MySQL数据库索引优化实战
目录
一、前言
在数据库的应用中,性能优化是一个持续不断的过程。其中索引优化是提高查询速度的最有效的方法,本文将通过案例,深入探讨MySQL索引优化,帮助读者理解索引优化、在实际的应用中提升性能。
二、准备工作
在开始优化分析之前,现在准备好三张表TB_USER、TB_SKU、TB_ORDER表。
2.1 用户表(TB_USER)
用户表结构如下

创建表的语句:
CREATE TABLE `tb_user` ?(
? `id` int(0) NOT NULL COMMENT 'id',
? `create_time` datetime(0) NOT NULL COMMENT '创建时间',
? `creator` varchar(20) NOT NULL COMMENT '创建人',
? `user_id` int(0) NOT NULL COMMENT '用户id',
? `user_name` varchar(30) NOT NULL COMMENT '用户名',
? `addr` varchar(300) NULL DEFAULT NULL COMMENT '地址',
? `remark` varchar(200)? NULL DEFAULT NULL COMMENT '备注',
? PRIMARY KEY (`id`) USING BTREE
) ;2.2 商品表(TB_SKU)
表结构如下

创建表的语句
CREATE TABLE `tb_sku` (
`id` int(0) NOT NULL COMMENT 'id',
`create_time` datetime(0) NOT NULL COMMENT '创建时间',
`creator` varchar(20) NOT NULL COMMENT '创建人',
`sku_id` int(0) NOT NULL COMMENT '商品id',
`sku_name` varchar(200) NOT NULL COMMENT '商品名称',
`remark` varchar(200) NULL DEFAULT NULL COMMENT '备注',
PRIMARY KEY (`id`) USING BTREE
);2.3 订单表(TB_ORDER)
表结构如下:

创建表的语句:
CREATE TABLE `tb_order` ?(
? `id` int(0) NOT NULL,
? `create_time` datetime(0) NOT NULL,
? `creator` varchar(20)? NOT NULL,
? `user_id` int(0) NOT NULL,
? `sku_id` int(0) NOT NULL,
`status` varchar(1)? NULL DEFAULT NULL,
? `remark` varchar(200)? NULL DEFAULT NULL,
? PRIMARY KEY (`id`) USING BTREE
) ;三、实例分析
在上一篇文章中介绍了索引的优化策略,最后介绍了查看SQL执行技术的关键字explain,并对explain执行计划的各个字段作了介绍,本文将结合实例对各个字段作详细介绍。
3.1 索引提升查询性能

tb_user表总共有6条数据,一个id主键索引,因此用select * from tb_user where user_id=1;去查询的时候,
1. select_type=SIMPLE,简单查询,因为这是一个单表的查询;
2. type=ALL, type的类型有:NULL、system、const、eq_ref、ref、range、index、all;从左到右,性能逐一降低,all的性能最差,属于全部扫描。
3.filtered=16.67,也就是从全部6条记录中筛选出1条,filtered的值是越大越好。
接下来,给tb_user增加一个user_id的索引,然后再来看执行计划
create index idx_tb_user_user_id on tb_user(user_id); ?
?

从上图的执行计划可以看到,type变成了ref,也就是查询的时候使用了索引;?filtered的值变成了100.00,因此性能得到了很大的提升。
下一步,将idex_tb_user_user_id的索引删除,重新创建唯一索引,再来看执行计划
alter table tb_user drop index idx_tb_user_user_id;
create unique index idx_tb_user_user_id on tb_user(user_id);
?type再次从ref变为了const,性能再次得到了提升。
3.2 多表查询
从tb_user、tb_sku、tb_order三张表中查询用户都买了哪些商品

?查看这个SQL的执行计划

对于id是相同的,从上往下执行。
如果id不同的情况,id越大越先执行,假设通过子查询的方式,查询买了铅笔的人名。

查看以下这个SQL的执行计划

这个的执行顺序,跟我们理解的也是一样,应该先去查询tb_sku,查出sku_id,再根据sku_id查询tb_order表,查询user_id,最后再去查询tb_user表;
3.3 索引失效
1. 不要在索引列上运算,否则索引会失效。在user_id上作了运算之后,索引失效,性能降低。

2. 字符串字段,查询时如果没有加单引号,索引失效
首先,我们在tb_order表的status字段上加上索引,?
create index idx_tb_order_status on tb_order(status);

3.? or连接时,一侧有索引、一侧没有索引,索引失效

4. 数据分布影响,这个可能是我们平时在做索引优化时,会被忽略的一点,之前在实际项目中碰到过类似的情况,后来重要明白是因为数据分布导致的。?
我们先将tb_order表中的status字段全更新为9,然后再来查看执行计划。因为当MySQL评估使用索引比全表更慢,则不使用索引。

另外我们将tb_order的数据分布设置为如下:
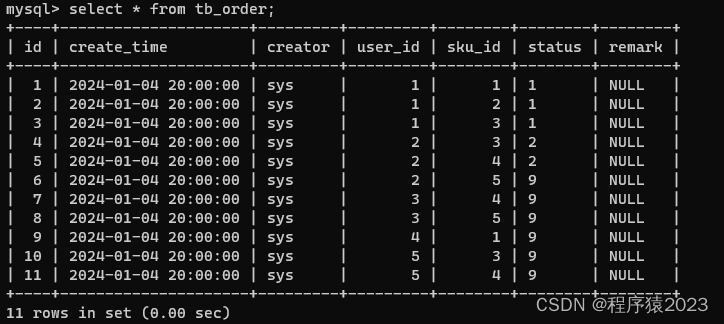
再进行status>='2' 和 status>='0'的查询,会发现status>='2'的时候,会使用索引,而status>='0'的时候,不会使用索引,而执行全表查询。这是因为数据分布影响的。

四、总结
本文根据实际例子介绍了如何提升查询性能、索引失效等问题,索引对于提升查询性能有很大的帮助,但是也不能滥用索引,因为使用索引本身会占用存储空间,影响数据插入和更新的速度。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!