1.2 ARCHITECTURE OF A MODERN GPU
图1.2显示了典型的支持CUDA的GPU架构的高级视图。它被组织成一系列高线程的流式多处理器(SM)。在图中1.2,两个SM构成一个 block。然而,构建块中的SM数量可能因代而异。此外,在图中,每个SM都有多个共享控制逻辑和指令缓存的流处理器(SP)。每个GPU目前都配有千兆字节的图形双数据速率(GDDR)、同步DRAM(SDRAM),在图1.2中称为全局内存。
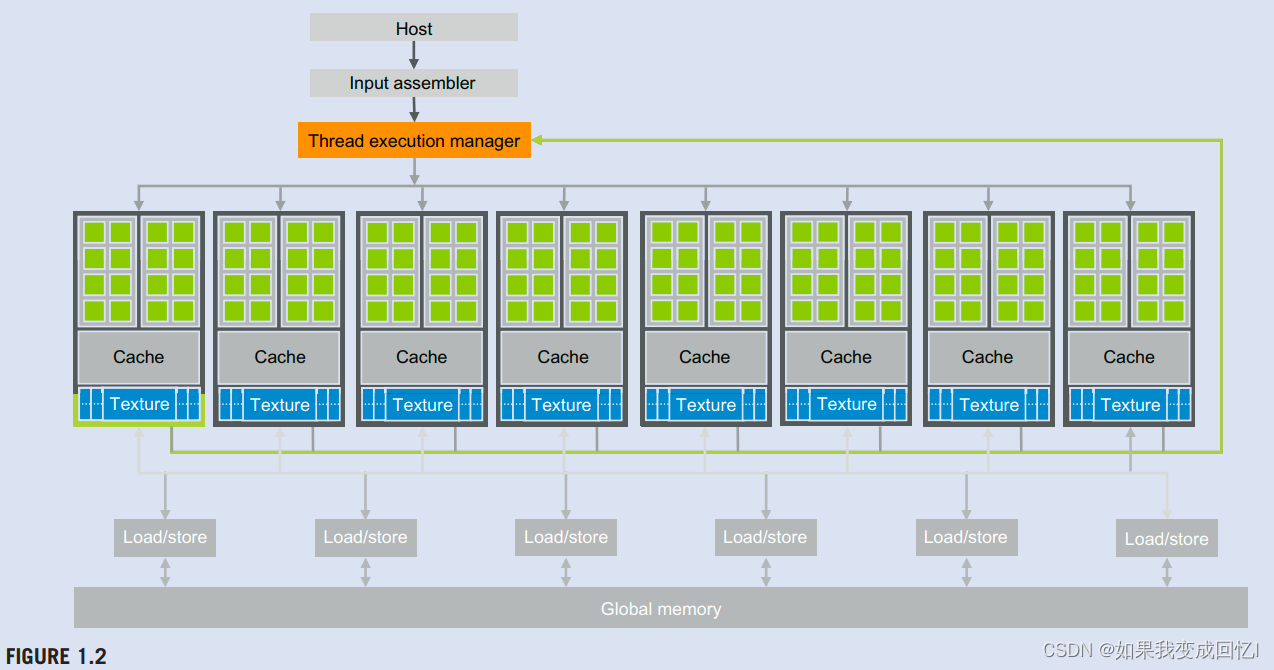 GDDR SDRAM与CPU主板上的系统DRAM不同,因为它们本质上是用于图形的帧缓冲内存。对于gqraphics应用程序,它们保存视频图像和纹理信息用于3D渲染。对于计算来说,它们作为非常高带宽的片外内存,尽管延迟比典型的系统内存要长一些。对于大规模并行应用程序,更高的带宽弥补了更长的延迟。较新的产品,如NVIDIA的Pascal架构,可能使用高带宽内存(HBM)或HBM2架构。为了简洁起看,我们将简单地将所有这些类型的内存称为本书其余部分的DRAM。
GDDR SDRAM与CPU主板上的系统DRAM不同,因为它们本质上是用于图形的帧缓冲内存。对于gqraphics应用程序,它们保存视频图像和纹理信息用于3D渲染。对于计算来说,它们作为非常高带宽的片外内存,尽管延迟比典型的系统内存要长一些。对于大规模并行应用程序,更高的带宽弥补了更长的延迟。较新的产品,如NVIDIA的Pascal架构,可能使用高带宽内存(HBM)或HBM2架构。为了简洁起看,我们将简单地将所有这些类型的内存称为本书其余部分的DRAM。
G80引入了CUDA架构,并通过PCI-Express第2代(Gen2)接口具有与CPU核心逻辑的通信链路。通过PCI-E Gen2,CUDA应用程序可以以4 GB/S的方式将数据从系统内存传输到全局内存,同时以4 GB/S的方式将数据上传回系统内存。总共有8 GB/S。较新的GPU使用PCI-E Gen3或Gen4,每个方向支持8-16 GB/s。Pascal系列GPU还支持NVLINK,这是一种CPU-GPU和GPU-GPU互连,允许每个通道传输高达40 GB/s。随着GPU内存大小的增长,应用程序越来越多地将其数据保存在全局内存中,并且仅在需要使用仅在CPU上可用的库时偶尔使用PCI-E或NVLINK与CPU系统内存通信。未来,随着系统内存的CPU总线带宽的增长,通信带宽预计也会增长。
一个好的应用程序通常在这个芯片上同时运行5000到12,000个线程。对于那些习惯于CPU多线程的人来说,请注意,英特尔CPU支持每个核心的2或4个线程,具体取决于机器型号。然而,CPU越来越多地使用单指令多数据(SIMD)指令以获得高数值性能。GPU硬件和CPU硬件支持的并行性水平正在迅速提高。因此,在开发计算应用程序时,努力实现高水平的并行性非常重要。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!