超越MJ:PixArt-α超低成本,高质量文生图创新模型
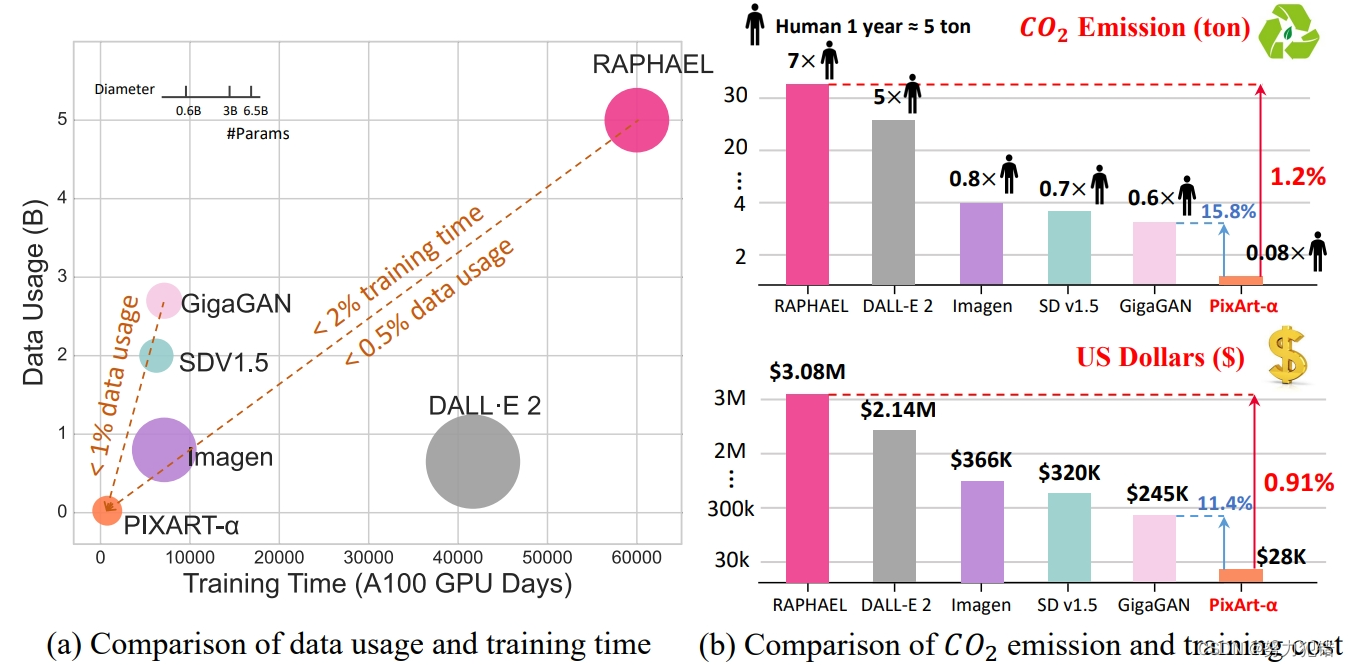
近年来,人工智能的发展使得文本到图像(T2I)技术日益成熟,但同时也伴随着高昂的训练成本。然而,华为诺亚方舟实验室等机构最近提出的PixArt-α模型,打破了这一局限。PixArt-α能够以极低的成本(仅26000美元)在相对短时间内(约675 A100 GPU 天)完成训练,相比传统的大型T2I模型,如RAPHAEL,大幅降低了成本。
-
huggingface模型下载:https://huggingface.co/PixArt-alpha/PixArt-XL-2-1024-MS
-
AI快站模型免费加速下载:https://aifasthub.com/models/PixArt-alpha/PixArt-XL-2-1024-MS

技术创新带来的质变
华为诺亚方舟实验室推出的PixArt-α模型,在文本到图像(T2I)技术领域实现了重大突破。该模型以极低的训练成本(约26000美元)和训练时间(约675 A100 GPU天),在图像生成质量上媲美市场领先的模型,如Midjourney(MJ)和Stable Diffusion XL(SDXL),同时实现了高达1024×1024分辨率的高质量图像生成。
训练策略分解的优势
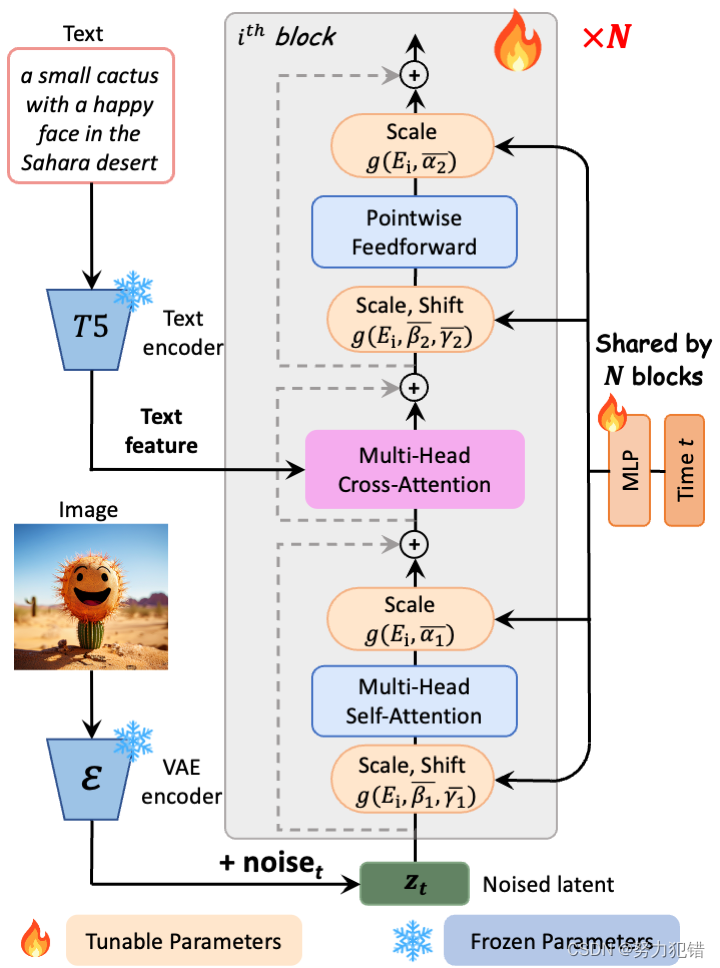
PixArt-α采用的训练策略分解方法是其核心创新之一。通过将训练过程细分为优化像素间依赖、文本图像对齐和图像美学质量的三个阶段,模型能够更加高效地学习和生成复杂图像。这种分阶段的训练方法大幅提高了训练效率,同时确保了生成图像的高质量。
高效的T2I Transformer架构
PixArt-α在其Diffusion Transformer(DiT)架构中融入了创新的交叉注意力层,这一设计不仅简化了计算过程,还提高了文本信息与图像内容的整合效率。这种结构的引入有效地减少了模型的计算负担,同时保持了图像生成的高性能。
利用高信息密度数据
在数据方面,PixArt-α强调了文本图像对中概念密度的重要性。通过使用大视觉语言模型自动标记密集的伪文本标签,模型能够在每次迭代中更有效地学习和生成图像,提高了文本图像对齐的效率。
PixArt-α的实验验证
在多项实验中,PixArt-α在图像质量、艺术性和语义控制方面均表现出色。特别是在与其他领先的T2I模型的对比中,PixArt-α在图像对齐度、属性绑定和复杂组合生成方面展现了其卓越性能。
开创性的应用前景
PixArt-α不仅在技术层面取得了突破,也在成本效益上设置了新的标准。它的出现为AIGC社区和初创公司提供了新的视角,使他们能够以更低的成本构建高质量的生成模型。这对于促进AI领域的广泛应用和创新具有重要的意义。
与 Midjourney 对比:

结论
综上所述,PixArt-α通过其创新的训练策略、架构设计和数据利用,在低成本下实现了高质量的图像生成。这不仅标志着T2I技术的一个重要进步,也为整个AIGC领域提供了新的发展方向和灵感。
模型下载
huggingface模型下载
https://huggingface.co/PixArt-alpha/PixArt-XL-2-1024-MS
AI快站模型免费加速下载
https://aifasthub.com/models/PixArt-alpha/PixArt-XL-2-1024-MS
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!