Java面试项目推荐,异构数据源数据流转服务DatalinkX
前言
作为一个年迈的夹娃练习生,每次到了春招秋招面试实习生时都能看到一批简历,十个简历里得有七八个是写商城或者外卖项目。
不由得想到了我大四那会,由于没有啥项目经验,又想借一个质量高点的项目通过简历初筛,就找到了谷粒商城,面对408集的视频教程实在是难以坚持到终点。。。并且很多时候都是因为项目里有庞大的增删改查而感到厌烦。(504w的播放量可不得人手一个嘛.....) 如果不想再把外卖商城项目写在简历上,不妨来看看基于Flink的异构数据源流转系统。
【DatalinkX】基于Flink的异构数据源流转系统
Gitee仓库地址:
$?https://gitee.com/atuptown/datalinkx$?
DatalinkX是一个基于Flink大数据引擎的异构数据源同步系统,本质上就是通过页面配置的方式将数据从从来源数据源将数据同步到目标数据源。
既然是异构数据源流转系统,肯定既可以是相同类型的数据源之间流转,也可以是不同的数据源之间流转,有些年轻的朋友可能会疑惑,为什么要有那么多数据源呢?
| MySQL | Oracle不开源 |
| PostgreSQL | MySQL功能不够多 |
| SQLite | 你可以把我纳入到任何地方 |
| DM达梦 | 国货之光,国产数据库! |
| MongoDB | 为什么要用join,文档不香吗? |
| Redis | 为什么要面向文档?动不动内存多快? |
| ElasticSearch | 你们全文检索都不行 |
| Clickhouse | BI场景下唯我独尊 |
| HDFS | 大数据时代,在座的都是弟弟 |
| Memcached | 为什么我们要用磁盘? |
| Bigtable | MongoDB对Web扩展性不行 |
| Hbase | Bigtable不开源 |
| Kafka | 流式数据是未来 |
| Plusar | 懂不懂存算分离的魅力? |
| ... | ... |
随着大数据时代的发展,业务场景的日益复杂,稍具规模的企业内部都会使用各种各样的数据源,不同的数据源类型在不同的场景下能够充分发挥各自的优势,更好的辅助于业务。
而业务数据存储在不同DB中,就需要一个异构数据源之间的数据流转工具来流转和管理数据。
亦或是不同部门之间做数据同步,比如做爬虫的同事把数据爬到了MySQLa,而后端同事的服务使用的都是MySQLb,你需要把爬虫同事的数据拿来完成业务开发。
手动同步一次可以,也不能天天手动同步吧,那么这时候如果你有DatalinkX,你只需配置好两个数据源的连接信息和同步任务,就会按照你定时的时间将MySQLa中的数据一条不漏的同步到MySQLb中。
技术架构
| Spring Boot | 2.4.3 | 项目脚手架 |
| SpringData JPA | 2.4.3 | 持久层框架 |
| MySQL | 8.0 | DB数据库 |
| Redis | 5.0 | RedisStream消息队列 |
| ChunJun(原FlinkX) | 1.10_release | 袋鼠云开源数据同步框架 |
| Flink | 1.10.3 | 分布式大数据计算引擎 |
| Xxl-job | 2.3.0 | 分布式调度框架 |
| Retrofit2 | 2.9.0 | RPC通信服务 |
| Jackson | 2.11.4 | 反序列化框架 |
| Maven | 3.6.X | Java包管理 |
| Vue.js | 2.X | 前端框架 |
| AntDesignUI | 3.0.4 | 前端UI |
| Docker | 容器化部署 |
QA
- SpringBoot没啥好说的,Java后端的看家技能,基础脚手架依赖。版本比较低是因为懒得换了.....
- 为啥用JPA不用Mybatis是因为毕业之后一直在用JPA快忘了Mybatis咋用了,为了用的顺手就用JPA了,有不喜欢的同学直接用Mybatis、Mybtais-plus都可以,这个项目的重点不是DB层的增删改查
- FlinkX低版本跟高版本中我们需要的数据流转模块的差异不是很大,1.10_release我最熟悉直接用,当时咔咔调试源码
- Retrofit2基于Http的优雅RPC通信服务,项目里基于这个封装了一层通用clinet
- Xxl-job和Jackson没啥好说的,优秀的开源组件
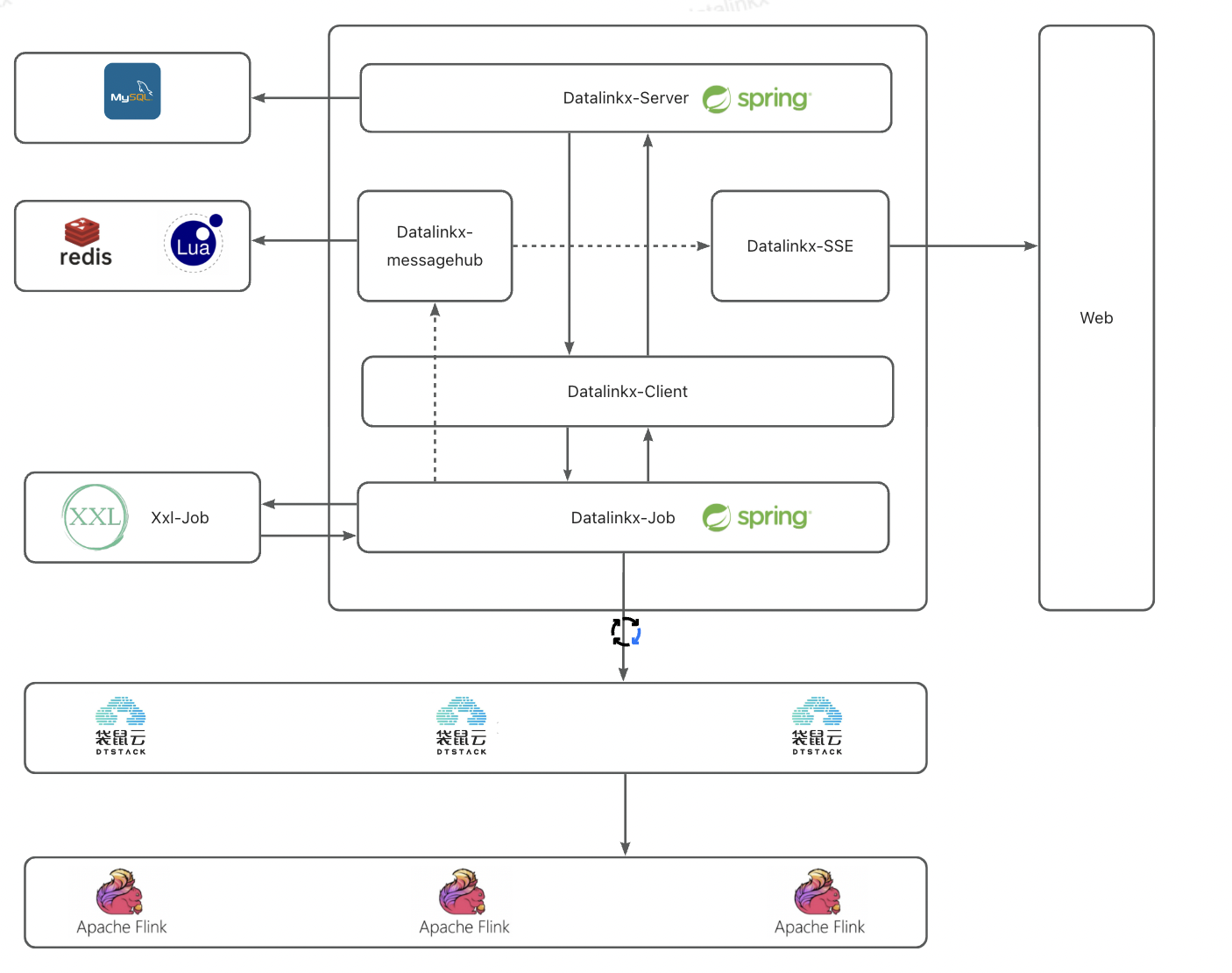
在系统设计中,采用最新 JDK8 + SpringBoot2分布式架构,构建高性能大数据量下稳定可靠的数据流转系统。通过学习DatalinkX项目,不仅能了解其运作机制,还能接触最新技术体系带来的新特性,从而拓展技术视野并提升自身技术水平。
DatalinkX前后端分离架构,前端使用Vue + AntDesignUI,在学习过程中,通过前端系统直接调试后端服务,可以避免纯通过接口测试的繁琐,使得学习过程更加流畅高效。
项目文档
共计40核心技术文档,帮助你深入了解以及快速上手DatalinkX系统。项目中的文档包括六个部分,项目介绍、快速启动、核心技术文档、组件解析、常见问题Q&A、面试问题交流。可根据自己的兴趣选择深入了解核心技术或从零到一复刻系统。常见问题Q&A、面试问题交流这两个模块会根据反馈持续更新。
要去深入学习一个服务,最快的方式就是先把项目运行起来,然后结合服务的业务逻辑慢慢调试代码,所以大家不要因为没有接触过Flink、Xxl-Job等等相关组件就望而却步。只要基于SpringBoot的开发能力即可学习DatalinkX服务。
常见问题答疑
Q:DatalinkX的面向人群?
A:常年浸泡在增删改查的业务代码里的从业者、有Springboot基础的的学生、想搞个毕业设计的毕业生
Q:学了DatalinkX有什么好处?
A:
- 掌握合理的亿级数据同步架构设计
- 对多线程编程做一次深入实践
- 体验极致封装与多态技巧
- 多类型数据源插件设计技巧
- 掌握FlinkX优秀同步框架原理及使用
- 掌握基于Redis Stream的消息队列
- 了解Flink批流一体的大数据引擎
- 分布式调度系统Xxl-Job实践
- 企业级应用的部署与运维
- .....
Q:工作后有必要看DatalinkX吗
A:这个项目质量还是很高的,代码运用了很多设计模式去适配当下最流行的技术组件,如果苦恼工作中都是增删改查的朋友很有必要看一手。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!