Dynamic Weighted Neural Bellman-FordNetwork for Knowledge Graph Reasoning
摘要
近年来的研究表明,头部实体的子图(如相关关系和邻域)有助于知识图推理(KGR)。然而,以往的研究往往只关注使用关联关系增强实体表征,很少关注不同关系对不同实体的影响及其在各种推理路径中的重要性。同时,用于知识图谱的传统图神经网络(gnn)同时考虑了头部实体的相邻节点和连接关系,但通常在整个知识图谱(KG)上使用标准的消息传递范式。这导致了过度平滑的表示并限制了效率。为了解决现有方法的上述局限性,我们提出了一种用于KGR的动态加权神经Bellman-Ford网络(Dynamic Weighted Neural Bellman-Ford Network, DyNBF),该网络利用子图生成的关系权重来计算最相关的关系和实体。这样,我们可以更灵活地集成多个推理路径,以实现更好的可解释推理,同时更容易扩展到更复杂和更大的kg。1)基于transform的关系权重生成器模块,利用sequence-to-sequence模型计算路径上不同关系的权重;2)基于nbbfnet的逻辑推理器模块,利用前一个模块的动态权重获取实体表示并进行事实预测。在三个标准KGR数据集上的实证结果表明,该方法可以生成可解释的推理路径,并获得具有竞争力的性能。
1.介绍
知识图(Knowledge Graphs, KGs)存储了大量的事实,包含实体和丰富的结构关系,通常以(h, r, t)的形式表示,其中h为头部实体,r为关系,t为尾部实体。流行的公共KGs包括Freebase[2]、WordNet[12]等。KGs被广泛应用于各种应用,如问答[4]、推荐系统[11]等。
然而,由于人工构建和信息提取技术的影响,目前构建的KGs存在不完备性[21]。例如,在Freebase中,66%的人缺乏出生地关系。为了提高知识图谱的完备性,研究者提出了知识图谱推理(Knowledge Graph Reasoning, KGR)来发现缺失事实。KGR的最新进展主要是通过将每个实体和关系映射到一个低维向量上来实现知识图嵌入(KGE)[3,18,23]。尽管在开发新的KGE算法方面取得了稳步进展,但研究人员仍然面临着一个共同的挑战:将关于实体的所有信息(例如语义和结构)编码为单个向量。为此,一些研究利用图神经网络(gnn)[15,26,27]或基于注意的方法[20,22]来学习基于实体及其图上下文的KGR表示。然而,这些方法的表达能力有限,因为它们的网络架构很浅,并且过度依赖整个kg中的消息传递,这阻碍了它在更大kg中的可扩展性,这也导致了更慢的推理速度。
直观上,对于每个特定的查询,例如(Ma Yun, collaboration with, ?),整个知识图中可能只有一小部分子图[13]与特定的关系类型(如collaboration with)相关。像奖励或配偶这样的关系是没有用的,可能会引入偏见。使用相关子图信息作为上下文,可以识别出给定查询中更重要的关系,从而赋予更高的权重,从而促进准确高效的推理。
更好地利用相关关系和子图信息。基于gatt的聚合方法[25]使用注意权值来学习节点表示,与不使用注意权值的传统gnn生成的节点表示相比,其信息量更大。然而,这些方法以单一方式聚合信息,限制了它们在理解节点的多个属性方面的灵活性。为了解决单一聚合方法的问题,NBFNet[27]共同学习用于组合相邻节点表示的聚合函数的类型和规模,这些表示是源节点条件下的成对表示。这使得gnn能够同时捕获节点的多个属性,对于解决复杂的图问题至关重要。但是,它不是为不同的查询选择相关的关系进行推理,而是聚合所有周围的信息。为了解决上述问题,我们探索了Transformer架构和gnn相结合的动态权重KGR。本文提出的动态加权神经Bellman-Ford网络(Dynamic Weighted Neural Bellman-Ford Network, DyNBF)(与上述已有gnn作品的概述和比较见图1)主要由两个部分组成:1)一个权重生成器,它将相关KG子图识别为上下文并动态生成权重;2)一个逻辑推理器,它联合考虑KG和关系权重来推断答案。通过这种方式,我们可以简单地利用KGR的优化对象,使其具有高效率、准确性和可解释性
我们通过在三种常用基准(WN18RR[6]、UMLS[8]、FB15k-237[17])上进行实验来评估DyNBF。DyNBF的有效性可以通过性能的改善和时间的缩短来证明。
2.相关工作
现有的KGR研究可分为三种主要范式:基于路径的方法、嵌入方法和图神经网络方法。
2.1 Path-Based Methods
随机漫步推理在这类模型中得到了广泛的研究。例如,pathrank算法(pathrank Algorithm, PRA)[9]在路径约束下导出基于路径的逻辑规则。AMIE[7]等规则挖掘方法使用预定义的度量(如置信度和支持度)来修剪不正确的规则。最近,基于TensorLog[5]的可微规则学习方法,如Neural-LP[24]和DRUM[14],学习概率逻辑规则来对不同路径进行加权。Ruleformer[22]引入了一种基于转换器的规则挖掘方法,在可微规则挖掘过程中为查询选择合适的规则。然而,这些方法采用了Tensorlog框架,导致效率低下。此外,它们需要探索指数级多的路径,并且被限制在极短的路径上,例如小于或等于3条边。
2.2 Embedding Methods
嵌入方法通过保留图的边缘结构来学习每个节点和边缘的分布式表示。其中TransE[3]、ComplEx[18]、DistMult[23]等算法大多设计一个评分函数来获取嵌入空间中三元组的值。其中TransE[3]是使用最广泛的KGE方法,它将关系视为从头部实体到尾部实体的转换。DistMult[23]采用了一种基本的双线性公式,并开发了一种利用获得的关系嵌入提取逻辑规则的新方法。ComplEx[18]创建了复杂嵌入的组合,对广泛的二元关系表现出鲁棒性。尽管这些工作很简单,但他们在推理任务中表现出了令人印象深刻的表现。然而,这些模型往往忽略了实体和关系的邻域子图。
2.3 Graph Neural Networks Methods
gnn对图的拓扑结构进行编码,其中大多数框架对节点表示进行编码,并将边解码为节点对上的函数。RGCN[15]处理现实KGR的高度多关系数据特征。NBFnet[27]提出了一种基于两个节点之间路径的通用且灵活的KGR表示学习框架,以增强归纳设置中的泛化、可解释性、高模型容量和可扩展性。对于不同的查询,这个框架的能力可能会受到限制,因为它会平等地查看KGs中的每个关系。这种限制可能妨碍获取丰富的信息,并受到有偏见的训练数据的影响,忽视边缘化实体并导致陈规定型的预测。
3 Methodology
我们建议通过不仅考虑关系权重,而且考虑所使用的聚合函数的类型和尺度来推理答案。为此,我们引入DyNBF来确定每一步中所有关系的权值,并将其作为边缘权值进行聚合,具体如图2所示。具体来说,对于(h, r, t)这样的查询,与头部实体h相关的子图是由KG构造的。然后,使用Transformer权重生成器获得每个聚合的全局关系权重,Transformer权重生成器结合了关系关注机制。最后,将这些全局关系权重分配给nbbfnet中的边缘权重,以实现准确的逻辑推理和预测。这两个组件的详细信息分别在3.1节和3.2节中显示。
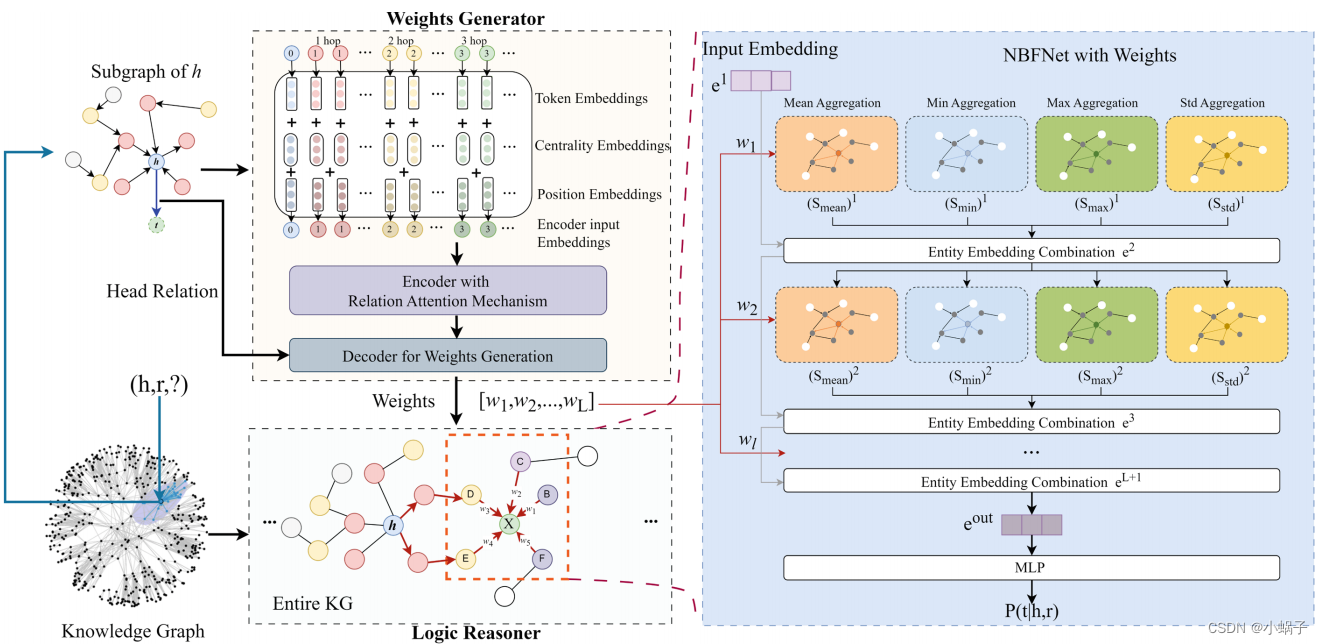
图2所示。DyNBF框架由两个主要组件组成:权重生成器和逻辑推理器。图中逻辑推理器部分的绿色节点X表示我们需要的表示,它聚合了周围节点的信息,红色箭头表示源节点到X的不同路径,不同颜色的节点表示与源节点的不同距离,例如黄色节点表示与源节点h的距离为2跳,紫色节点表示与h大于等于3的距离。(网上彩色图)
3.1 Weights Generator
权重生成器模块的作用是通过利用头部实体的子图动态地生成权重。受Ruleformer[22]的启发,我们利用上下文化子图作为输入序列对局部结构信息进行编码。
我们使用宽度优先的方法从源实体中采样边缘,直到达到指定的上下文预算,这对于通过考虑相关上下文信息来获得子图来丰富查询是值得注意的。为了将图转换为Transformer输入序列,我们采用求和方法将令牌嵌入、中心性嵌入和位置嵌入组合在一起(见图2):
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!