K8S的部署策略,重建更新和滚动更新
Deployment Strategies 部署战略
When it comes time to change the version of software implementing your service, a Kubernetes deployment supports two different rollout strategies:
- Recreate
- RollingUpdate
当需要更改实施服务的软件版本时,Kubernetes 部署支持两种不同的推出策略:
-
重新创建
-
滚动更新
Recreate Strategy 重新创建战略
The Recreate strategy is the simpler of the two rollout strategies. It simply updates the ReplicaSet it manages to use the new image and terminates all of the Pods associated with the deployment. The ReplicaSet notices that it no longer has any replicas, and re-creates all Pods using the new image. Once the Pods are re-created, they are running the new version.
重新创建策略是两种部署策略中最简单的一种。它只需更新其管理的 ReplicaSet 以使用新映像,并终止与部署相关的所有 Pod。ReplicaSet 会注意到它不再有任何副本,并使用新映像重新创建所有 Pod。一旦 Pod 重新创建,它们就会运行新版本。
While this strategy is fast and simple, it has one major drawback—it is potentially catastrophic, and will almost certainly result in some site downtime. Because of this, the Recreate strategy should only be used for test deployments where a service is not user-facing and a small amount of downtime is acceptable.
虽然这种策略快速而简单,但它有一个很大的缺点–有可能造成灾难性后果,几乎肯定会导致网站停机。因此,"重新创建 "策略只能用于服务不面向用户、少量停机时间可以接受的测试部署。
RollingUpdate Strategy 滚动更新策略
The RollingUpdate strategy is the generally preferable strategy for any user-facing service. While it is slower than Recreate, it is also significantly more sophisticated and robust. Using RollingUpdate, you can roll out a new version of your service while it is still receiving user traffic, without any downtime.
对于任何面向用户的服务,RollingUpdate 策略一般都是首选策略。虽然它比 Recreate 慢一些,但也要复杂和强大得多。使用 RollingUpdate,您可以在服务仍在接收用户流量的情况下推出新版本,而无需停机。
As you might infer from the name, the RollingUpdate strategy works by updating a few Pods at a time, moving incrementally until all of the Pods are running the new version of your software.
正如您可能从名称中推断出的那样,RollingUpdate(滚动更新)策略每次更新几个 Pod,循序渐进,直到所有 Pod 都运行新版本的软件。
MANAGING MULTIPLE VERSIONS OF YOUR SERVICE 管理服务的多个版本
Importantly, this means that for a period of time, both the new and the old version of your service will be receiving requests and serving traffic. This has important implications for how you build your software. Namely, it is critically important that each version of your software, and all of its clients, is capable of talking interchangeably with both a slightly older and a slightly newer version of your software.
重要的是,这意味着在一段时间内,新旧版本的服务都将接收请求并提供流量。这对如何构建软件具有重要影响。也就是说,至关重要的是,每个版本的软件及其所有客户端都能与稍旧和稍新版本的软件进行交互对话。
As an example of why this is important, consider the following scenario:
举例说明这一点的重要性,请看下面的情景:
You are in the middle of rolling out your frontend software; half of your servers are running version 1 and half are running version 2. A user makes an initial request to your service and downloads a client-side JavaScript library that implements your UI. This request is serviced by a version 1 server and thus the user receives the version 1 client library. This client library runs in the user’s browser and makes subsequent API requests to your service. These API requests happen to be routed to a version 2 server; thus, version 1 of your JavaScript client library is talking to version 2 of your API server. If you haven’t ensured compatibility between these versions, your application won’t function correctly.
您正在推出您的前端软件;您的服务器一半运行版本 1,一半运行版本 2。用户向您的服务发出初始请求,并下载实现用户界面的客户端 JavaScript 库。该请求由版本 1 服务器提供服务,因此用户收到的是版本 1 客户端库。该客户端库在用户的浏览器中运行,并向您的服务发出后续 API 请求。这些 API 请求恰好被路由到版本 2 服务器;因此,版本 1 的 JavaScript 客户端库正在与版本 2 的 API 服务器进行对话。如果您没有确保这些版本之间的兼容性,您的应用程序将无法正常运行。
At first, this might seem like an extra burden. But in truth, you always had this problem; you may just not have noticed. Concretely, a user can make a request at time t just before you initiate an update. This request is serviced by a version 1 server. At t_1 you update your service to version 2. At t_2 the version 1 client code running on the user’s browser runs and hits an API endpoint being operated by a version 2 server. No matter how you update your software, you have to maintain backward and forward compatibility for reliable updates. The nature of the RollingUpdate strategy simply makes it more clear and explicit that this is something to think about.
起初,这似乎是一个额外的负担。但事实上,你一直都有这个问题,只是没有注意到而已。具体来说,用户可以在启动更新之前的 t 时刻发出请求。该请求由版本 1 服务器提供服务。在 t_1 时,您将服务更新为版本 2。在 t_2 时,运行在用户浏览器上的版本 1 客户端代码会运行并点击由版本 2 服务器操作的 API 端点。无论以何种方式更新软件,都必须保持向后和向前的兼容性,以实现可靠的更新。RollingUpdate 策略的本质只是让我们更清楚、更明确地认识到这一点。
Note that this doesn’t just apply to JavaScript clients—the same thing is true of client libraries that are compiled into other services that make calls to your service. Just because you updated doesn’t mean they have updated their client libraries. This sort of backward compatibility is critical to decoupling your service from systems that depend on your service. If you don’t formalize your APIs and decouple yourself, you are forced to carefully manage your rollouts with all of the other systems that call into your service. This kind of tight coupling makes it extremely hard to produce the necessary agility to be able to push out new software every week, let alone every hour or every day. In the decoupled architecture shown in Figure 10-1, the frontend is isolated from the backend via an API contract and a load balancer, whereas in the coupled architecture, a thick client compiled into the frontend is used to connect directly to the backends.
请注意,这不仅适用于 JavaScript 客户端–编译到其他服务的客户端库也是如此,这些服务会调用您的服务。您更新了客户端库并不意味着他们也更新了客户端库。这种向后兼容性对于将您的服务与依赖于您的服务的系统解耦至关重要。如果您不将 API 正式化并自行解耦,您就不得不仔细管理与调用您的服务的所有其他系统之间的扩展。这种紧密的耦合关系使得你很难实现每周推出新软件所需的敏捷性,更不用说每小时或每天推出新软件了。在图 10-1 所示的解耦架构中,前端通过 API 合同和负载平衡器与后端隔离,而在耦合架构中,编译到前端的厚客户端用于直接连接后端。

CONFIGURING A ROLLING UPDATE 配置滚动更新
RollingUpdate is a fairly generic strategy; it can be used to update a variety of applications in a variety of settings. Consequently, the rolling update itself is quite configurable; you can tune its behavior to suit your particular needs. There are two parameters you can use to tune the rolling update behavior: maxUnavailable and maxSurge.
RollingUpdate 是一种相当通用的策略,可用于在各种设置下更新各种应用程序。因此,滚动更新本身具有很强的可配置性;您可以调整其行为以满足您的特定需求。有两个参数可用于调整滚动更新行为:maxUnavailable 和 maxSurge。
The maxUnavailable parameter sets the maximum number of Pods that can be unavailable during a rolling update. It can either be set to an absolute number (e.g., 3, meaning a maximum of three Pods can be unavailable) or to a percentage (e.g., 20%, meaning a maximum of 20% of the desired number of replicas can be unavailable).
maxUnavailable 参数设置滚动更新期间不可用 Pod 的最大数量。它可以设置为一个绝对数(例如 3,表示最多只能有 3 个 Pod 不可用),也可以设置为一个百分比(例如 20%,表示最多只能有所需副本数量的 20%不可用)。
Generally speaking, using a percentage is a good approach for most services, since the value is correctly applicable regardless of the desired number of replicas in the deployment. However, there are times when you may want to use an absolute number (e.g., limiting the maximum unavailable Pods to one).
一般来说,对大多数服务来说,使用百分比是一种很好的方法,因为无论部署中需要多少副本,该值都能正确适用。不过,有时您可能希望使用一个绝对数字(例如,将不可用 Pod 的最大值限制为 1)。
At its core, the maxUnavailable parameter helps tune how quickly a rolling update proceeds. For example, if you set maxUnavailable to 50%, then the rolling update will immediately scale the old ReplicaSet down to 50% of its original size. If you have four replicas, it will scale it down to two replicas. The rolling update will then replace the removed Pods by scaling the new ReplicaSet up to two replicas, for a total of four replicas (two old, two new). It will then scale the old ReplicaSet down to zero replicas, for a total size of two new replicas. Finally, it will scale the new ReplicaSet up to four replicas, completing the rollout. Thus, with maxUnavailable set to 50%, our rollout completes in four steps, but with only 50% of our service capacity at times.
maxUnavailable 参数的核心是帮助调整滚动更新的速度。例如,如果将 maxUnavailable 设置为 50%,那么滚动更新会立即将旧的 ReplicaSet 缩减到原始大小的 50%。如果有四个副本,它将缩减为两个副本。然后,滚动更新会通过将新的 ReplicaSet 扩展到两个副本来替换被移除的 Pod,总共有四个副本(两个旧的,两个新的)。然后,它将把旧的 ReplicaSet 减少到零个副本,新副本的总大小为两个。最后,它将把新的 ReplicaSet 扩展到四个副本,完成扩展。因此,在 maxUnavailable 设置为 50%的情况下,我们的扩展分四个步骤完成,但有时只能使用 50%的服务容量。
Consider what happens if we instead set maxUnavailable to 25%. In this situation, each step is only performed with a single replica at a time and thus it takes twice as many steps for the rollout to complete, but availability only drops to a minimum of 75% during the rollout. This illustrates how maxUnavailable allows us to trade rollout speed for availability.
如果我们将 maxUnavailable 设置为 25%,会发生什么情况?在这种情况下,每个步骤一次只执行一个副本,因此需要两倍的步骤才能完成推出,但在推出过程中,可用性只下降到最低 75%。这说明了 maxUnavailable 如何让我们用推出速度来换取可用性。
The observant among you will note that the Recreate strategy is identical to the RollingUpdate strategy with maxUnavailable set to 100%.
细心的人会发现,Recreate 策略与 RollingUpdate 策略完全相同,只是 maxUnavailable 设置为 100%。
Using reduced capacity to achieve a successful rollout is useful either when your service has cyclical traffic patterns (e.g., much less traffic at night) or when you have limited resources, so scaling to larger than the current maximum number of replicas isn’t possible.
当您的服务具有周期性流量模式(例如,夜间流量较少),或者当您的资源有限,无法将复制数量扩展到超过当前最大复制数量时,使用减少容量来实现成功推出是非常有用的。
However, there are situations where you don’t want to fall below 100% capacity, but you are willing to temporarily use additional resources in order to perform a rollout. In these situations, you can set the maxUnavailable parameter to 0%, and instead control the rollout using the maxSurge parameter. Like maxUnavailable, maxSurge can be specified either as a specific number or a percentage.
不过,在某些情况下,您不希望容量低于 100%,但又愿意暂时使用额外资源来执行启动。在这种情况下,可以将 maxUnavailable 参数设置为 0%,然后使用 maxSurge 参数来控制启动。与 maxUnavailable 一样,maxSurge 也可以指定为一个具体数字或百分比。
The maxSurge parameter controls how many extra resources can be created to achieve a rollout. To illustrate how this works, imagine we have a service with 10 replicas. We set maxUnavailable to 0 and maxSurge to 20%. The first thing the rollout will do is scale the new ReplicaSet up to 2 replicas, for a total of 12 (120%) in the service. It will then scale the old ReplicaSet down to 8 replicas, for a total of 10 (8 old, 2 new) in the service. This process proceeds until the rollout is complete. At any time, the capacity of the service is guaranteed to be at least 100% and the maximum extra resources used for the rollout are limited to an additional 20% of all resources.
maxSurge 参数可控制创建多少额外资源来实现推出。为了说明其工作原理,假设我们有一个包含 10 个副本的服务。我们将 maxUnavailable 设为 0,maxSurge 设为 20%。扩展要做的第一件事就是将新的 ReplicaSet 扩展到 2 个副本,使服务中的副本总数达到 12 个(120%)。然后,它会将旧的 ReplicaSet 缩减至 8 个副本,服务中的副本总数为 10 个(8 个旧的,2 个新的)。这个过程一直持续到扩展完成。在任何时候,服务的容量都保证至少为 100%,用于扩展的最大额外资源限制为所有资源的 20%。
Setting maxSurge to 100% is equivalent to a blue/green deployment. The deployment controller first scales the new version up to 100% of the old version. Once the new version is healthy, it immediately scales the old version down to 0%.
将 maxSurge 设置为 100% 相当于蓝/绿部署。部署控制器首先会将新版本缩放到旧版本的 100%。版本的 100%。一旦新版本健康,它就会立即将旧版本缩放到 0%。
Slowing Rollouts to Ensure Service Health 放慢推广速度,确保服务健康
The purpose of a staged rollout is to ensure that the rollout results in a healthy, stable service running the new software version. To do this, the deployment controller always waits until a Pod reports that it is ready before moving on to updating the next Pod.
分阶段推出的目的是确保推出运行新软件版本的健康、稳定的服务。为此,部署控制器总是等到某个 Pod 报告准备就绪后,才继续更新下一个 Pod。
The deployment controller examines the Pod’s status as determined by its readiness checks. Readiness checks are part of the Pod’s health probes, and they are described in detail in Chapter 5. If you want to use deployments to reliably roll out your software, you have to specify readiness health checks for the containers in your Pod. Without these checks, the deployment controller is running blind.
部署控制器会根据 Pod 的就绪检查来检查 Pod 的状态。就绪检查是 Pod 健康探针的一部分,第 5 章对此有详细介绍。如果要使用部署来可靠地推出软件,就必须为 Pod 中的容器指定就绪状态检查。没有这些检查,部署控制器就会盲目运行。
Sometimes, however, simply noticing that a Pod has become ready doesn’t give you sufficient confidence that the Pod actually is behaving correctly. Some error conditions only occur after a period of time. For example, you could have a serious memory leak that takes a few minutes to show up, or you could have a bug that is only triggered by 1% of all requests. In most real-world scenarios, you want to wait a period of time to have high confidence that the new version is operating correctly before you move on to updating the next Pod.
但有时,仅仅注意到 Pod 已准备就绪,并不能让你充分相信 Pod 的实际行为是正确的。有些错误只有在一段时间后才会出现。例如,你可能有一个严重的内存泄漏,需要几分钟才会出现,或者你可能有一个错误,只有 1%的请求才会触发。在大多数实际情况下,您都希望在更新下一个 Pod 之前等待一段时间,以便对新版本的正确运行有较高的信心。
For deployments, this time to wait is defined by the minReadySeconds parameter:
对于部署,等待时间由 minReadySeconds 参数定义:
...
spec:
minReadySeconds: 60
...
Setting minReadySeconds to 60 indicates that the deployment must wait for 60 seconds after seeing a Pod become healthy before moving on to updating the next Pod.
将 minReadySeconds 设置为 60 表明,部署必须在看到 Pod 恢复健康后等待 60 秒,才能继续更新下一个 Pod。
In addition to waiting a period of time for a Pod to become healthy, you also want to set a timeout that limits how long the system will wait. Suppose, for example, the new version of your service has a bug and immediately deadlocks. It will never become ready, and in the absence of a timeout, the deployment controller will stall your rollout forever.
除了等待一段时间让 Pod 恢复健康外,您还想设置一个超时时间,限制系统等待的时间。例如,假设新版本的服务出现错误,并立即出现死锁。如果没有超时,部署控制器将永远无法推出新版本。
The correct behavior in such a situation is to time out the rollout. This in turn marks the rollout as failed. This failure status can be used to trigger alerting that can indicate to an operator that there is a problem with the rollout.
在这种情况下,正确的做法是让推出超时。这反过来会将推出标记为失败。这种失败状态可用于触发警报,向操作员说明滚动出现了问题。
At first blush, timing out a rollout might seem like an unnecessary complication. However, increasingly, things like rollouts are being triggered by fully automated systems with little to no human involvement. In such a situation, timing out becomes a critical exception, which can either trigger an automated rollback of the release or create a ticket/event that triggers human intervention.
乍一看,定时推出可能是一个不必要的麻烦。然而,越来越多的情况是,像发布这样的事情是由完全自动化的系统触发的,几乎没有人工参与。在这种情况下,超时就成了一个关键的异常情况,它既可以触发发布的自动回滚,也可以创建一个触发人工干预的票据/事件。
To set the timeout period, the deployment parameter progressDeadlineSeconds is used:
要设置超时时间,可使用部署参数 progressDeadlineSeconds:
...
spec:
progressDeadlineSeconds: 600
...
This example sets the progress deadline to 10 minutes. If any particular stage in the rollout fails to progress in 10 minutes, then the deployment is marked as failed, and all attempts to move the deployment forward are halted.
此示例将进度截止时间设置为 10 分钟。如果推出过程中的任何特定阶段未能在 10 分钟内取得进展,那么部署就会被标记为失败,所有推进部署的尝试都会停止。
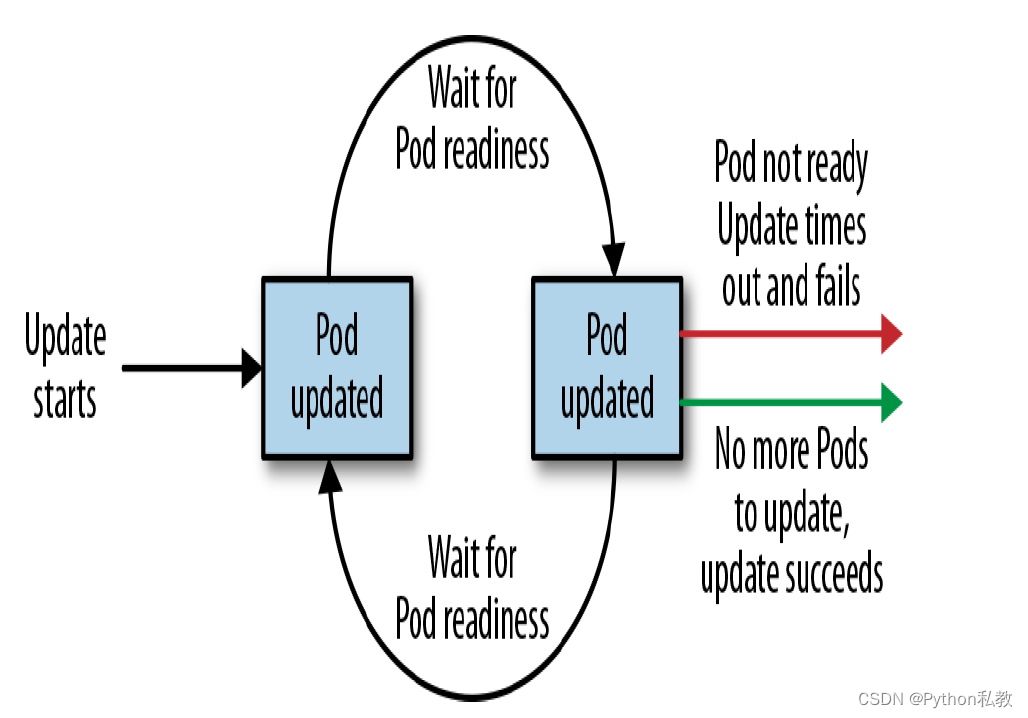
It is important to note that this timeout is given in terms of deployment progress, not the overall length of a deployment. In this context, progress is defined as any time the deployment creates or deletes a Pod. When that happens, the timeout clock is reset to zero. Figure 10-2 is an illustration of the deployment lifecycle.
需要注意的是,超时时间是根据部署进度而不是部署的总长度来确定的。在这种情况下,进度被定义为部署创建或删除 Pod 的任何时间。发生这种情况时,超时时钟会重置为零。图 10-2 是部署生命周期的示意图。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!