?????? ; store R1 at address 0+R2
?????????????? DADDI??? R2, R2, #4???? ; R2=R2+4
?????????????? DSUB???? R4, R3, R2???? ; R4=R3-R2
?????????????? BNEZ????? R4, Loop??????? ; branch to Loop if R4!=0假设R3的初始值是:R2+396.
????????a.列出以上代码中的所有数据依赖。针对每个依赖,列出相关寄存器、源指令(即产生数据的指令)和目的指令(即消费数据的指令)。例如,源指令LD到目的指令DADDI存在关于寄存器R1的依赖关系。
答:

????????b.以时序图画出以上指令在5-阶段RISC流水线中的执行时序。假设流水线没有实现前送逻辑(forwarding),寄存器文件可以在一个周期内完成一次读和一次写,跳转指令通过清空整条流水线来处理,访存操作只需一个周期即可完成。以上代码需要执行几个周期?
答:
由于R4=R3-R2,而R2循环加4,因此R3每次减4,而循环结束条件为R4等于零,结合R3初值为396,因此需要396/4=99个循环,因此为99个循环,而每个循环需要18周期(对最后一个),而对前面的98个循环而言,每个循环的最后两个周期被迭代了,因此总周期数为98*16+18=1586个。

?????????c.假设流水线实现了完善的前送逻辑,其它条件不变,重新画出以上指令在5-阶段流水线中的执行时序,并计算整个代码序列需要执行几个周期?
答:
(补充:具体来说,当流水线启动时,首先执行一段“incorrect instruction”,以确保流水线中的所有部件都处于正确的状态。这段“incorrect instruction”本身并不会对程序的结果产生影响,因为它是不正确的指令。执行完这段指令后,流水线就可以正常地执行后续的指令了。)
由于前送完善后所进行的数据编译并不需要等待数据传入,将会直接将数据送入ALU,因此在部分指令中可进行直接ID,而incorrect instruction注释则在上述补充中完善。

问题2.设分支指令占全部指令的比例如下:
条件跳转:??? ????????????? 15%
无条件跳转:????????????? 2%
并假设,条件跳转指令中,60%发生了跳转。
????????a.假设有一条4阶段流水线,其中,无条件跳转指令在第二个周期的末尾执行完毕,条件跳转指令在第三个周期的末尾执行完毕,同时只有第一阶段不受分支指令目的地址的影响,也不存在其它因素造成的停顿。请分析,对于这样一条流水线,如果完全消除控制冲突,它能够加速多少?
答:
首先流水化带来的加速比可用下列式子计算:
因此,sppedup=
因此在理想情况下加速比为(1/(1+0))*4=4,不考虑冲突带来的停顿
(注意,由于是第二个周期末尾,因此是(2-1)个stall,后续是第三个周期末尾为(3-1)个stall,而untaken则又少了一个stall,则为(3-1-1)个stall)

????????b.假设有另一条15阶段的高性能流水线,其中,无条件跳转指令在第五个周期的末尾执行完毕,条件跳转指令在第十个周期的末尾执行完毕,其它条件不变,请分析,对于这样一条流水线,如果完全消除控制冲突,它能加速多少?
答:(注意,由于是第二个周期末尾,因此是(5-1)个stall,后续是第三个周期末尾为(10-1)个stall,而untaken则又少了一个stall,则为(10-1-1)个stall)
整体思路如上题

?
问题3.假设有一台非流水化的计算机
它的时钟周期是7ns。在将它改造成5-阶段流水线计算机后,各阶段的执行时间分别是:IF:1ns;ID:1.5ns;EX:1ns;MEM:2ns;WB:1.5ns,同时,流水线寄存器引入的延时为0.1ns。
????????a.改进后计算机的时钟周期是多少ns?
????????b.假如每4条指令有一个停顿,改进后计算机的CPI是多少?
????????c.改进后的计算机,加速比有多少?
a题中正是由于FDXMW这五个过程中最大的过程为MEM的2ns,而系统延时是无法避免的,因此最大时钟周期为2.1ns;
b题中为4+1个周期,而只有四条指令,则为5周期/4指令=1.25;
c题中由于程序执行时间为=IC*CPI*ClockTime,而IC为相同的,可以相消因此为(1*7)/(1.25*2.1)=2.67

问题4.假设有一台采用计分板算法的计算机
考虑以下代码序列:
?????????????? MUL.D??? F0, F6, F4
?????????????? DSUB.D? F8, F0, F2
?????????????? ADD.D??? F2, F10, F2
假设MUL.D的Execute阶段需要三个周期,DSUB.D和ADD.D的Execute需要一个周期,其它阶段都只需要一个周期。同时假设处理器有2个乘法部件,2个加法部件。
????????a.假设MUL.D指令在第一个周期完成了发射,请在下表中标出每条指令的每个阶段的执行周期数(一直标到出现首个停顿为止)。
????????b.对于停顿的指令,在对应的列上标出它是从哪个周期开始等待的,并在说明栏中说明冲突的类型,和它在等待哪条指令。
????????c.对于停顿的指令,在对应的列上标出它是在哪个周期执行完毕的,并在说明栏说明是什么事件恢复了停顿指令的执行。
????????d.重复b)、c),直到将整个表格填写完毕。
| Instruction | Issue | Read Oprands | Execuet | Write Result | Comment |
| MUL.D F0,F6,F4 | 1 | 2 | 3,4,5 | 6 | |
| DSUB.D F8,F0,F2 | 2 | 7 | 8 | 9 | 从第三个周期开始等待MUL.D写出结果,一直等到第六个周期末 |
| ADD.D F2,F10,F2 | 3 | 4 | 5 | 8 | 从第六个周期开始等待DSUB.D读取F2,知道第七个周期末 |
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!