mongodb——概念介绍(文档,集合,固定集合,元数据,常用数据类型)
mongodb
层级结构
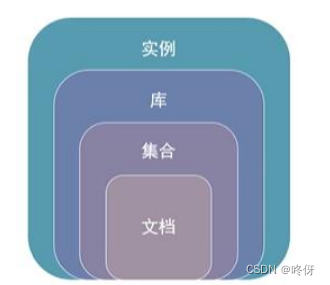
实例:系统上运行的进程及节点集,一个实例可以有多个库,默认端口 27017。
库:多个集合组成数据库,每个数据库都是独立的,有自己的用户、权限信息,独立的存储文件集
合。
集合:即是一组文档的集合,集合内的文档结构可以不同。
文档:MongoDB 的最小数据单元,其基本概念为:多个键值对有序组合在一起的数据单元。示例如
下所示:

基本概念
在 mongodb 中基本的概念是文档、集合、数据库,下面我们挨个介绍。下表将帮助您更容易理解 Mongo 中的一些概念:通过下图实例,我们也可以更直观的了解 Mongo 中的一些概念:
数据库
MongoDB默认数据库为db,存储在data目录中。一个mongoDB实例可以容纳多个独立的数据库,每个数据库都有自己的集合和权限。不同的数据库存储在不同文件中
show dbs #该命令可以显示所有数据库列表
use local #该命令可以切换数据库
数据库的命名有其特定的规则,不过不用深究。
保留的数据库
有一些数据库名是保留的
- admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
- local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
- config: 当 Mongo 用于分片设置时,config 数据库在内部使用,用于保存分片的相关信息。
文档(Document)
文档是一个BSON(一组键值)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。一个
简单的文档例子如下:
{"age":18, "name":"dongya"}
需要注意的是
- 文档中的键/值是有序的
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个
嵌入的文档) - MongoDB 区分类型和大小写。
- MongoDB 的文档不能有重复的键。
- 文档的键是字符串。除了少数例外情况,键可以使用任意 UTF-8 字符。
- 文档对应于许多编程语言中的本机数据类型
- 嵌入式文档和数组减少了对连接的需求(比如一些复杂数据,可以直接嵌套在里面,不用连表查询)
- 动态模式支持流畅的多态性
键的命名规范 - 键不能含有\0 (空字符)。这个字符用来表示键的结尾。
- .和$有特别的意义,只有在特定环境下才能使用。
- 以下划线"_"开头的键是保留的(不是严格要求的)。
集合
集合就是 MongoDB 文档组,类似于 RDBMS (关系数据库管理系统:Relational Database Management
System)中的表格。集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。当文档插入的时候,集合就会被创建
{"site":"www.baidu.com"}
{"site":"www.google.com","name":"Google"}
{"site":"www.google.com","name":"Google", "accessNum":15}
当第一个文档插入时,集合就会被创建。
固定集合 capped collections
Capped collections 就是固定大小的 collection。它有很高的性能以及队列过期的特性(过期按照插入的
顺序). 有点和 “RRD” 概念类似。Capped collections 是高性能自动的维护对象的插入顺序。它非常适
合类似记录日志的功能和标准的 collection 不同,你必须要显式的创建一个 capped collection,指定
一个 collection 的大小,单位是字节。collection 的数据存储空间值提前分配的。Capped collections
可以按照文档的插入顺序保存到集合中,而且这些文档在磁盘上存放位置也是按照插入顺序来保存
的,所以当我们更新 Capped collections 中文档的时候,更新后的文档不可以超过之前文档的大小,
这样话就可以确保所有文档在磁盘上的位置一直保持不变。由于 Capped collection 是按照文档的插
入顺序而不是使用索引确定插入位置,这样的话可以提高增添数据的效率。MongoDB 的操作日志文
件 oplog.rs 就是利用 Capped Collection 来实现的。要注意的是指定的存储大小包含了数据库的头信
息。
db.createCollection("mycoll", {capped:true, size:100000})
- 在 capped collection 中,你能添加新的对象。
- 能进行更新,然而,更新的对象不能增加存储空间。如果增加,更新就会失败 。
- 使用 Capped Collection 不能删除一个文档,可以使用 drop() 方法删除 collection 所有的行。
- 删除之后,你必须显式的重新创建这个 collection。
- 在 32bit 机器中,capped collection 最大存储为 1e9个字节
固定集合可以声明 collection 的容量大小,其行为类似于循环队列。数据插入时,新文档会被插入到
队列的末尾,如果队列已经被占满,那么最老的文档会被之后插入的文档覆盖。
应用场景
日志文件,聊天记录,通话信息记录等只需保留最近某段时间内的应用场景
优点
- 写入速度提升。固定集合中的数据被顺序写入磁盘上的固定空间,所以,不会因为其他集合的一
些随机性的写操作而“中断”,其写入速度非常快(不建立索引,性能更好)。 - 固定集合会自动覆盖掉最老的文档,因此不需要再配置额外的工作来进行旧文档删除。设置 Job
进行旧文档的定时删除容易形成性能的压力。
注意事项
- 固定集合创建之后就不可以改变,只能将其删除重建。
- 普通集合可以使用 convertToCapped 转换固定集合,但是固定集合不可以转换为普通集合。
- 创建固定集合,为固定集合指定文档数量限制时(指参数 max),必须同时指定固定集合的大小(指参数 size)。不管先达到哪一个限制,之后插入的新文档都会把最老的文档移除集合。
- 使用 convertToCapped 命令将普通集合转换固定集合时,既有的索引会丢失,需要手动创建。并且,此转换命令没有限制文档数量的参数(即没有 max 的参数选项)。
- 不可以对 固定集合 进行分片。
- 对固定集合中的文档可以进行更新(update)操作,但更新不能导致文档的 Size 增长或缩小,否
则更新失败。 - 还有一定需要注意,对集合估算 size 时,不要依据集合的 storageSize ,而是依据集合的 size。
storageSize 是 wiredTiger 存储引擎采用高压缩算法压缩后的。
元数据
元数据是一个预留空间,在对数据库或应用程序结构执行修改时,其内容可以由数据库自动更新。元数据是系统中各类数据描述的集合,是执行详细的数据收集与数据分析的主要途径。元数据最重要的作用是作为一个分析阶段的工具,任何字典最重要的操作是查询,在结构化分析中,元数据的作用是给每一个结点加上定义与说明。
数据库的信息是存储在集合中。它们使用了系统的命名空间:
dbname.system.*
| 集合命名空间 | 描述 |
|---|---|
| dbname.system.namespaces | 列出所有名字空间。 |
| dbname.system.indexes | 列出所有索引。 |
| dbname.system.profile | 包含数据库概要(profile)信息。 |
| dbname.system.users | 列出所有可访问数据库的用户。 |
| dbname.local.sources | 包含复制对端(slave)的服务器信息和状态。 |
数据类型
| 数据类型 | 描述 |
|---|---|
| string | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Min/Max/ keys | 将一个值与BSON(二进制的JSON)元素的最低值和最高值相对比 |
| Array | 用于将数组或列表或多个值存储为一个键 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间 |
| Object | 用于内嵌文档 |
| Null | 用于创建空值 |
| Symbol | 符号,基本等同于字符串类型 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的。日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式 |
ObjectId
ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytes,含义是:
- 前 4 个字节表示创建 unix 时间戳,格林尼治时间 UTC 时间,比北京时间晚了 8 个小时
- 接下来的 3 个字节是机器标识码
- 紧接的两个字节由进程 id 组成 PID
- 最后三个字节是随机数

MongoDB 中存储的文档必须有一个 _id 键。这个键的值可以是任何类型的,默认是个 ObjectId 对象,由于 ObjectId 中保存了创建的时间戳,所以你不需要为你的文档保存时间戳字段(当然也看具体业务了),你可以通过getTimestamp 函数来获取文档的创建时间
> var newObject = ObjectId()
> newObject.getTimestamp()
ISODate("2019-09-17T04:42:12Z")
时间戳
BSON 有一个特殊的时间戳类型用于 MongoDB 内部使用,与普通的 日期 类型不相关。 时间戳值是一个 64 位的值。其中:
- 前 32 位是一个 time_t 值(与 Unix 新纪元相差的秒数)
- 后 32 位是在某秒中操作的一个递增的序数
在单个 mongod 实例中,时间戳值通常是唯一的。
日期
表示当前距离 Unix 新纪元(1970 年 1 月 1 日)的毫秒数。日期类型是有符号的, 负数表示 1970 年之前的日期。
> var date1 = new Date() //格林尼治时间
> date1
ISODate("2023-11-17T04:47:39.919Z")
> typeof mydate1
object
> var mydate2 = ISODate() //格林尼治时间
> mydate2
ISODate("2023-11-17T04:48:21.854Z")
> typeof mydate2
object
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!