【机器学习合集】深度生成模型 ->(个人学习记录笔记)
深度生成模型
深度生成模型基础
1. 监督学习与无监督学习
1.1 监督学习
定义
- 在真值标签Y的指导下,学习一个映射函数F,使得F(X)=Y

判别模型
- Discriminative Model,即判别式模型,又称为条件模型,或条件概率模型
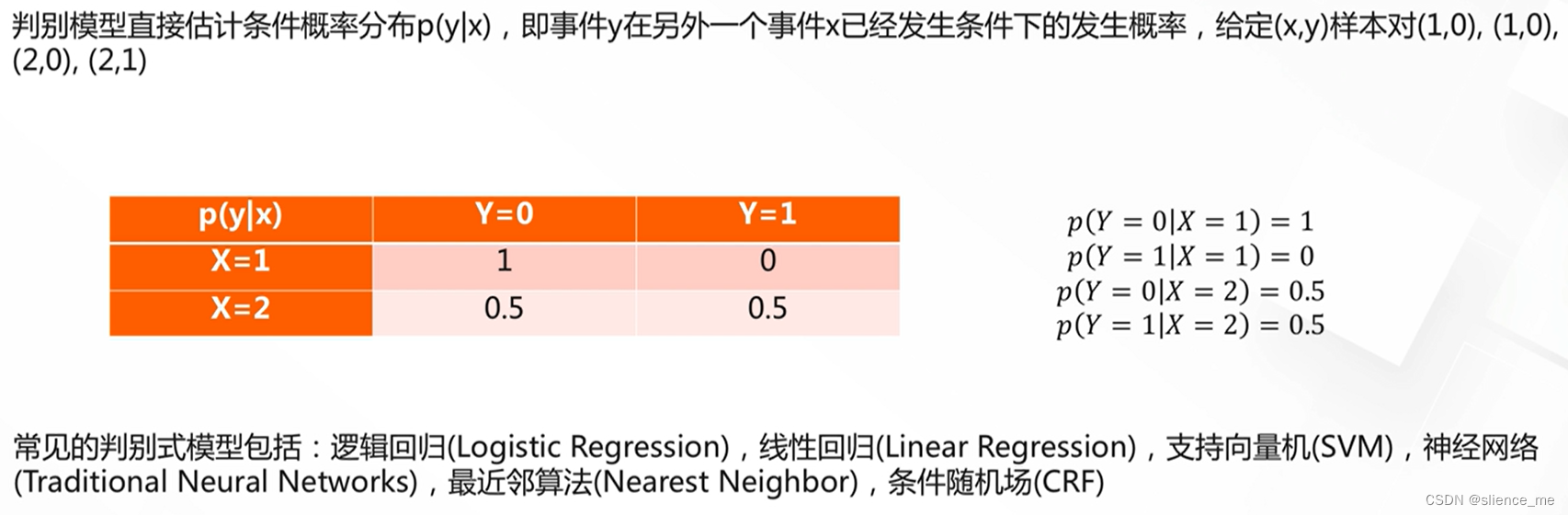
生成模型
- Generative Model,即生成式模型

生成模型与判别模型的对比
- 表达能力,灵活性,学习难度
生成模型和判别模型是深度学习中两种不同类型的模型,它们在任务和目标上有一些关键区别。以下是生成模型和判别模型的对比:
任务和目标:
生成模型的目标是学习数据的分布,以便生成与训练数据类似的新样本。生成模型试图模拟数据的生成过程。
判别模型的目标是对给定输入数据进行分类或标记。判别模型试图学习输入和输出之间的关联,通常用于分类、回归和检测等任务。
输出:
生成模型的输出是一个概率分布,通常是条件概率分布,可以用于生成新的数据样本。典型的生成模型包括生成对抗网络(GANs)、变分自动编码器(VAEs)和隐马尔可夫模型(HMMs)。
判别模型的输出是对输入数据的标签、类别或预测值。典型的判别模型包括卷积神经网络(CNNs)、循环神经网络(RNNs)和支持向量机(SVM)等。
数据需求:
生成模型通常需要更多的数据来学习数据分布,因为它们需要模拟数据的生成过程,涉及到从数据中学习高维概率分布。
判别模型通常需要相对较少的数据,因为它们只需要学习输入和输出之间的关联,而不需要考虑整个数据分布。
生成新数据:
生成模型具有生成新数据样本的能力,因此它们可以用于图像生成、自然语言生成、音频合成等应用。
判别模型通常不具备生成新数据的能力,它们更适合于分类和预测任务。
应用领域:
生成模型在生成式任务中广泛应用,如图像生成、文本生成、语音合成等。它们也用于无监督学习、生成对抗网络中的对抗生成器等领域。
判别模型在分类、目标检测、自然语言处理中的分类任务、情感分析等监督学习任务中得到广泛应用。
总的来说,生成模型和判别模型各自适用于不同的任务和应用领域。生成模型关注数据的生成过程和概率分布,判别模型关注输入和输出之间的关系。在实际应用中,选择合适的模型类型取决于任务的性质和数据的特点。有时也可以结合两种类型的模型以提高性能,例如生成模型用于数据增强,判别模型用于分类。

1.2 无监督学习
定义
- 没有真值标签Y,学习数据的统计规律或潜在结构

2. 无监督生成模型
2.1 定义
- 对输入数据X进行建模,得到概率分布
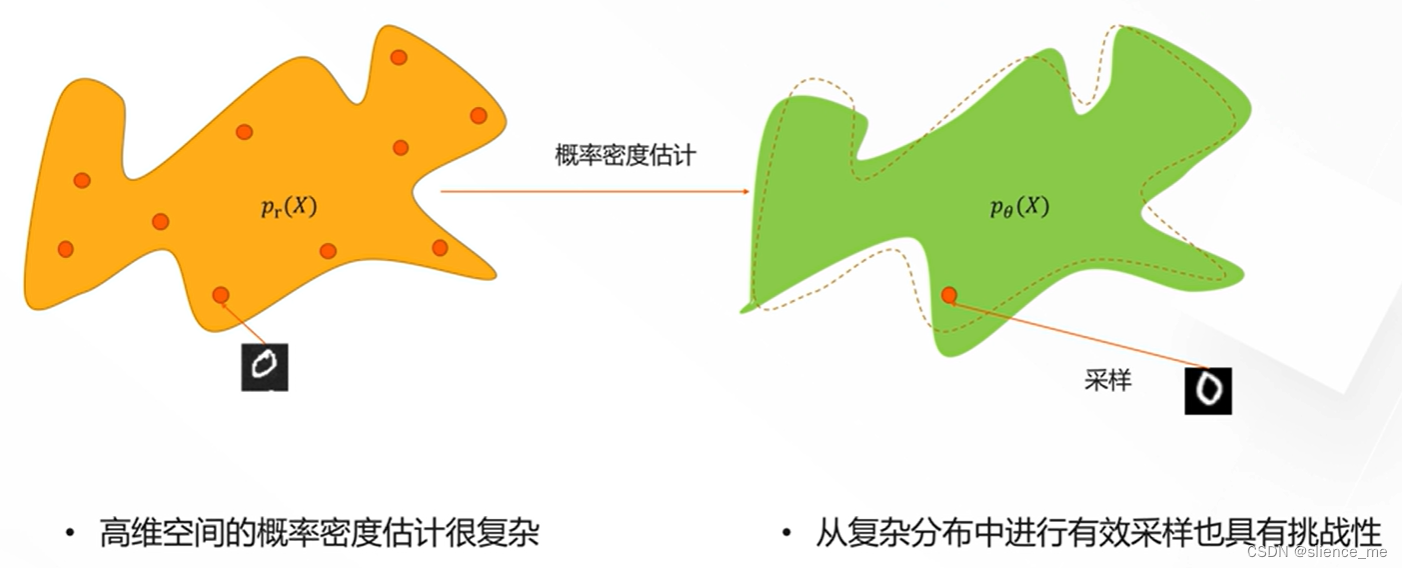
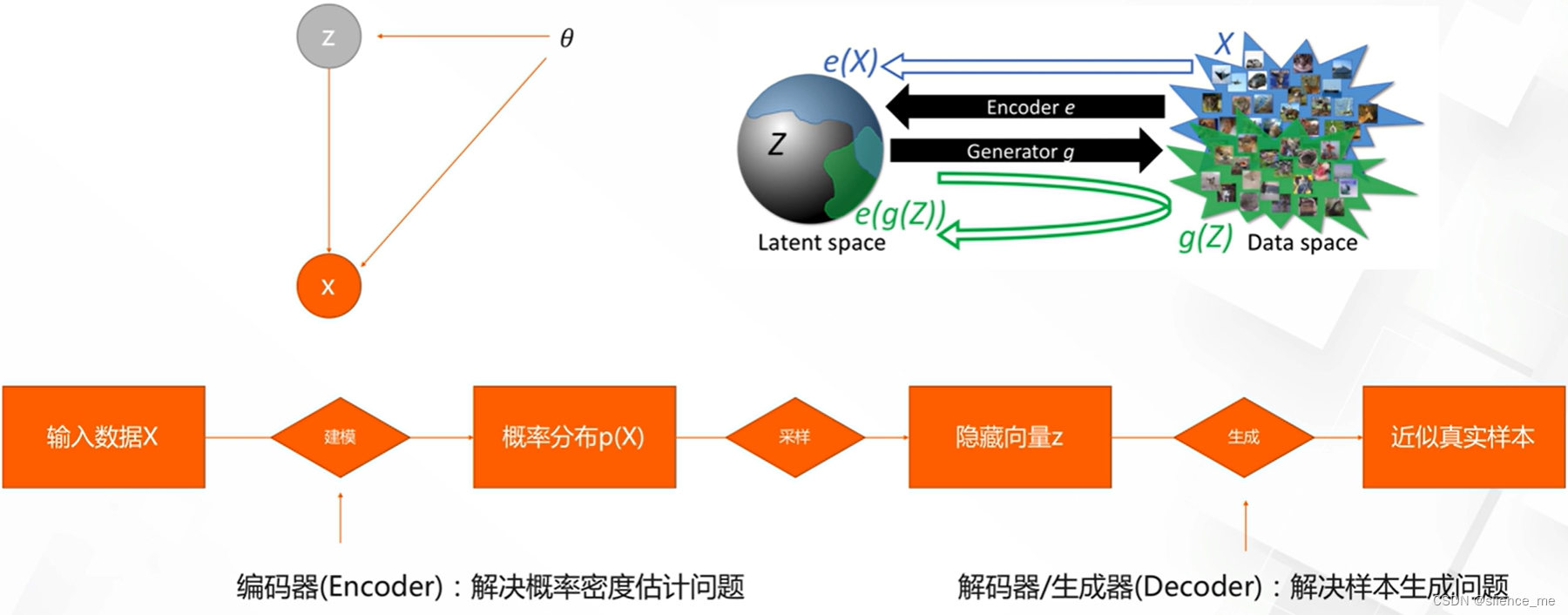
2.2 生成模型隐藏空间
- 直接建模p,(X)非常困难,通过引入不可观测的隐藏变量z
2.3 无监督生成模型分类
- 显式概率模型,隐式概率模型
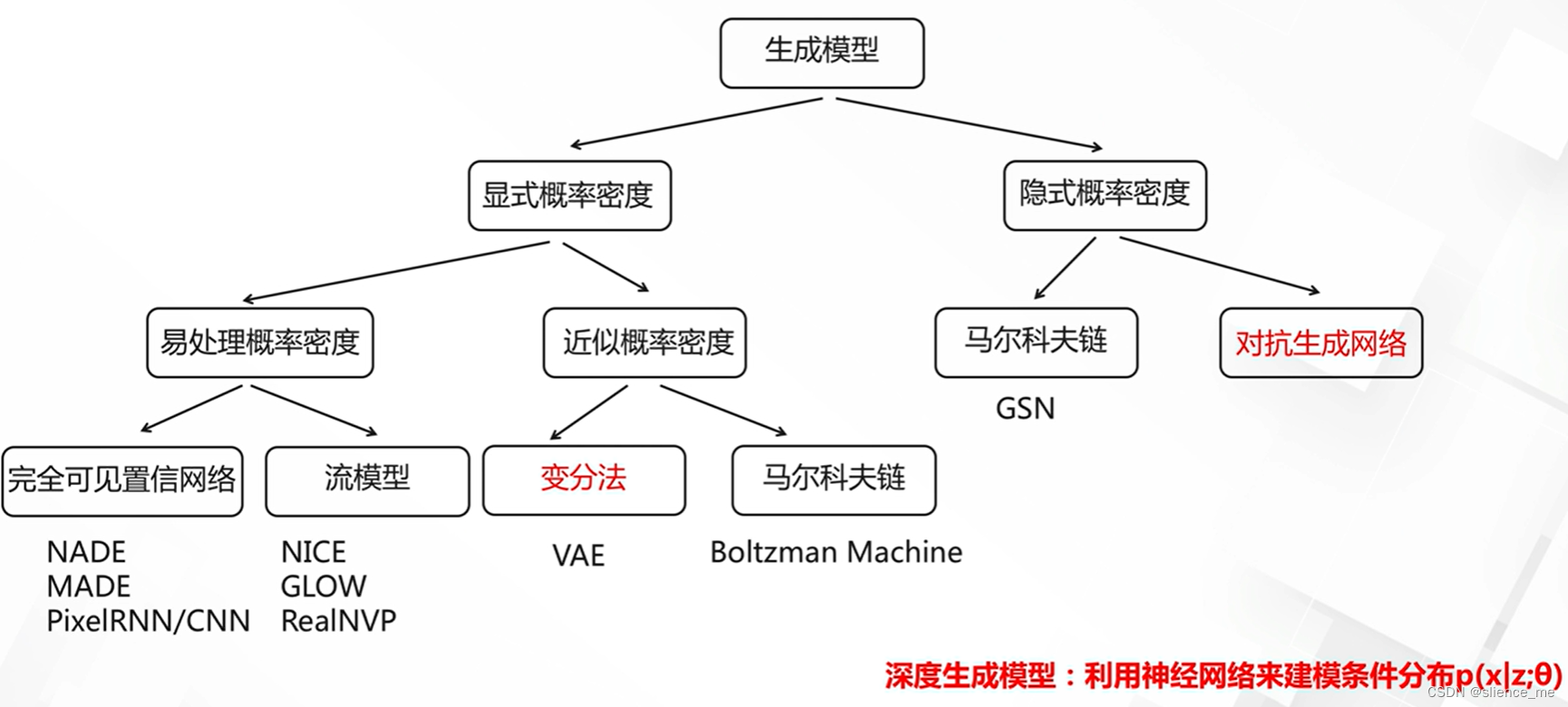
- 显式生成模型求解

- 隐式密度模型求解
K-1703935797030)]
- 显式生成模型求解
[外链图片转存中…(img-89LAyfOa-1703935797031)]
- 隐式密度模型求解

注:部分内容来自阿里云天池
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!