Numpy和Pandas知识点总结
1.python常见的开源库介绍
1.1numpy
一个运行速度非常快的数学库,主要用于数组计算
1.2pandas
一个强大的“分析结构化数据”的工具集,底层依赖numpy
用于数据挖掘和数据分析,同时也提供数据清洗功能
pandas主要有两种数据结构:Series和Dataframe
Series 类似于一维数组,主要用于表示某行或者某列
Dataframe是pandas中一种表格型的数据结构
1.3Matplotlib
一个功能强大的数据可视化开源工具
python中使用最多的图形绘图库
1.4Seaborn
一个python数据可视化开源库,建立在Matplotlib之上
1.5Sklearn
基于python语言的机器学习工具,主要用于数据挖掘和数据分析
1.6 Jupyter Notebook
是进行数据分析学习和开发的首选开发环境
2.Numpy
2.1概述
numpy是python数据分析必不可少的第三方库
2.2Ndarray
numpy的数组类被称为ndarray,通常被称作数组
ndarray的属性有:
ndarray.ndim? 数组是几维的
ndarry.shape? 数组有几行几列
ndarray.size? ?数组中的元素个数
ndarray.dtype? 数组中的元素类型
ndarray.itemsize? 数组中每个元素的字节大小
运行代码

2.3创建ndarray数组
方式1:a=np.array([1,2,3,4,5])
方式2: a=ones((2,3)) /a=zeros((2,3))? 创建全是1的数组或者全是0的数组
方式3: a=np.arange(10,20,2,dtype=int)? 创建起点为10,终点为20,步长为2,数据类型为int的数组
2.4创建ndarray随机数组
以下的范围都是包左不包右
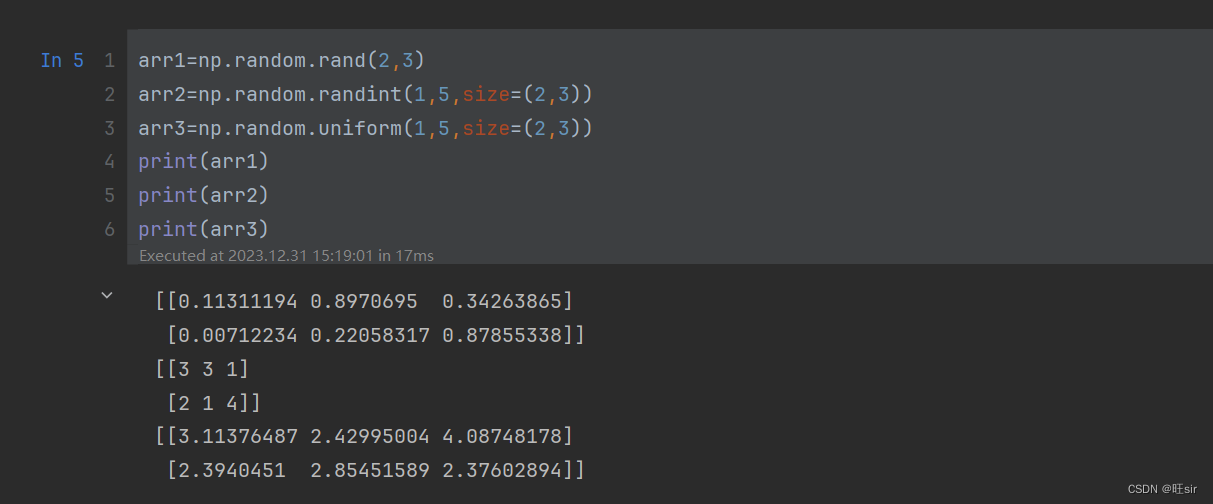
arr1=np.random.rand(2,3)? ?生成一个二行三列的数组,每个元素都是从0到1的小数
arr2=np.random.randint(1,5,size=(2,3))? 生成一个二行三列的数组,每个元素都是从1到5的整数
arr3=np.random.uniform(1,5,size=(2,3))? 生成一个二行三列的数组,每个元素都是从1到5的小数
2.5matrix函数
matrix函数用于创建二维数组
arr1=np.mat('1 2;3 4')
arr2=np.matrix('1,2;3,4')
arr3=np.matrix([[1,2,3],[4,5,6]])
2.6创建等比数组
arr1=np.logspace(1,3,5)? #创建从10到1000的等比数列,元素个数为5个
arr2=np.logspace(1,2,5,base=3,endpoint=True)#创建从3到9的等比数列,元素个数为5个并且包含9
2.7创建等差数列
arr1=np.linspace(1,5,3,endpoint=False) #创建从1到5的等差数组,不包含5,元素个数为3
2.8Numpy的数据类型转化
dtype? 指定数据的类型
astype 转化数据的类型
arr1=np.array([1.2,1.3,1.4],dtype=np.float32)
arr2=arr1.astype(np.int32)
2.9Numpy基本函数
np.ceil()? 向上取整
np.floor()? 向下取整
np.rint()? 四舍五入
np.isnan() 判断元素是否为NAN
np.mutiply() 元素相乘
np.divide()? 元素相除
np.abs()? 求元素的绝对值
np.where(condition,x,y)? 三元运算符,条件成立取x,不成立取y

2.10统计函数
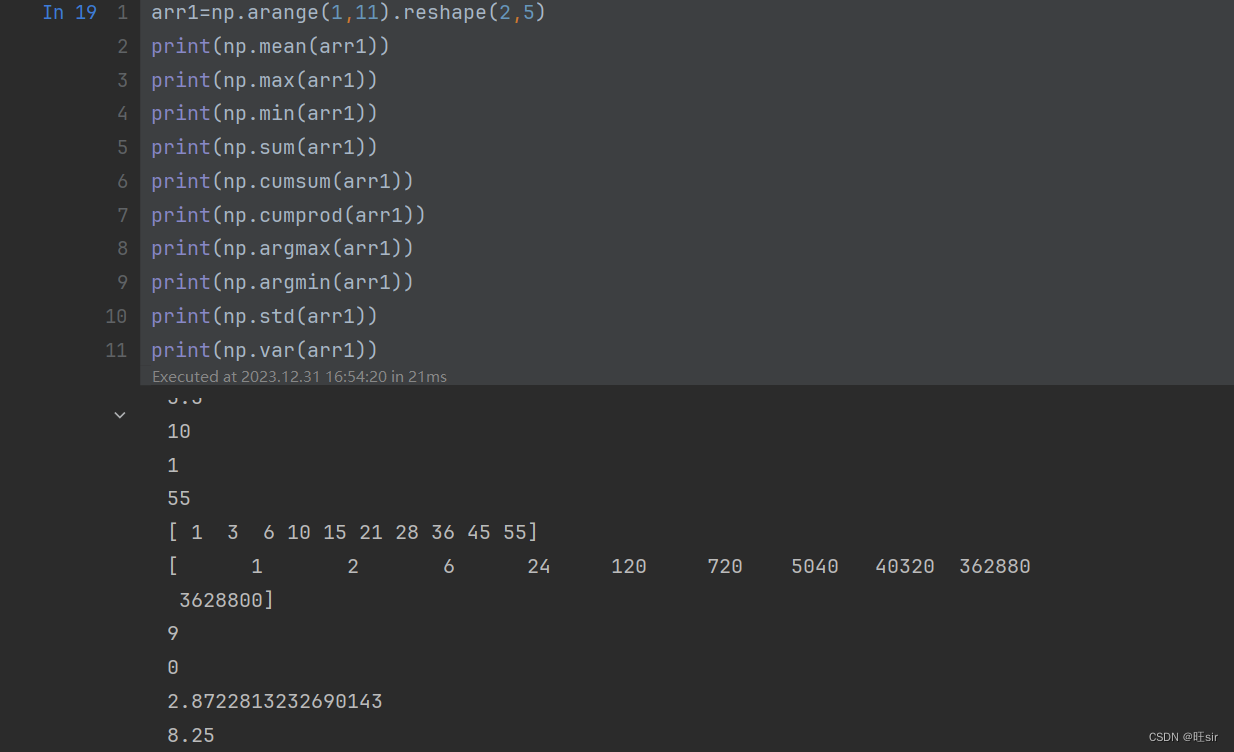
np.mean() 求平均值
np.sum() 求和
np.max() 求最大值
np.min()求最小值
np.argmax()最大值的下标索引
np.argmin()最小值的下标索引
np.cumsum()累加和
np.cumprod()累乘积
2.11比较函数
arr1=np.array([-1,2,3])
print(arr.any(arr1>0)) #任意一个值大于0返回True
print(arr.all(arr1>0))#所有值大于0返回True
2.12去重函数
arr1=np.array([1,2,3],[2,3,4])
print(np.unique(arr1))
2.13排序函数
arr1=np.array([1,3,2,5])
arr2=np.sort(arr1) #对数组排序,返回新的数组
arr1.sort()#直接在原数据上修改
2.14Numpy的运算
arr1=np.array([[1,2,3],[4,5,6]])
arr2=np.array([[1,2,3],[4,5,6]])
print(arr1-arr2)
print(np.multiply(a,b))
#当两个矩阵行数和列数相反时
a.dot(b)
np.dot(a,b)
3.pandas
Dataframe和Series是pandas的两种最基本的数据结构
3.1创建Series对象

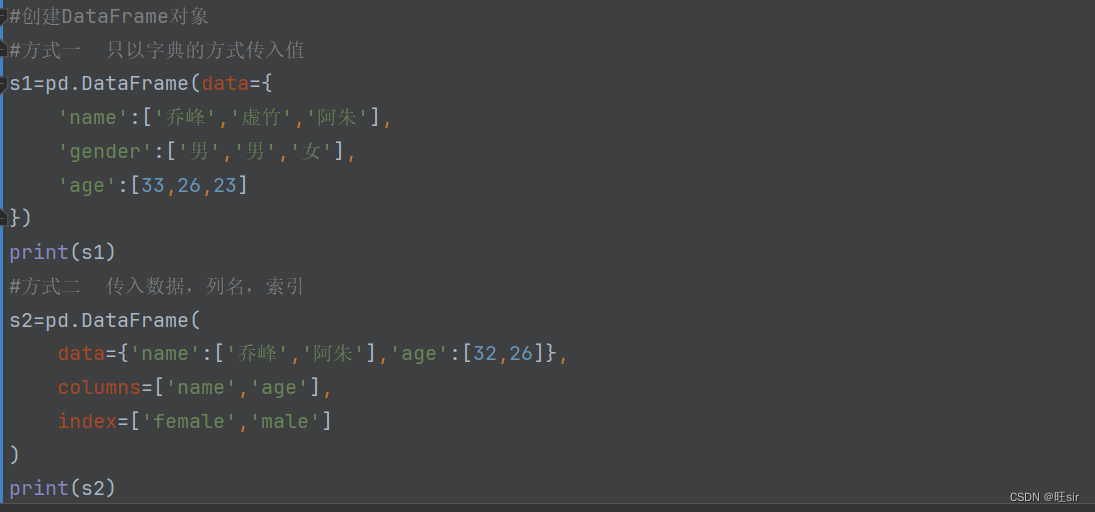
3.2创建Dataframe对象
3.3Series常见操作
创建一个10到101,步长为10的series对象
Series=pd.Series(list(range(10,101,10)))
series的常用属性有:
series.loc[:5]? ?根据索引获取前5条内容,包左包右
series.iloc[:5]? 根据索引获取前5条内容,包左不包右
series.dtype? ?series中每个元素的类型
series.shape? ?series的维度
series.size? ? ? series的元素个数
series.values? ?series中的所有元素值

series的常用方法有:
s1.mean()? ? 平均值
s1.sum()? ? ? ?求和
s1.max()? ? ? ?最大值
s1.min()? ? ? ? 最小值
s1.std()? ? ? ? ?标准差
s1.count()? ? 求个数
series还可以和布尔值数组结合一起使用
s1=pd.Series([1,2,3])
flag=[True,False,True]
s1[flag]? 将True对应的元素留下,将False对应的元素删除
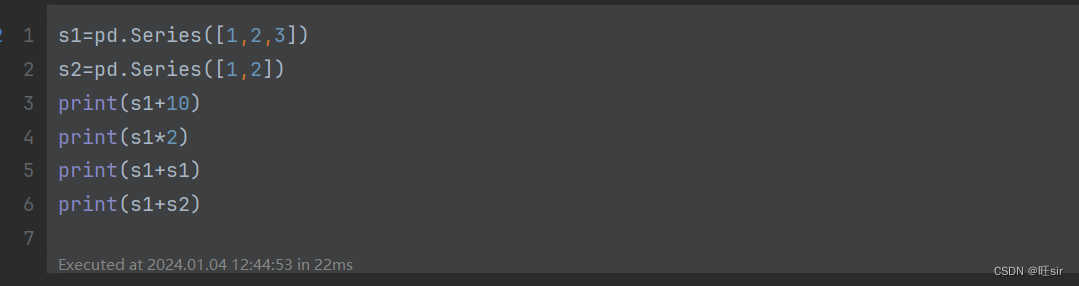
series的计算
series+数值,将series中的每个数值,依次和要加的数值进行计算
series*数值? ? 将series中的每个数值,依次和要乘的数值进行计算
series1+series2? ?将两个series进行计算,会根据对应的索引进行匹配,未匹配的数据用NAN填充
3.4DataFrame常见操作
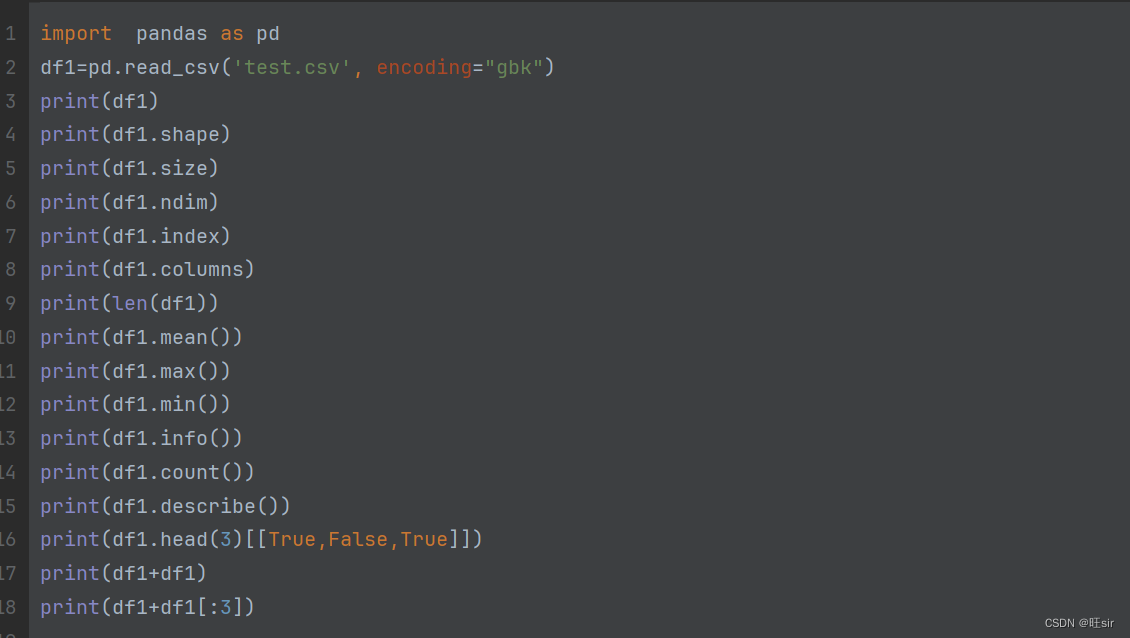
df.shape? ? 查看df的行,列
df.size? ? ? ?df中的元素个数,即行*列的结果
df.nim? ? ? 产看df对象的维度
df.index? ? 查看所有的索引值
df.columns? ?查看所有的列名
len(df)? 查看df对象的行数
df.max()? 返回每列的最大值
df.min()? ?返回每列的最小值
df.mean()? 计算数字列的平均值
df.info()? 查看df对象的信息
df.count()? 查看非空值个数
df.describe()? 查看df对象的详细信息
df也支持通过布尔索引来获取元素
print(df.head(3)[[True,False,True]])? ?获取df对象前三条数据中的第一条和第三条
df对象的运算是通过对应索引来进行的,不匹配的使用nan填充
df1+df1
df1+df1[:3]? df1的前三条数据相加,后面的数据使用nan填充
3.5 修改series对象和DataFrame对象
df1.set_index('id',inplace=True)#为df设置索引列,inplace=True表示在原数据上修改
df=pd.read_csv("data",index_col='id')#读取数据的时候,直接设置索引列
df1.reset_index()? #重置索引列
df1.rename(index={ 1:'A' },colmuns={ 'name': ' 姓名 '})? #使用rename函数修改df的索引和列名

df[ 'new_col']=value? ?#新增一列
df.drop('列名',axis=1/columns)? ?#删除列名
df.insert(loc=列号,column='列名',value='设置的值'?)? #向指定位置插入一列
df=pd.read_csv('文件路径') #导入数据
df1.head(3).to_csv('文件路径') #导出数据
3.6 DataFrame查看部分数据
df['列名']? ?#获取某列数据
df[['列名1','列名2','列名3']] #获取多列数据
df.head(n=3)? #获取前三行数据
df.tail(n=3) #获取后三行数据
df.loc[1]? #根据行索引,获取指定行的数据
df.loc[[1,3,5]] #根据行索引,获取指定多行的数据
df.iloc[1]? #获取行号为1的数据
df.iloc[1,3,5] #获取行号为1,3,5的数据
df.loc[[101,103],['name','age']] #获取指定行指定列的数据
df.iloc[[2,3],[1,2]] #获取指定行,指定列的数据
df.loc[:,['列名1','列名2']]? #获取所有行的指定列的数据
df.iloc[:,[1,-1]] #获取所有行的第二列和最后一列数据
df.iloc[:,list(range(0,2))] #通过range生成列的编号,然后获取所有行对应的列
df.loc[:]? ?包左包右
df.iloc[:]? ?包左不包右

3.7分组和聚合计算
df.groupby('gender')['name'].count()? ? #统计男女总人数
df.groupby('gender')['age'].mean()? ?#统计男女平均年龄
df.groupby(['address','gender'])['age'].count() #统计各地区男女总人数

3.8DataFrame常用的排序方法
#获取最大的n个? ?df.nlargest(n,'列名')
#获取最小的n个? ?df.nlargest(n,'列名')
#按照某列数据进行排列? ? df.sort_values('age',ascending=False)
#按照列一升序,列一的值一致,按照列二降序排列? ? df.sort_values(['列1','列2'],ascending=['True','False'])
#去重后排序? ?df.drop_duplicates('age')

3.9 concat函数
stus=pd.concat([df1,df2])#根据行进行拼接
stus=pd.concat([df1,df2],ignore_index=True) #根据行进行拼接,并且重置索引
stus=df1.append(df2) #如果只是两个df拼接,使用append即可
res_cols=pd.concat([df1,df2],axis=1)? #对两个df对象进行列拼接
3.10 merge函数
df.merge(kf,how='left',on='kongfu_id')? #左表的全集+交集
df.merge(kf,how='right',on='kongfu_id') #右表的全集+交集
df.merge(kf,how='inner',on='kongfu_id')#左表和右表的交集
df.merge(kf,how='outer',on='kongfu_id')#左表的全集+右表的全集
4.缺失值处理
4.1 缺失值
Numpy中缺失值有几种表示形式:NaN,NAN,nan,它们都一样
NaN不等于0也不等于空串
4.2删除缺失值
df.dropna(how='any',axis=0,inplace=True) #只要某一行有缺失值,就删除该行
df.dropna(how='any')#只要某一列有缺失值,就删除该列
4.3填充缺失值
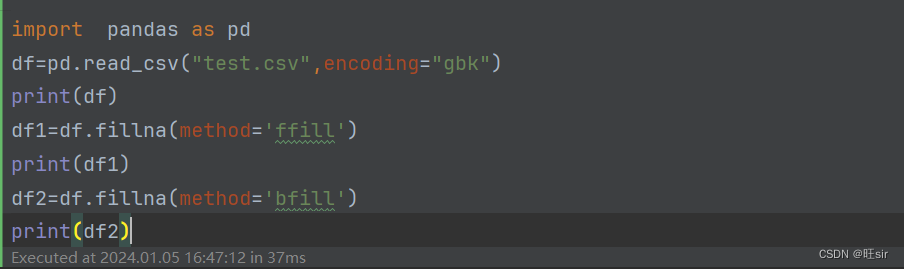
df.fillna(0,inplace=True)
df.fillna(method='ffill',inplace=True)#使用空值的上一个值填充
df.fillna(method='bfill',inplace=True)#使用空值的下一个值填充
5.apply函数
5.1 apply函数操作series对象
s1=pd.Series([1,2,3])
def? my_func(x):
? ? ? return? ?x*3
s2=s1.apply(my_func)
如果函数有多个参数,在调用时需要传参
def? my_func(x,e):
? ? ? ?return? ?x*e
s2=s1.apply(my_func,e=5)
5.2 apply函数操作DataFrame对象
df=pd.DataFrame({ 'col1':[1,2,3],'col2':[4,5,6] })
def? my_func_col(col):? ? #传入的是列
? ? ? ? ?x=col[1]
? ? ? ? ?y=col[2]
? ? ? ? ?z=col[3]
return? x+y+z
df.apply(my_func_col,axis=0)
def? my_func_row(row): #传入的是行
? ? ? ? ?x=row[1]
? ? ? ? ?y=row[2]
return? x+y
df.apply(my_func_row,axis=1)
函数向量化? ? @np.vectorize? def? func1():? ? xxxxxx
lambda 函数? ? 当函数体比较简单,只有一句话的时候,可以使用lambda函数
df.apply(lambda x? : x*3 )
6.数据分组
分组聚合
df1.groupby('gender')['age'].mean()
分组转化
@np.vectorize
def? myfunc(x):? ? #定义转化函数
? ? if x>30:
? ? ? return? '年龄超过30岁了'
? ?return? '年龄没有超过30岁'
df['new_col']=df.groupby('age').age.transform(myfunc)
分组过滤
df.groupby('id').fillter(lambda x :? x.age>20)
7.透视表
#统计各个地区男女总数
df.groupby([address,gender],as_index=False).id.count()
#使用透视表也可以得到相同的结果
df.pivolt(index='address',columns='gender',values='id',aggfunc='count',margins=True)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!