AI大模型:无需训练让LLM支持超长输入
显式搜索: 知识库外挂
paper: Unleashing Infinite-Length Input Capacity for Large-scale Language Models with Self-Controlled Memory System
看到最无敌的应用,文本和表格解析超厉害https://chatdoc.com/?viaurl=ainavpro.com
ChatGPT代码实现: GitHub - arc53/DocsGPT: GPT-powered chat for documentation, chat with your documents
适用于大规模知识问答场景
这块可能是GPT后比较火的方向,有一阵每天都能看到类似的新应用,从GPT读论文,再到百科问答,搭配langchain框架,在DocQA,KBQA的场景简直无往不利, 以上分别给出了基于ChatGPT和ChatGLM的两个实现方案。
实现的步骤基本可以被下图概括

-
长文本解析切分成chunk: 实际使用过程中发现文本解析竟然是最核心的部分,能否把需要保留语义完整性的段落拆成整段,能否高质量的解析表格,和结构化数据,对后续QA的影响最大
-
文本向量化:中文可用的embedding模型有不少,也可以基于simcse,consert在垂直领域做进一步的微调。在向量化阶段主要的问题是文本截断带来的上下文损失会影响召回,因此可以尝试重叠切分,拼接摘要/标题等方式
-
向量入库:需要高效向量检索的数据库,Milvus、Pinecone,这块最近也火了一波初创公司
-
用户问题改写:在多轮QA的场景,对话历史有两种使用方式,其一使用历史对话对当前query进行改写再召回,其二种是使用原始用户query去召回文本,在回复阶段引入对话历史
-
召回:基于用户query或改写query进行向量化检索,topK或者阈值召回。除了考虑相关性,在部分场景也要考虑时效性,文本质量等等
-
答案生成:使用召回文档拼接用户query进行答案生成,这一步往往还需要用到模型摘要,Refine等能力,核心是对以上召回的长文本进行压缩
搜索法最大的优点是实现简单,不过也有许多限制就是只能支持NLU任务,以及会破坏输入文本的上下文连续性,和文本顺序。但在大规模知识问答这块算是现在看到最好的方案。
隐式搜索:Unlimiformer
Unlimiformer: Long-Range Transformers with Unlimited Length Input
适用于Encoder-Decoder模型,长文本摘要等场景
特意起了个隐式搜索的标题,是因为和上面的文本搜索实现有异曲同工之妙,本质的差异只是以上是离散文本块的搜索。而Unlimiformer是在解码阶段对超长输入,token粒度的输出层embedding进行检索,选择最相关的Top Token计算Attention。
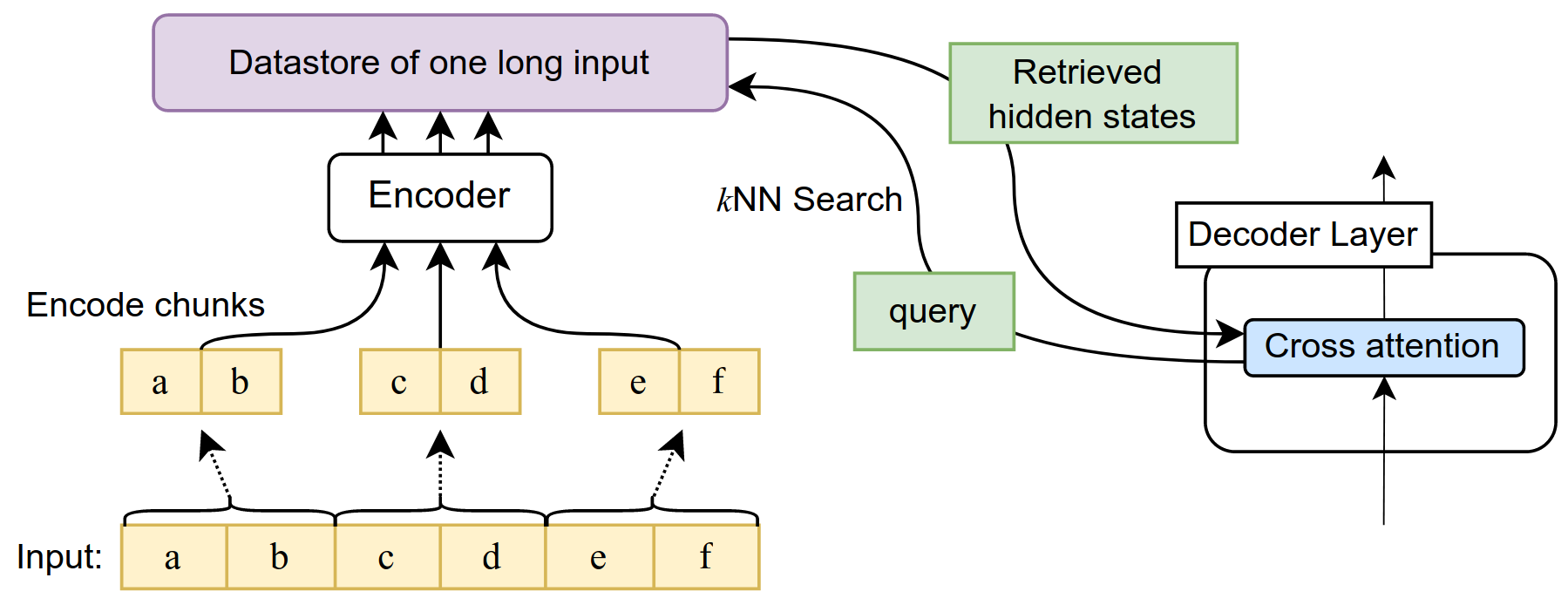
首先对于超长输入,unlimiformr采用以上提到的重叠切分的方法,重叠率50%,这样可以更好保留上文和文本连贯性,例如第一段文本是1-500字,第二段重叠250字取250-750字。然后使用Encoder对每段文本进行独立编码,绕过Attention的平方复杂度问题。最后输出每段文本的Embedding,注意这里不是文本整体embedidng, 而是后半部分(250~500字)每个Token最上层的Embedding,并写入向量索引,这里用的是Faiss。
在解码层,每一步解码,query都会检索注意力最高的Top-k个输入Token,作为编码器部分的信息用于解码器的解码。这里简单回忆下Attention计算, Top-K个Token就是让以下注意力取值最高的key。
考虑Decoder的每一层(N层)中的每一个head(L个头)都需要和Encoder的输出层进行交互, 检索Top Key,如果存储每一层每个head的Key,需要构建O(L?N?seqlen)的向量存储。对此作者进行了优化,改变了以下QK的计算顺序,用每一层每个头Key的映射矩阵对Q进行映射,这样只需要存储一份seq_len的编码向量(hencoder?,在每一层检索时用映射后的Q进行检索既可,其实就是时间换空间
unlimiformer提供了代码实现,核心代码抽出来看下有两块
-
超长文本编码:对文本进行切块,分别编码,取后半部分
for context_start_ind, context_end_ind, update_start_ind, update_end_ind in window_indices:
? ?chunk = input_ids[:, context_start_ind:context_end_ind]
? ?chunk_attention_mask = attention_mask[:, context_start_ind:context_end_ind]
? ?hidden_states = self.model(chunk, attention_mask=chunk_attention_mask, labels=dummy_labels, return_dict=True)
? ?last_hidden = hidden_states.encoder_last_hidden_state # (batch, chunked_source_len, dim)
? ?to_add = last_hidden[:, update_start_ind:update_end_ind].detach()
? ?to_apply_mask = chunk_attention_mask[:, update_start_ind:update_end_ind]-
向前计算检索Top-key用于Attention矩阵的计算
def attention_forward_hook(self, module, input, output):
? ?# output: (batch, time, 3 * heads * attention_dim)
? ?with torch.no_grad():
? ? ? ?query = self.process_query(output)[:,-1] # (batch * beam, head, dim)
? ? ? ?query = query[:, self.head_nums] # (batch * beam, head, dim)
?
? ? ? ?#这是前面提到的计算优化使用每层每个head的Key映射矩阵对Query进行映射用于搜索
? ? ? ?attention_layer_list = self.attention_layer_to_capture(self.layer_begin, self.layer_end)
? ? ? ?k_proj_layer = [layers[0] for layers in attention_layer_list][self.cur_decoder_layer_index]
? ? ? ?# modify query by k_projs
? ? ? ?k_proj = k_proj_layer.weight
? ? ? ?k_proj = k_proj.view(1, self.num_heads, query.shape[-1], k_proj.shape[0]) # (1, num_heads, attn_dim, embed_dim)
? ? ? ?datastore_query = query.unsqueeze(-2) # (batch * beam, num_heads, 1, attn_dim)
? ? ? ?datastore_query = torch.matmul(datastore_query, k_proj) # (batch * beam, num_heads, 1, embed_dim)
? ? ? ?datastore_query = datastore_query.squeeze(-2) ?# (batch * beam, num_heads, embed_dim)
? ? ? ?datastore_query = datastore_query.view((self.datastore.batch_size, -1, datastore_query.shape[2])) # (batch, beam * num_heads, embed_dim)
? ? ? ?
? ? ? ?# 这里进行Top Key的检索:得到Key的索引,Embedding和得分
? ? ? ?top_search_key_scores, top_search_key_indices = self.datastore.search(datastore_query, k=self.actual_model_window_size)
? ? ? ?embeddings = torch.take_along_dim(input=self.embeddings.unsqueeze(1),
? ? ? ?indices=top_search_key_indices.unsqueeze(-1).to(self.embeddings.device), dim=-2)
?
? ? ? ?##后面就是常规的对Embedding进行Key和Value的映射然后做Attention了和前面的文本检索对比,unlimiformer的存储成本会更高,因为要存储token粒度的Embedding信息,更适用于on-the-fly的长文本推理使用,例如针对单一文档的QA,只存储当前文档,而前面文本块检索方案更适合一些大规模知识,批量的文档的存储。
但其实unlimiformer直接对Token进行离散召回,这一点我让我有些困惑,这样单一token的检索召回,真的不会破坏上文连续性么?还是说Encoder编码方式已经保证了检索召回大概率会召回成段的Token,又或者说每个Token的Embedding内已经充分编码了连续上下文的信息,召回离散Token也不会出现割裂的语义信息?哈哈考虑unlimiformer只支持Encoder-Decoder的框架,和我们用的Decoder框架不适配,我决定不细纠结了!有在中文尝试过效果的童鞋可以分享下~
并行输入:PCW
Parallel Context Windows for Large Language Models
适用于Decoder模型,以及小规模内容理解场景
同样是对超长文本进行切块,然后独立编码,PCW使用的是Decoder框架。和unlimiformer只使用Top-Key进行解码,PCW在解码过程中对全部输入上文进行Attention。对比Encoder-Decoder框架,因为输入和输出都在Decoder侧,PCW需要解决两个问题:位置编码和注意力矩阵如何调整, 下图基本概括了这两个细节
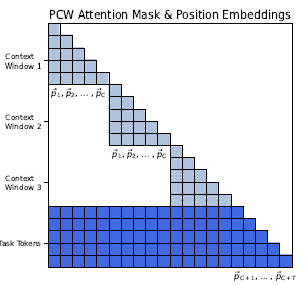
\1. 位置编码:输入文本截断后,每段文本的位置编码相同。考虑所最长的文本长度为C,则输入文本最大的位置编码id是PC,则解码器第一个字的位置编码id是PC+1+1,然后顺序向后编码。其实就是丢弃了上文多段文本之间的位置关系,解码时只知道上文多段文本都是在解码器之前,但无法区分文本之间的位置。不过因为上文每段文本复用了相同的位置编码,因此位置编码的长度大幅降低,也就降低了对位置编码外推性的需求。
position_ids = attention_mask.long().cumsum(-1) - 1
n_task_tokens = position_ids.shape[1] - sum_windows_size
# 保证解码器的位置编码比最长上文要长度+1
position_ids[0, -n_task_tokens:] = torch.arange(max_window_size, max_window_size + n_task_tokens, 1)
position_ids.masked_fill_(attention_mask == 0, 1)
if past_key_values: ?# i.e., first token is already generated
? position_ids = position_ids[:, -1].unsqueeze(-1)
elif windows_key_values: ?# i.e., we are in the first token generation #其实就是取-n_task_tokens:
? position_ids = position_ids[:, sum_windows_size:]-
注意力矩阵
-
输入文本进行截断后各自独立通过Decoder进行编码。因此每一段输入的文本的注意力矩阵是相互独立的。这块不需要修改注意力矩阵的实现,只需要文本chunk后分别过模型即可。得到每段文本的past-key-values直接进行拼接
def combine_past_key_values(past_lst: List[Tuple[Tuple[torch.Tensor]]],
? ? ? ? ? ? ? ? ? ? ? ? ? ?contains_bos_token: bool = True) -> Tuple[Tuple[torch.Tensor]]:
? ?# 这里past_lst是每段文本的past-key-value
? ?# GPT是n_layer * 2(key+value) * tensor(seq_len,batch,n_head,n_hidden)
? ?# 注意不同模型past-key-value的shape不同
? ?# Chatglm是n_layer * 2(key+value) * tensor(seq_len,batch, n_head, n_hidden)
? ?return tuple(
? ? ? (torch.cat([c[i][0] for c in past_lst], dim=2),
? ? ? ?torch.cat([c[i][1] for c in past_lst], dim=2))
? ? ? ?for i in range(len(past_lst[0])))-
解码器对全部上文进行Attention计算:这里需要修改Attention把上文的全部Attention进行拼接,让解码器的每一步可以对全部上文计算Attention
res['past_attention_mask'] = torch.cat([window['attention_mask'] for window in windows], dim=1)
combined_attention_mask = torch.cat((cache['past_attention_mask'], encoded_task_text['attention_mask']), dim=1)考虑ChatGLM本身是二维的Attention矩阵和位置编码,特殊的BOS和GMASK,我重写了PCW,但是在长文本QA问题上表现比较一般,表现在当上文多段文本无明显关系的时候例如多个完全无关的新闻,在进行问答的时候,正确答案中会混杂很多无关的文本变短,以及这个问题当上文片段变多,或者指令问题变多的时候会变得越来越严重,直到开始完全胡说八道。当然不排除我写bug了哈哈哈,但我自己是真的没查出来。
不过也有一种可能,是PCW是在输入层就开始对超长上文进行Attention,因为不同上文的位置编码相同,一定程度上会让解码注意力变得非常分散,导致注意力的熵值变高,解码的不确定性变大,更容易出现乱码。
并行解码:NBCE
苏剑林. (May. 23, 2023). 《NBCE:使用朴素贝叶斯扩展LLM的Context处理长度 》[Blog post]. Retrieved from NBCE:使用朴素贝叶斯扩展LLM的Context处理长度 - 科学空间|Scientific Spaces
苏剑林. (May. 31, 2023). 《关于NBCE方法的一些补充说明和分析 》[Blog post]. Retrieved from 关于NBCE方法的一些补充说明和分析 - 科学空间|Scientific Spaces
适用于Encoder-Decoder模型,长文本内容理解如摘要问答等场景
压轴的必须是苏神的NBCE!这里我把看完博客后的理解进行简单的总结,详细推理请看去苏神的科学空间!答应我一定要去看!每次看苏神推导,都会觉得数学之魂在燃烧!
NBCE的原理简单解释如下图,和PCW相同是对每段上文进行独立编码,但差异在于PCW是在输入层进行融合,而NBCE是在输出层对每一个Step输出的预测token的概率矩阵进行融合,更大程度上避免了注意力被分散,保证了解码的合理性。
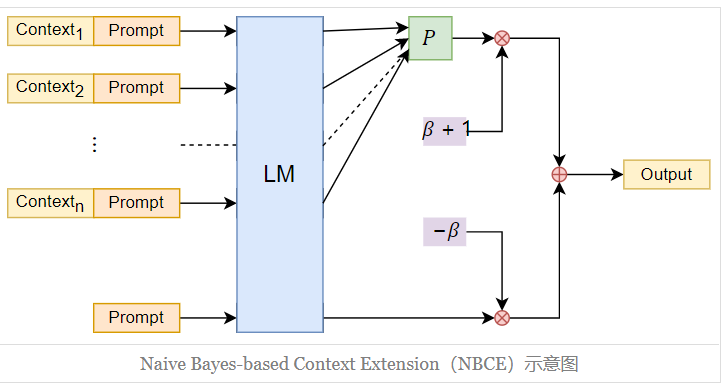
这里我们简单说下如何在输出层进行融合,把找超长文本chunk成多段文本后(s1,s2,...sk1,2,...,基于朴素贝叶斯的简化假设, 基于多段文本进行并行解码的预测概率可以简化如下,也就是每段文本条件解码概率之和减去无条件解码概率
既然说了是简化假设,因此可以对上式进行一些调优,核心是让模型对上文的解码更加准确,降低无关上文带来的解码噪声,比较重要的优化包括
-
准确率优化解码
以上解码概率求和,其实是对k段文本生成的vocab?K的概率矩阵,沿K做AvergePooling,得到最终vocab?1?1的解码概率。但考虑LM训练其实是拟合one-hot(出现概率最高的词),也就是除了概率最高的几个token之外其余token的预测概率都不靠谱。如果直接取平均的多路打分,很容易投出一个在各段文本上打分都不高不低的token,上文越多这个问题越明显。但其实在阅读理解例如抽取,QA问题的解码策略上我们要的是在某段文本上打分置信度最高的token,因为答案往往只来自一个上文片段。
因此苏神给出了两种准确率更高的解码方案,一个是MaxPooling+GreedySearch,其实就是对vocab?k的概率矩阵取全局概率最高的token,另一个是最小熵+RandomSampling,也就是从多段上文中取1个预测置信度最高的上文进行解码。这里其实是和PCW最大的差异,也就是在解码层进行融合,并通过熵值较低的融合策略来保证解码的准确率。
以及后面苏神还通过Top-P来进一步过滤尾部的噪声,以及通过控制每一步解码的转移概率,来让解码器不会在不同上文片段之间反复切换,而是保证连续的解码片段大概率来自相同的上文片段。
-
Context-aware解码
基于上文来进行解码的一个核心是为了降低模型回答胡说八道的概率。例如在金融场景我们直接问chatgpt基金赎回费用是多少 vs 我们基于某个基金的介绍问模型该基金的赎回费用是多少,后者得到的答案一定是更准确的。而其实以上二者的差异在于条件(上文)解码和无条件解码, 因此可以通过diff无条件编码的方式来提高解码对上文的依赖程度(reliablity)。如下图
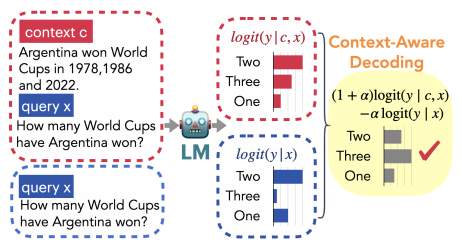
因此苏神把把n变成超参Beta, 控制条件概率和无条件概率的占比,Beta越高解码和上文的关联度越高,QA等场景的解码准确率越高,生成自由度越低。
当前NBCE的局限性在于无法处理上文片段之间的位置关系,以及无法处理解码需要依赖多个上文片段的场景。后者感觉可以通过预测概率矩阵的相关性修改Pooling方式,而前者
基于苏神提供的代码,在chatglm上做了尝试,只需要简单调整下输入输出的部分就可以直接使用。我在论文,书籍,和新闻上进行摘要,实体抽取和QA问答后发现,INT8量化的模型效果似乎要略优于FP16, 显著优于INT4。INT8量化下,10K左右的输入,显存占用基本可以限制在单卡A100(40g),大家可以自行尝试下~
@torch.inference_mode()
def generate(max_tokens):
? ?device = torch.device('cuda')
? ?"""Naive Bayes-based Context Extension 演示代码
? """
? ?inputs = tokenizer(batch, padding='longest', return_tensors='pt').to(device)
? ?input_ids = inputs.input_ids
? ?n = input_ids.shape[0]
?
? ?with torch.no_grad():
? ? ? ?for i in range(max_tokens):
? ? ? ? ? ?# 模型输出
? ? ? ? ? ?model_input = model.prepare_inputs_for_generation(input_ids)
?
? ? ? ? ? ?outputs = model(**model_input,
? ? ? ? ? ? ? ? ? ? ? ? ? ?return_dict=True,
? ? ? ? ? ? ? ? ? ? ? ? ? ?use_cache=True
? ? ? ? ? ? ? ? ? ? ? ? ? )
? ? ? ? ? ?"""
? ? ? ? ? 中间代码不变
? ? ? ? ? """
?
? ? ? ? ? ?# 把唯一的回答扩充到每一个batch进行下一轮的解码
? ? ? ? ? ?next_tokens = next_tokens.unsqueeze(-1).tile(n, 1)
? ? ? ? ? ?input_ids = torch.cat([input_ids, next_tokens], dim=-1)
? ? ? ? ? ?# 更新past-key-values, 更新attention_mask, 更新position_ids
? ? ? ? ? ?model_kwargs = model._update_model_kwargs_for_generation(
? ? ? ? ? ? ? ?outputs, model_kwargs, is_encoder_decoder=model.config.is_encoder_decoder
? ? ? ? ? )本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!