《Vue.js设计与实现》—Vue3响应系统的原理
一、响应式数据与副作用函数
1. 副作用函数
1-1 指令材料
在JavaScript中,副作用函数是指在执行过程中对外部环境产生可观察的变化或影响的函数。这种函数通常会修改全局变量、修改传入的参数、执行I/O操作(如读写文件或发送网络请求)、修改浏览器的DOM结构、订阅事件等。
1-2 限定条件
修改全局变量、修改传入的参数、执行I/O操作(如读写文件或发送网络请求)、修改浏览器的DOM结构、订阅事件等
1-3 有效实例
- 修改全局变量:
let count = 0;
function increment() {
count++;
}
console.log(count); // 0
increment();
console.log(count) // 1
总结规律: 修改了全局变量的函数,叫做副作用函数
- 修改传入的参数:
function addOne(arr) {
arr.push(1);
}
let numbers = [1, 2, 3];
console.log(numbers); // [1, 2, 3]
addOne(numbers);
console.log(numbers); // [1, 2, 3, 1]
总结规律:修改了入参的值的函数,叫做副作用函数
- 发送网络请求:
function fetchData() {
fetch('https://api.example.com/data')
.then(response => response.json())
.then(data => console.log(data))
.catch(error => console.error(error));
}
fetchData(); // 发送网络请求并打印返回的数据
发送网络请求涉及到与外部资源的交互,例如向服务器发送数据并等待响应。这个过程会导致网络连接的建立和断开,数据的传输和处理等。这些操作都会改变系统的状态,例如网络连接状态、数据的传输状态等。
由于发送网络请求会引起系统状态的改变,因此它被认为是副作用函数。
总结规律: 改变网络连接状态、数据的传输状态的函数,叫做副作用函数
- 修改浏览器的DOM结构:
<button id="myButton">Click me</button>
<script>
function changeButtonText() {
document.getElementById('myButton').textContent = 'Clicked!';
}
document.getElementById('myButton').addEventListener('click', changeButtonText);
</script>
总结规律:修改了浏览器的DOM结构(包括文本内容)的函数,叫做副作用的函数
- 订阅事件:
function handleKeyPress(event) {
console.log('Key pressed:', event.key);
}
document.addEventListener('keypress', handleKeyPress);
当我们订阅一个事件时,我们正在告诉系统在特定条件下执行某些操作。这些操作可能涉及到与外部资源的交互,例如向数据库写入数据、发送通知、更新UI等。这些操作会改变系统的状态,例如数据的更新、UI的变化等。
由于订阅事件会引起系统状态的改变,因此它被认为是副作用函数。
总结规律: 使用addEventListener订阅事件的函数,叫做副作用函数。
总结:调用函数时,函数改变了函数外的变量或系统状态,包括全局变量、入参的值、改变网络连接状态、数据的传输状态、浏览器的DOM结构、可能涉及与外部资源进行交互的函数,统称为副作用函数。
简而言之:函数影响了外部的变化,就产生了副作用,即该函数就叫做副作用函数。
1-4 新知识与旧知识的关联
副作用函数和全局样式覆盖导致页面的错位
本质上:都是外部环境发生变化,从而产生了副作用
1-5 表达转述
副作用函数就像吃感冒药,感冒药能治好你的病(函数本身的作用),同时也让你原本身体的抵抗力下降了(副作用)。

2. 响应式数据
假设在一个副作用函数中读取了某个对象的属性:
const obj = {text: 'hello world'}
function effect() {
// effect函数执行时会读取obj.text
document.body.innerHTML = obj.text
}
当obj.text的值发生变化时,我们希望副作用函数effect会重新执行,如果能实现这个目标,那么对象obj就是响应式数据。
obj.text = 'hello Vue3' // 当执行这段代码时,自动触发effect()方法,obj就是响应式数据
总结规律:当某个对象的属性发生改变时,如果读取该对象属性的副作用函数自动执行,那么这个对象就是响应式数据。
二、响应式数据的基本实现
1. 观察发现两点线索
- 当副作用函数effect执行时,会触发字段obj.text的读取操作
- 当修改obj.text的值时,会触发字段obj.text的设置操作。
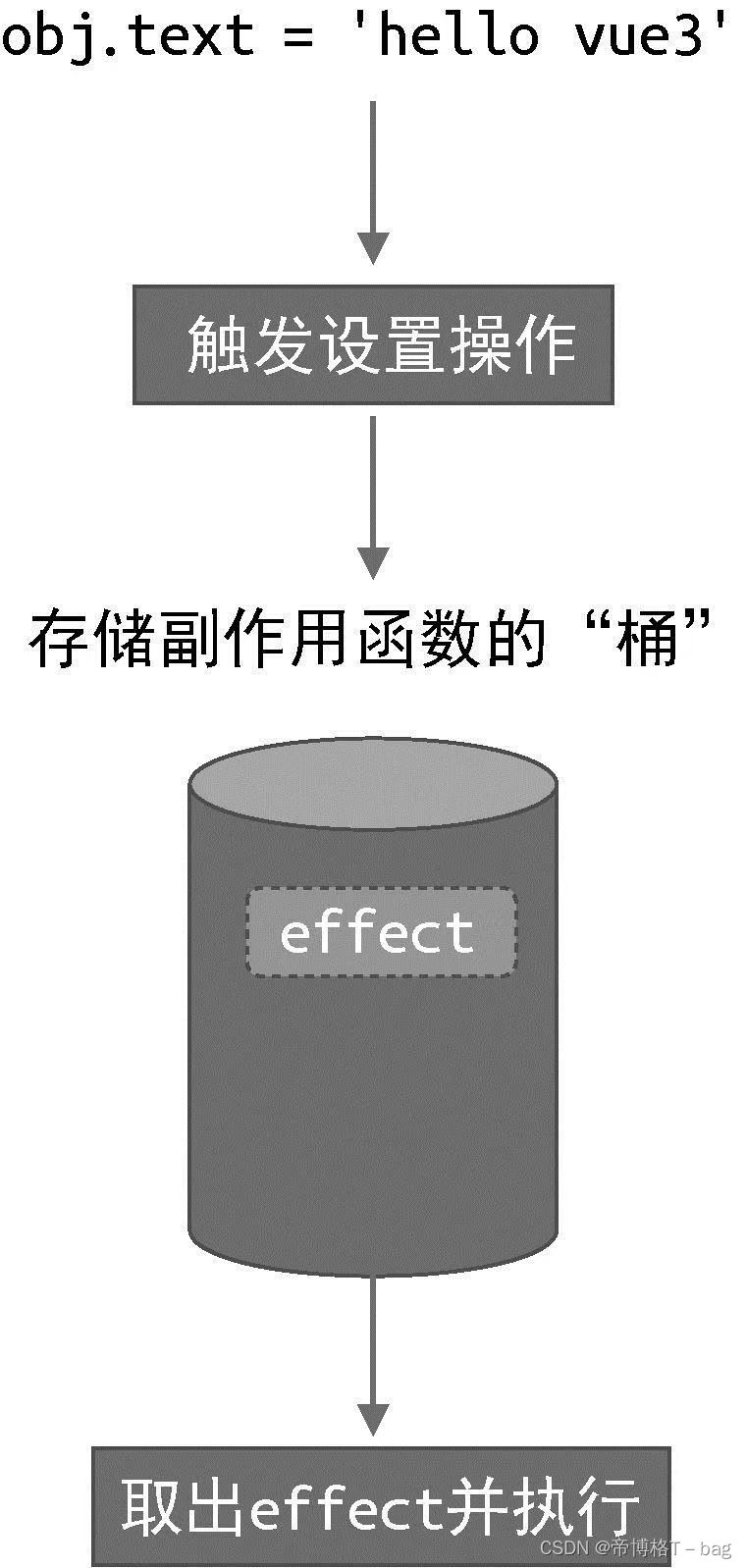
2. 实现思路
-
拦截对象读取和设置操作
-
当我们读取obj.text时,我们可以把副作用函数effect存储到一个“桶”中

-
当我们设置obj.text时,再把副作用函数effect从“桶”里取出来并执行即可
3. 拦截器的实现方式
Vue2 使用 Object.defineProperty 函数实现
Vue3 中使用ES6的 代理对象Proxy实现
// 存储副作用函数的桶
const bucket = new Set()
// 原始数据
const data = {text: 'hellowold'}
// 对原始数据的代理
const obj = new Proxy(data, {
// 拦截读取操作
get(target, key) {
// 将副作用函数 effect 添加到存储副作用函数的桶中
bucket.add(effect)
return target[key]
},
// 拦截设置操作
set(target, key, newVal) {
// 设置属性值
target[key] = newVal
// 把副作用函数从桶中取出并执行
bucket.forEach(fn => fn())
// 返回true 代表设置操作成功
return true
}
})
function effect() {
document.body.innerHTML = obj.text
}
// 执行副作用函数, 触发读取
effect()
// 1秒后修改响应式数据
setTimeout (() => {
obj.text = 'hello vue3'
}, 1000)
总结:
- 设置一个拦截器,读取拦截时,把读取该属性的副作用函数放入桶中
- 设置拦截时,把该副作用函数从桶中并执行,从而实现响应式数据
4. 新知识与旧知识关联
响应式数据 和 垃圾回收机制的引用计数
属性被读取时,副作用函数被存储在“桶”中,属性被设置时,副作用函数从“桶”取出来,并执行
对象在被引用时,对象的引用计数 +1,当对象不被引用时,引用计数就是为0,所使用的内存即被垃圾回收机制回收
本质上:被引用时,进行内存存储,无需使用时,进行内存释放。
// 把 {name: ‘John’} 代指A
// A 对象被obj1 引用1次,A 引用计数=1次
let obj1 = { name: 'John' };
// A 对象被obj2 引用1次,A 引用计数=2次
let obj2 = obj1;
// 解除obj1 的引用对象A, A 引用计数 = 1 次
obj1 = null;
// 解除obj2 的引用对象A, A 引用计数 = 0 次
obj2 = null;
// 对象A 没有被任何变量引用,将被垃圾回收机制回收
5. 转换表述
响应式数据就像是一个关联器,把生活影像和某个词语进行关联,我们生活中事情片段都会被大脑记录下来,突然有人问你,什么是幸福时,大脑就会自动把相关的影像自动的播放出来。

三、设置一个完善的响应式系统
1. 响应系统的工作流程
- 当读取操作发生时,将副作用函数收集到“桶”中;
- 当设置操作发生时,从“桶”中取出副作用函数并执行
2. 副作用函数的匿名化
- 硬编码副作用函数的名称,一旦副作用函数的名字改名了,代码无法正常工作
- 希望副作用函数是一个匿名函数,也能够被正确的收集到“桶”中
- 需要提供一个用来注册副作用函数的机制
// 用一个全局变量存储被注册的副作用函数
let activeEffect
// effect 函数用来注册副作用函数
function effect(fn) {
// 当调用effect注册副作用函数时,将副作用函数fn赋值给activeEffect
activeEffect = fn
// 执行副作用函数
fn()
}
调用优化
effect (
// 一个匿名的副作用函数
() => {
document.body.innerHTML = obj.text
}
)
梳理逻辑:
- 使用一个匿名副作用函数作为effect函数的参数
- 当effect函数执行时,首先会把匿名的副作用函数fn 赋值给全局变量 activeEffect。
- 接着执行被注册的匿名副作用函数fn,这将会触发响应式数据的obj.text的读取操作,进而触发代理对象Proxy的get拦截函数
const obj = new Proxy (data, {
get(target, key) {
// 将activeEffect 中存储的副作用函数收集到“桶”中
if (activeEffect) {
bucket.add(activeEffect)
}
return target[key]
},
set (target, key, newVal) {
target[key] = newVal
bucket.forEach(fn => fn())
return true
}
})
整合所有代码,放入控制台测试一下
// 用一个全局变量存储被注册的副作用函数
let activeEffect
// effect 函数用来注册副作用函数
function effect(fn) {
// 当调用effect注册副作用函数时,将副作用函数fn赋值给activeEffect
activeEffect = fn
// 执行副作用函数
fn()
}
// 存储副作用函数的桶
const bucket = new Set()
// 原始数据
const data = {text: 'hellowold'}
const obj = new Proxy (data, {
get(target, key) {
// 将activeEffect 中存储的副作用函数收集到“桶”中
if (activeEffect) {
bucket.add(activeEffect)
}
return target[key]
},
set (target, key, newVal) {
target[key] = newVal
bucket.forEach(fn => fn())
return true
}
})
effect (
// 一个匿名的副作用函数
() => {
document.body.innerHTML = obj.text
}
)
// 1秒后修改响应式数据
setTimeout (() => {
obj.text = 'hello vue3'
}, 1000)
2-1 新知识与旧知识关联
命名函数转换为匿名函数 与 类的使用
本质上:通过对代码的封装,把多种实例的相同属性,抽象成一类公共事物,并提高代码的可维护性和可复用性
// 命名函数
function add(a, b) {
return a + b;
}
// 将命名函数转换为匿名函数
var addFunc = function(a, b) {
return a + b;
};
// 使用匿名函数
console.log(addFunc(2, 3)); // 输出: 5
通过将命名函数转换为匿名函数,我们可以将函数赋值给变量,并根据需要在代码中使用它。这种转换可以提供更大的灵活性和代码封装性,使得代码更易于维护和复用。
// 学生类
class Student {
constructor(name, age, grade) {
this.name = name;
this.age = age;
this.grade = grade;
}
introduce() {
console.log(`我是${this.name},今年${this.age}岁,读${this.grade}年级。`);
}
}
// 创建学生实例
const student1 = new Student("张三", 15, 9);
const student2 = new Student("李四", 16, 10);
const student3 = new Student("王五", 14, 8);
// 调用学生实例方法
student1.introduce(); // 输出: 我是张三,今年15岁,读9年级。
student2.introduce(); // 输出: 我是李四,今年16岁,读10年级。
student3.introduce(); // 输出: 我是王五,今年14岁,读8年级。
通过抽象一个学生类,创建了多个学生实例,并且可以方便地调用实例的方法和访问实例的属性。这种面向对象的编程方式可以帮助我们更好地组织和管理代码,并提高代码的可维护性和可复用性。
2-2 表达转述
命名函数就像,周一吃猪脚饭、周二吃杀猪粉、周三吃大盘鸡、周四吃哈迪斯、周五吃炒菜。
匿名函数就像,找到每个实例的共性,统称为出去吃饭

3. 建立副作用函数与被操作的字段的关联性
假如在响应式数据obj设置一个不存在的属性时
effect (
// 匿名副作用函数
() => {
console.log('effect run')
// 会打印2次
document.body.innerHTML = obj.text
}
)
setTimeout(() => {
// 副作用函数中并没有读取notExist 属性的值
obj.notExist = 'hello vue3'
}, 1000)
分析现象:
可以看到,匿名副作用函数内部读取了字段obj.text的值,于是匿名副作用函数与字段obj.text之间会建立响应联系。
接着,开启一个定时器,1秒后对为对象obj添加新的notExist属性。
我们知道在匿名副作用函数内没有读取obj.notExist属性的值,所以理论上,字段obj.notExist 并没有与副作用函数建立联系,
因此,定时器内的语句执行不应该触发匿名副作用函数重新执行。实际上,obj.notExist 的赋值也触发了副作用函数的执行
找到原因:
然后导致这个问题的根本原因是,我们没有在副作用函数与被操作的目标字段之间建立明确的关系。
解决方法:
只需要在副作用函数与被操作的字段之间建立联系即可,这需要我们重新设计“桶”的数据结构
提出问题:
应该设计怎样的设计数据结构?
观察代码
effect (function effectFn() {
document.body.innerHTML = obj.text
})
这段代码中存在三个角色
- 被操作(读取)的代理对象obj;
- 被操作(读取)的字段名text;
- 使用effect函数注册的副作用函数effectFn
如果用target 表示一个代理对象所代理的原始对象,用key来表示被操作的字段名,用effectFn来表示被注册的副作用函数
三个角色关系如下:

如果有两个副作用函数同时读取同一个对象的属性值
effect (function effectFn1 () {
obj.text
})
effect (function effectFn2 () {
obj.text
})
关系如下:

如果一个副作用函数中读取了同一个对象的两个不同属性
effect(function effectFn() {
obj.text1
obj.text2
})

如果在不同的副作用函数中读取了两个不同对象的不同属性
effect (function effectFn1 () {
obj1.text1
})
effect (function effectFn2 () {
obj2.text2
})
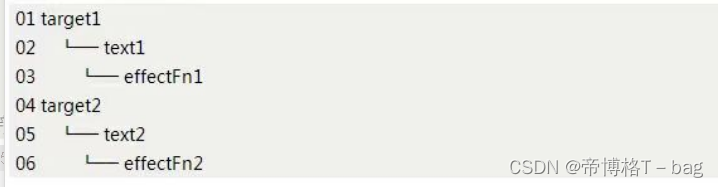
总之,其实就是一个树型结构。如图所示,如果设置了obj2.text2的值,就只会触发 effectFn2 函数的重新执行,并不会导致effectFn1函数重新执行。
3-1 设置新桶的数据结构
// 存储副作用函数的桶
const bucket = new WeakMap()
3-2 修改get/set拦截器代码
在JavaScript中,WeakMap是一种特殊的Map数据结构,它的键只能是对象,并且对于键引用的对象是弱引用。这意味着,如果一个键引用的对象在其他地方没有被引用,那么它将会被垃圾回收。
在JavaScript中,Map是一种键值对的数据结构,它可以用来存储和操作各种类型的值
在JavaScript中,Set是一种集合数据结构,它允许存储不重复的值。
const obj = new Proxy(data, {
// 拦截读取操作
get(target, key) {
// 没有 activeEffect,直接return
if(!activeEffect) return target[key]
// 根据target 从"桶"中取得depsMap, 它也是一个Map类型: key => effects
let depsMap = bucket.get(target)
// 如果不存在depsMap,那么新建一个map并与target关联
if(!depsMap) {
bucket.set(target, (
depsMap = new Map()
))
}
// 再根据key 从depsMap中取得deps,它是一个Set类型
// 里面存储着所有与当前key相关联的副作用函数effects
let deps = depsMap.get(key)
// 如果deps不存在,同样新建一个Set 并与key关联
if(!deps) {
depsMap.set(key, (
deps = new Set()
))
}
// 最后将当前激活的副作用函数添加到"桶"里
deps.add(activeEffect)
// 返回属性值
return target[key]
},
// 拦截设置操作
set(target, key, newVal) {
// 设置属性值
target[key] = newVal
// 根据target从桶中取得depsMap, 它是key --> effects
const depsMap = bucket.get(target)
if (!depsMap) return
// 根据key 取得所有副作用函数effects
const effects = depsMap.get(key)
// 执行副作用函数
effects && effects.forEach (fn => fn())
}
})
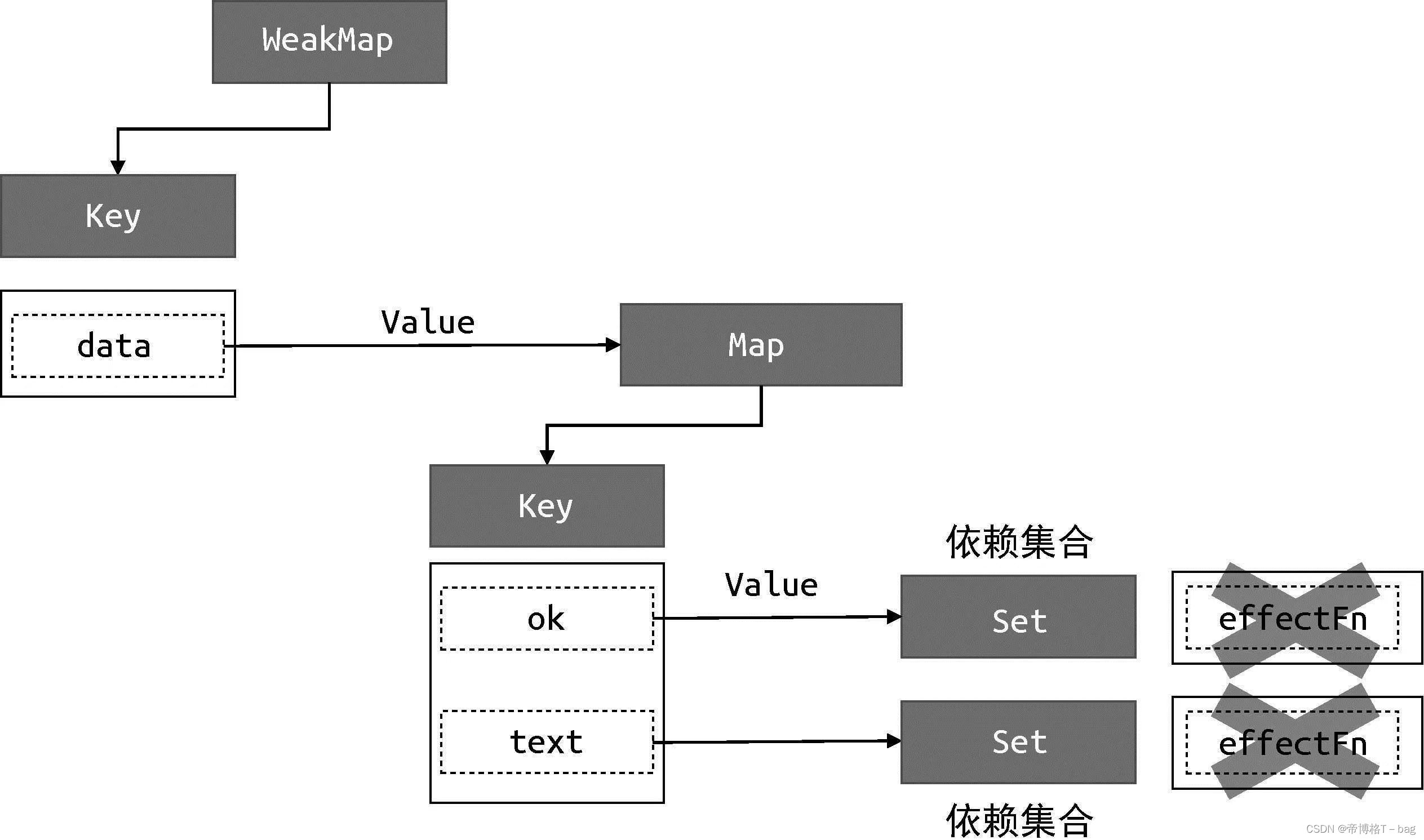
从这段代码可以看出构建数据结构的方式,分别使用了WeakMap、Map 和Set
WeakMap 由 target --> Map 构成
Map由 key --> Set 构成
- 其中WeakMap的键是原始对象target, WeakMap的值是一个Map 实例
- 而Map的键是原始对象target的key,Map的值是一个由副作用函数组成的Set
它们的关系如下图

为了方便描述,上图中的Set数据结构所存储的副作用函数集合称为key的依赖集合
4. WeakMap和Map的区别
const map = new Map();
const weakmap = new WeakMap();
(function (){
const foo = {foo: 1};
const bar = {bar: 2};
map.set(foo, 1);
weakmap.set(bar, 2);
})()
foo 和 bar,这个两个对象,分别作为map和weakmap的key, 当该函数表达式执行完毕后。
对于foo 对象来说,它还是作为map的key被引用, 不会把它从内存中移除。
对于bar对象来说,weakmap的key是弱引用,不影响垃圾回收机制,一旦key被垃圾回收器回收,那么对应的键和值就访问不到了。
所以WeakMap经常用于存储哪些只有当key所引用的对象存在时才有价值的信息,例如上述场景,如果target对象没有任何引用了,这时垃圾回收器会完成回收任务。
总结:WeakMap适用于需要存储临时数据或私有数据,不会影响垃圾回收的场景;而Map适用于需要持久存储的数据,不会被垃圾回收。
5. 封装追踪函数track和触发函数trigger
把get拦截函数中,把副作用函数收集到“桶”中,封装成track函数,表示追踪
把set拦截函数中,副作用函数重新执行的逻辑,封装成trigger函数,表示触发
// 用一个全局变量存储被注册的副作用函数
let activeEffect
// effect 函数用来注册副作用函数
function effect(fn) {
// 当调用effect注册副作用函数时,将副作用函数fn赋值给activeEffect
activeEffect = fn
// 执行副作用函数
fn()
}
// 存储副作用函数的桶
const bucket = new WeakMap()
// 原始数据
const data = {text: 'hellowold'}
const obj = new Proxy(data, {
// 拦截读取操作
get(target, key) {
// 将副作用函数activeEffect 添加到存储副作用函数的桶中
track(target, key)
// 返回属性值
return target[key]
},
// 拦截设置操作
set(target, key, newVal) {
// 设置属性值
target[key] = newVal
// 把副作用函数从桶里取出来并执行
trigger(target, key)
}
})
// 在get拦截函数内调用track函数追踪变化
function track(target, key) {
// 没有activeEffect, 直接return
if(!activeEffect) return
let depsMap = bucket.get(target)
if(!depsMap) {
bucket.set(target, (
depsMap = new Map()
))
}
let deps = depsMap.get(key)
if (!deps) {
depsMap.set(key, (
deps = new Set()
))
}
deps.add(activeEffect)
}
// 在set 拦截函数内调用trigger函数触发变化
function trigger (target, key) {
const depsMap = bucket.get(target)
if (!depsMap) return
const effects = depsMap.get(key)
effects && effects.forEach(fn => fn())
}
effect (
// 一个匿名的副作用函数
() => {
console.log('effect run')
document.body.innerHTML = obj.text
}
)
// 1秒后修改响应式数据
setTimeout (() => {
obj.text = 'hello vue3'
}, 1000)
6. 新知识与旧知识关联
新桶的数据结构 与 ?
7. 转换表述
WeaKMap 就像是一个购物中心, 购物中心的key就是所有店铺的分类,比如美食、购物、亲子、休闲娱乐等。
购物中心的Value(Map)就是某一类所有的店铺集合,比如,美食类:臭臭火锅、鲍师傅、木屋烧烤等。
店铺集合的key就是一个具体店铺的名称,比如,木屋烧烤
店铺集合的Value 就是你想吃这家店的什么食物,比如,一打生蚝、两个香辣猪蹄、10串牛板筋、一扎啤酒等等(set依赖集合)
吃完饭后,消消食,陪老婆逛街买衣服
MeakMap的Key和Value(Map)
找到服装类:歌莉娅、古驰、热风、爱依服、等等
摸了摸口袋,拉着老婆走进热风
坐在店铺凳子打完一把王者后,老婆兴高采烈的提着大包小包的袋子,跟我说买好了
Map的Key 和 Value (Set)
热风:购买的物品
总结:新桶的数据结构,就是一次周末的购物之旅。

,
四、分支切换与cleanup
1. 分支切换
const data = {
ok: true,
text: 'hello world'
}
const obj = new Proxy(data, {/*...*/})
effect(function effectFn() {
document.body.innerHTML = obj.ok ? obj.text : 'not'
})
在effectFn 函数内部存在一个三元表达式,根据字段obj.ok值的不同会执行不同的代码分支。
当字段obj.ok的值发生变化时,代码执行的分支会跟着变化,这就是所谓的分支切换。
总结:分支切换就是对象的字段发生变化时,所关联的副作用函数也发生了变化
分支切换可能会产生遗留的副作用函数。拿上面这段代码来说,字段 obj.ok 的初始值为 true,这时会读取字段 obj.text 的值,所以当 effectFn 函数执行时会触发字段 obj.ok 和字段 obj.text 这两个属性的读取操作,此时副作用函数 effectFn 与响应式数据之间建立的联系如下:

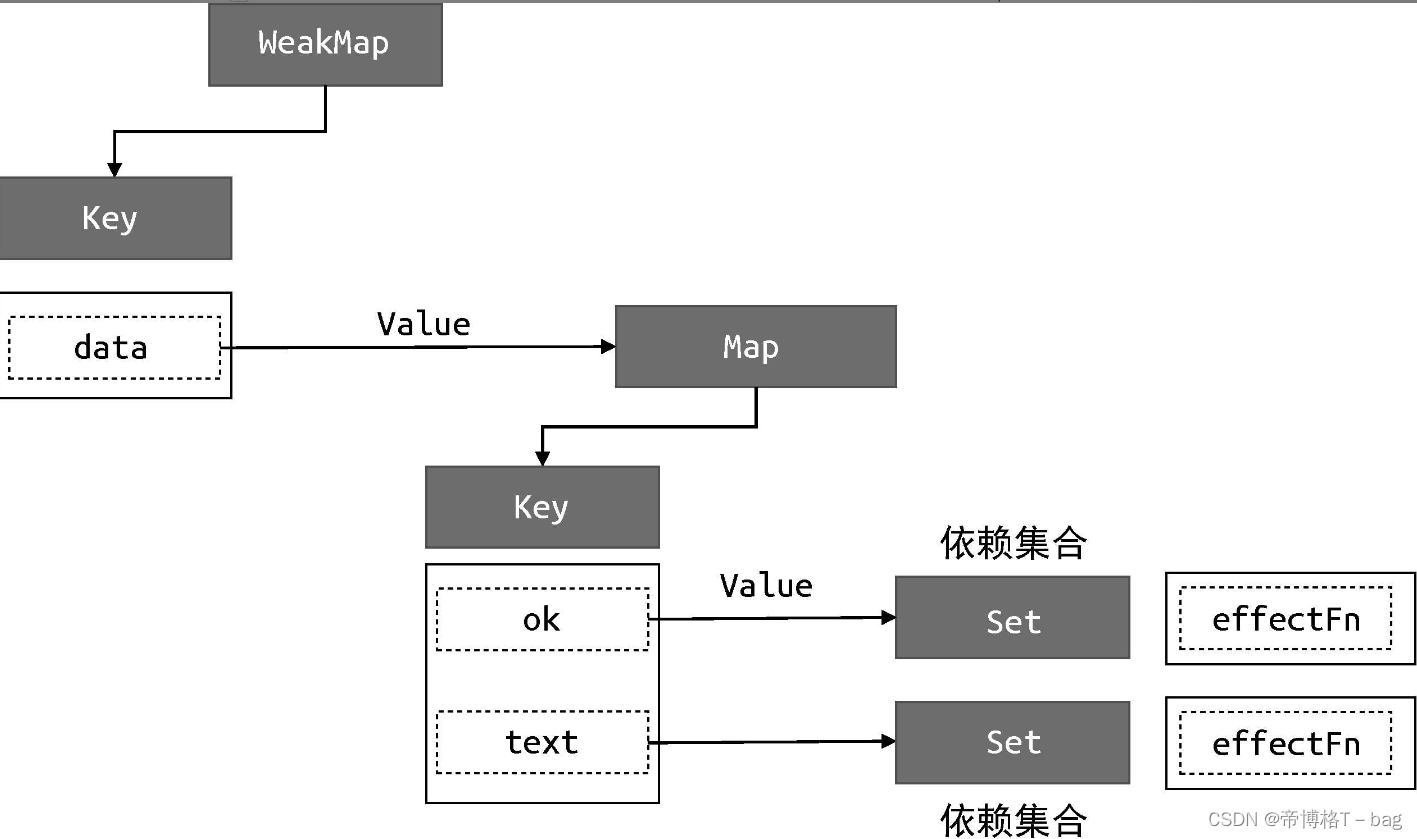
可以看到,副作用函数 effectFn 分别被字段 data.ok 和字段 data.text 所对应的依赖集合收集。当字段 obj.ok 的值修改为 false,并触发副作用函数重新执行后,由于此时字段 obj.text 不会被读取,只会触发字段 obj.ok 的读取操作,所以理想情况下副作用函数 effectFn 不应该被字段 obj.text 所对应的依赖集合收集,理想情况下如下图
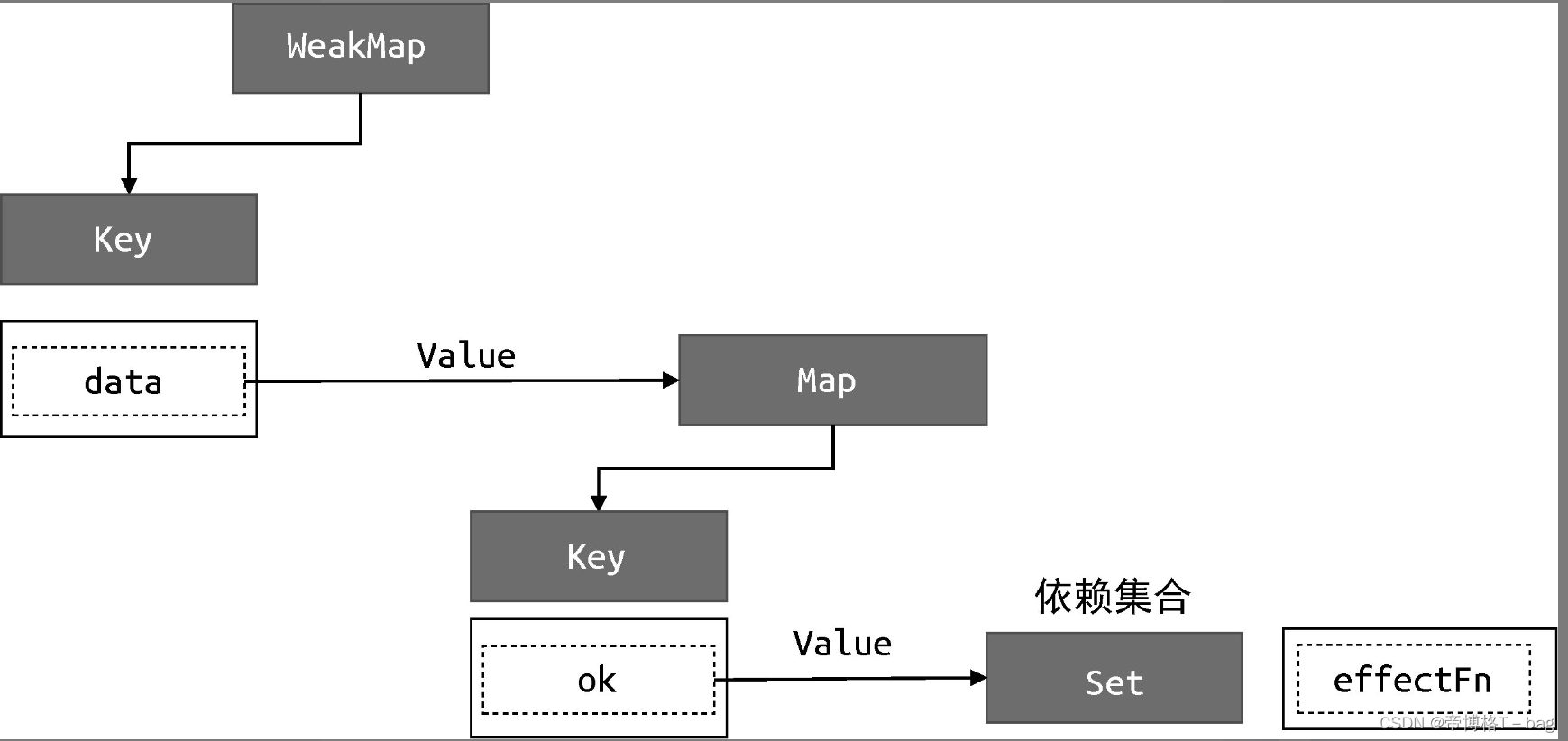
实际情况是,在做分支切换时,会产生了遗留的副作用函数(obj.text 的effectFn),如果我们尝试修改obj.text的值
obj.text = 'hello vue3'
就会导致副作用函数重新执行, 即使document.body.innerHTML 的值不需要变化
总结:分支切换时,产生遗留的副作用函数
1-1 新知识与旧知识关联
分支切换和定时器
分支切换时,产生遗留的副作用函数
定时器执行后,产生了内存的消耗
本质上:完成某个功能后,都产生一定副作用
let count = 0;
function delayedIncrement() {
count++;
console.log(count);
}
setTimeout(delayedIncrement, 1000);
1-2 表达转述
分支切换就像吃饭,吃完后,总会留下一片狼藉。

2.cleanup
解决问题的思路:每次副作用函数执行时,我们可以先把它从所有与之关联的依赖集合中删除
当副作用函数执行完毕后,会重新建立联系,但在新的联系中不会包含遗留的副作用函数。
要将一个副作用函数从所有与之关联的依赖集合中移除,就需要明确知道哪些依赖集合中包含它,因此我需要重新设计副作用函数。
在effect内部我们定义了新的effectFn函数,并为其添加了effectFn.deps属性,该属性是一个数组,用来存储所有包含当前副作用函数的依赖集合
// 用一个全局变量存储被注册的副作用函数
let activeEffect
function effect(fn) {
const effectFn = () => {
// 当effectFn 执行时,将其设置为当前激活的副作用函数
activeEffect = effectFn
fn()
}
// activeEffect.deps 用来存储所有与该副作用函数相关联的依赖集合
effectFn.deps = []
// 执行副作用函数
effectFn()
}
effectFn.deps 数组如何收集依赖集合
function track(target, key) {
// 没有activeEffect return
if (!activeEffect) return
let depsMap = bucket.get(target)
if(!depsMap) {
bucket.set(target, (
depsMap = new Map()
))
}
let deps = depsMap.get(key)
if (!deps) {
depsMap.set(key, (
deps = new Set()
))
}
// 把当前激活的副作用函数添加到依赖集合deps中
deps.add(activeEffect)
// deps 就是一个与当前副作用函数存在联系的依赖集合
// 将其添加到activeEffect.deps数组中
activeEffect.deps.push(deps) // 新增
}
上述代码,在track函数中我们将当前执行的副作用函数activeEffect添加到依赖集合deps中,这说明deps就是一个与当前副作用函数存在联系的依赖集合,于是我们也把它添加到activeEffect.deps数组中,这样就完成了对依赖集合的收集。

有了这个联系后,我们就可以在每次副作用函数执行时,根据effectFn.deps获取所有相关联的依赖集合,进而将副作用函数从依赖集合中移除:
// 用一个全局变量存储被注册的副作用函数
let activeEffect
function effect (fn) {
const effectFn = () => {
// 调用 cleanup 函数完成清除工作
cleanup(effectFn) // 新增
activeEffect = effectFn
fn()
}
effectFn.deps = []
effectFn()
}
cleanup的函数的实现
function cleanup(effectFn) {
遍历effectFn.deps数组
for (let i =0; i <effectFn.deps.length; i++) {
// deps 是依赖集合
const deps = effectFn.deps[i]
// 将effectFn从依赖集合中移除
deps.delete(effectFn)
}
// 最后需要重置 effectFn.deps数组
effectFn.deps.length = 0
}
cleanup 函数接受副作用函数作为参数,遍历副作用函数的effect.deps数组,该数组的每一项都是一个依赖集合,然后将该副作用函数从依赖集合中移除,最后重置effectFn.deps数组
整合代码测试
// 用一个全局变量存储被注册的副作用函数
let activeEffect
function effect (fn) {
const effectFn = () => {
// 调用 cleanup 函数完成清除工作
cleanup(effectFn)
// 新增
activeEffect = effectFn
fn()
}
effectFn.deps = []
effectFn()
}
function cleanup(effectFn) {
// 遍历effectFn.deps数组
for (let i =0; i <effectFn.deps.length; i++) {
// deps 是依赖集合
const deps = effectFn.deps[i]
// 将effectFn从依赖集合中移除
deps.delete(effectFn)
}
// 最后需要重置 effectFn.deps数组
effectFn.deps.length = 0
}
// 存储副作用函数的桶
const bucket = new WeakMap()
// 原始数据
const data = {text: 'hellowold'}
const obj = new Proxy(data, {
// 拦截读取操作
get(target, key) {
// 将副作用函数activeEffect 添加到存储副作用函数的桶中
track(target, key)
// 返回属性值
return target[key]
},
// 拦截设置操作
set(target, key, newVal) {
// 设置属性值
target[key] = newVal
// 把副作用函数从桶里取出来并执行
trigger(target, key)
}
})
// 在get拦截函数内调用track函数追踪变化
function track(target, key) {
// 没有activeEffect return
if (!activeEffect) return
let depsMap = bucket.get(target)
if(!depsMap) {
bucket.set(target, (
depsMap = new Map()
))
}
let deps = depsMap.get(key)
if (!deps) {
depsMap.set(key, (
deps = new Set()
))
}
// 把当前激活的副作用函数添加到依赖集合deps中
deps.add(activeEffect)
// deps 就是一个与当前副作用函数存在联系的依赖集合
// 将其添加到activeEffect.deps数组中
activeEffect.deps.push(deps) // 新增
}
// 在set 拦截函数内调用trigger函数触发变化
function trigger (target, key) {
const depsMap = bucket.get(target)
if (!depsMap) return
const effects = depsMap.get(key)
effects && effects.forEach(fn => fn())
}
effect (
// 一个匿名的副作用函数
() => {
console.log('effect run')
document.body.innerHTML = obj.text
}
)
// 1秒后修改响应式数据
setTimeout (() => {
obj.text = 'hello vue3'
}, 1000)
如果你尝试运行代码,会发现目前的实现会导致无限循环执行,问题出现在trigger函数中,
在trigger函数内部,我们遍历effects集合,它是一个set集合,里面存储着副作用函数。
当副作用函数执行时,会调用clean进行清除,实际上就是从effects集合中将当前执行的副作用函数剔除,但是副作用函数的执行会导致重新被收集到集合中,而此时对于effects集合的遍历仍在进行。
简短代码表达如下:
const set = new Set([1])
set.forEach(item => {
set.delete(1)
set.add(1)
console.log('遍历中')
})
语言规范中对此有明确的说明:
在遍历forEach遍历Set集合时,如果一个值已经被访问过了,但该值被删除并重新添加到集合,如果此时forEach遍历没有结束,那么该值会重新被访问。因此上述代码会无限执行。
解决方法:新建一个Set集合并遍历它
const set = new Set([1])
const newSet = new Set(set)
newSet.forEach(item => {
set.delete(1)
set.add(1)
console.log('遍历中')
})
回到trigger函数,用同样的手段来避免无限执行
function trigger(target, key) {
cosnt depsMap = bucket.get(target)
if(!depsMap) return
const effects = depsMap.get(key)
const effectsToRun = new Set(effects)
// 新增
effectsToRun.forEach(effectFn => effectFn())
// 删除
// effects && effects.forEach(effectFn => effectFn())
}
新增一个effectsToRun集合并遍历它,代替直接遍历effects集合,从而避免无限执行。
2-1 新知识与旧知识关联
cleanup 和 clearTimeout 清除定时器
cleanup 清除遗留的副作用函数,避免执行不必要的代码
clearTimeout 清除定时器,释放内存
本质上:都是清除代码执行后的副作用
let count = 0;
let timer= null;
function delayedIncrement() {
count++;
console.log(count);
clearTimeout(timer);
}
timer = setTimeout(delayedIncrement, 1000);
2-2 表达转述
cleanup 就是饭后收拾桌子

五、嵌套的effect 与effect栈
1. 嵌套的effect
effect 是可以发生嵌套的,例如:
effect(function effectFn1 () {
effect(function effectFn2() {
/*...*/
})
/*...*/
})
实际例子:
// Foo 组件
const Foo = {
render() {
return /*...*/
}
}
在一个effect中执行Foo组件的渲染函数:
effect(() => {
Foo.render()
})
当组件发生嵌套时,例如Foo组件渲染了Bar组件:
// Bar 组件
const Bar = {
render () {
/*...*/
}
}
// Foo组件渲染了Bar组件
const Foo = {
render() {
return <Bar /> // jsx语法
}
}
此时就发生了effect嵌套,它相当于
effect(() => {
Foo.render()
// 嵌套
effect(() => {
Bar.render()
})
})
这个例子说明了为什么effect要设计成可嵌套的
我们需要搞清楚,如果effect不支持嵌套会发生什么,用下面代码进行测试
// 原始数据
const data = {
foo: true,
bar: true
}
// 代理对象
const obj = new Proxy(data, {/*...*/})
// 全局变量
let temp1, temp2
// effectFn1 嵌套了effectFn2
effect( function effectFn1() {
console.log('effectFn1 执行')
effect(function effectFn2 () {
console.log('effectFn2 执行')
// 在effectFn2 中读取obj.bar属性
temp2 = obj.bar
})
// 在effectFn1 中读取obj.foo属性
temp1 = obj.foo
})
上述代码中,effectFn1内部嵌套了effectFn2,很明显effectFn1的执行会导致effectFn2的执行。
需要注意的是,我们在effectFn2中读取了字段obj.bar,在effectFn1中读取了字段obj.foo,并且effectFn2的执行先于字段obj.foo的读取操作。在理想的情况下,我们希望副作用函数与对象属性之间的联系如下:

在这种情况下,我们希望当修改obj.foo 时会触发effectFn1 执行。由于effectFn2嵌套在effectFn1里,所以会间接触发effectFn2执行,而当修改obj.bar时,只会触发effectFn2执行。
但结果不是这样的,我们尝试修改 obj.foo的值,会发现输出为:
effectFn1 执行
effectFn2 执行
effectFn2 执行
一共打印了三次,前两次分别是副作用函数effectFn1 与 effectFn2 初始执行的打印结果,
第三次打印,我们修改了字段obj.foo的值,发现effectFn1 并没有重新执行,反而使得effectFn重新执行了,这显然不符合预期。
其实问题就出在我们实现的effect函数与activeEffect上,观察下面这段代码
// 用一个全局变量存储当前激活的effect函数
let activeEffect
function effect(fn) {
const effectFn = () => {
clearnup(effectFn)
// 当调用effect注册副作用函数时,将副作用函数赋值给activeEffect
activeEffect = effectFn
fn()
}
// activeEffect.deps 用来存储所有与该副作用函数相关的依赖集合
effectFn.deps = []
// 执行副作用函数
effectFn()
}
我们用全局变量activeEffec来存储通过effect函数注册的副作用函数,这意味着同一时刻activeEffect所存储的副作用函数只能有一个。
当副作用函数发生嵌套事,内层副作用函数的执行会覆盖activeEffect的值,并且永远不会恢复到原来的值。这时如果再有响应式数据进行依赖收集,即使这个响应式数据是在外层副作用函数也都会是内层副作用函数,这就是问题所在。
1-1. 新知识与旧知识关联
嵌套的effect 和 接口依赖嵌套
本质上:只有一个入口,先执行外层方法,再执行内层方法
1-2. 表达转述
嵌套的effect 就像俄罗斯套娃,大娃套小娃,一层接一层。

2. effect栈
为了解决这个问题,我需要一个副作用函数栈effectStack,在副作用函数执行时,将当前副作用函数压入栈中,待副作用函数执行完毕后将其从栈中弹出,并始终让activeEffect指向栈顶的副作用函数。
这样就能做到一个响应式数据只会收集直接读取其值的副作用函数,而不会出现互相影响的情况,代码如下:
// 用一个全局变量存储当前激活的effect 函数
let activeEffect
// effect栈
const effectStack = [] // 新增
function effect(fn) {
const effectFn = () => {
cleanup(effectFn)
// 当调用effect注册副作用函数时,将副作用函数赋值给activeEffect
activeEffect = effectFn
// 在调用副作用函数之前将当前副作用函数压入栈中
effectStack.push(effectFn) // 新增
fn()
// 在当前副作用函数执行完毕后,将当前副作用函数弹出栈,并把activeEffect 还原为之前的值
effectStack.pop() // 新增
activeEffect = effectStack[effectStack.length - 1] // 新增
}
// activeEffect.deps 用来存储所有与该副作用函数相关的依赖集合
effectFn.deps = []
// 执行副作用函数
effectFn()
}
activeEffect没有变化,它仍然指向当前正在执行的副作用函数。不同的是当前执行的副作用函数会被压入栈顶,这样当副作用函数发生嵌套时,栈低存储的就是外层副作用函数,而栈顶存储的则是内层副作用函数,下图所示
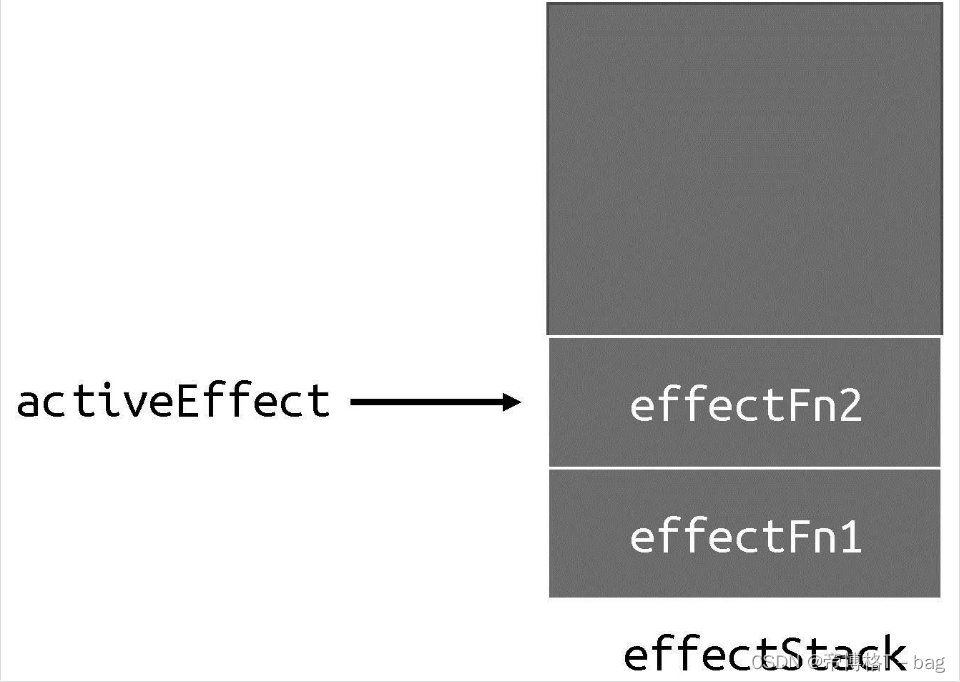
当内层副作用函数EffectFn2 执行完毕后,它会被弹出栈,并将副作用函数effectFn1 设置为activeEffect,如图所示

响应式数据就只会收集直接读取其值的副作用函数作为依赖,从而避免发生错乱。
2-1. 新知识与旧知识关联
effect栈 和任务队列
本质上:都是把多个任务按顺序排列执行
2-2. 表达转述
effect栈像极了排队上班的我们

六、避免无限递归循环
1. 无限递归循环的例子
cosnt data = {foo: 1}
const obj = new Proxy(data, {/*...*/})
effect(() => obj.foo++)
在effect注册的副作用函数内有一个自增操作obj.foo++,该操作会引起栈溢出:
Uncaught RangeError: Maxim um call stack size exceeded
effecy(() => {
// 语句
obj.foo = obj.foo +1
})
2.分析原因:
- 这个语句,即会读取obj.foo的值,又会设置obj.foo的值,这是导致问题的根本原因
3.分析代码执行流程:
- 首先读取obj.foo的值,这会触发track操作,将当前副作用函数收集到"桶"中
- 接着将其加1后再赋值给obj.foo,此时会触发trigger操作,即把"桶"中的副作用函数取出并执行。
- 但问题是该副作用函数正在执行中,还没有执行完毕,就要开始下一次的执行。
- 这样会导致无限递归地调用自己,于是就产生了栈溢出。
4. 解决方案
分析逻辑:
- 读取和设置操作是在同一个副作用函数内进行的。此时无论是track时收集的副作用函数,还是trigger时要触发执行副作用函数,都是activeEffect.
- 如果trigger触发执行的副作用函数与当前正在执行的副作用函数相同,则不触发执行
function trigger (target, key) {
const depsMap = ducket.get(target)
if (!depsMap) return
const effects = depsMap.get(key)
const effectsToRun = new Set()
effects && effects.forEach(effectFn => {
// 如果trigger触发执行的副作用函数与当前正在执行的副作用函数相同,则不触发执行
if (effectFn !== activeEffect) {
effectsToRun.add(effectFn)
}
})
effectsToRun.forEach(effectFn => effectFn())
// effects && effects.forEach(effectFn => effectFn())
}
5. 新知识与旧知识关联
无限递归循环 和 无限for循环
本质上:都没有循环截止点,最终导致内存溢出
6. 表达转述
无限递归循环就像一个人在循环跑道跑步,永远没有终点。
思维导图总结

因篇幅原因,后面还有较多知识点没有深入讲解,有兴趣的小伙伴可以深入了解一下。
如调度执行、计算属性computed与lazy、watch的实现原理、立即执行的watch与回调执行时机、过期的副作用等。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!