LLM之Prompt(三)| XoT:使用强化学习和蒙特卡罗树搜索将外部知识注入Prompt中,性能超过CoT,ToT和GoT

?论文地址:https://arxiv.org/pdf/2311.04254.pdf
一、当前Prompt技术的局限性
? ? ? ?LLM使用自然语言Prompt可以将复杂的问题分解为更易于管理的“thought”可以回复用户的问题。然而,大多数现有的Prompt技术都有局限性:
- 输入输出(IO)Prompt:仅适用于具有单步解决方案的简单问题,它缺乏灵活性;
- 思维链(CoT):能够解决多步问题,但仅限于线性思维结构,也缺少灵活性;
- 思维树(ToT)和思维图(GoT):允许更灵活的思维结构,如树或图。然而,它们需要LLM来评估中间的thought,由于多次调用LLM会产生巨大的计算成本。

PS:当前的Prompt技术面临“Penrose Triangle”约束——最多可以实现(性能、效率和灵活性)中两个属性,三个属性不能同时实现。
?常见Prompt技术对比,如下图所示:
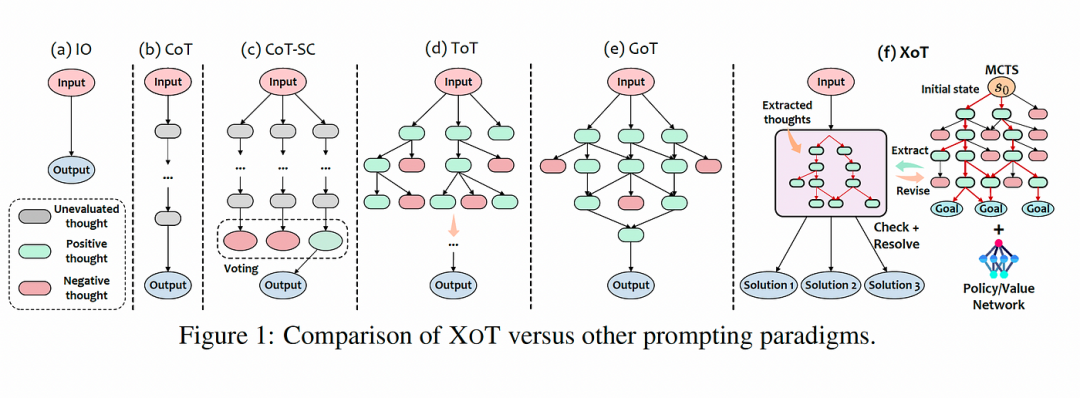
输入输出(IO)Prompt(图1(a)):IO方法在不提供任何中间thought过程的情况下,直接指导LLM解决问题;
思维链(CoT)(图1(b)):CoT将待解决问题分解为一系列的thought链,让LLM能够一步一步地处理复杂的问题;
自洽CoT(CoT-SC)(图1(c)):CoT SC使用多个CoT实例从而让LLM生成多个输出,它从中选择最佳的输出,与普通的CoT相比,提供了更稳健和一致的推理;
思维树(ToT)(图1(d)):ToT以树状结构组织思想并利用搜索算法(例如,广度优先搜索、深度优先搜索)将树扩展到追求最佳解决方案。但是ToT中的thought评价依赖于LLM本身,需要多次调用LLM进行推理,这昂贵且低效;
思维图(GoT)(图1(e)):GoT扩展了ToT方法,通过thought聚合和细化生成类似图形的思想结构。
PS:在中间搜索阶段期间。尽管这种方法允许更灵活的思维结构仍然需要多次LLM推理调用进行评估,从而产生显著的计算成本。
二、XOT介绍
? ? ? ?为了解决上述Prompt的这些局限性,本文将介绍一种新的Prompt技术XOT(Everything of Thoughts)。XOT使用强化学习和蒙特卡罗树搜索(MCTS)将外部知识注入Prompt过程。
XOT的关键组成部分是:
- MCTS模块——使用轻量级的策略和价值网络,通过模拟有效地探索任务的潜在思维结构;
- LLM求解器——利用LLM的内部知识,对MCTS中的思想进行提炼和修正。这种协作过程提高了思维质量。
三、XOT工作原理
XOT框架包括以下关键步骤:
-
预训练阶段:对MCTS模块进行特定任务的预训练,以学习有关高效thought搜索的领域知识。轻量级策略和价值网络指导搜索;
-
Thought搜索:在推理过程中,预训练的MCTS模块使用策略/价值网络来有效地探索和生成LLM的thought轨迹;
-
Thought修正:LLM审查MCTS生成的thought,并识别其中可能的任何错误,如果有错误,再通过额外的MCTS模拟产生修正后的thought;
-
LLM推理:把包括修改thought后的最终Prompt提供给LLM来解决问题。
下图说明了XOT框架:
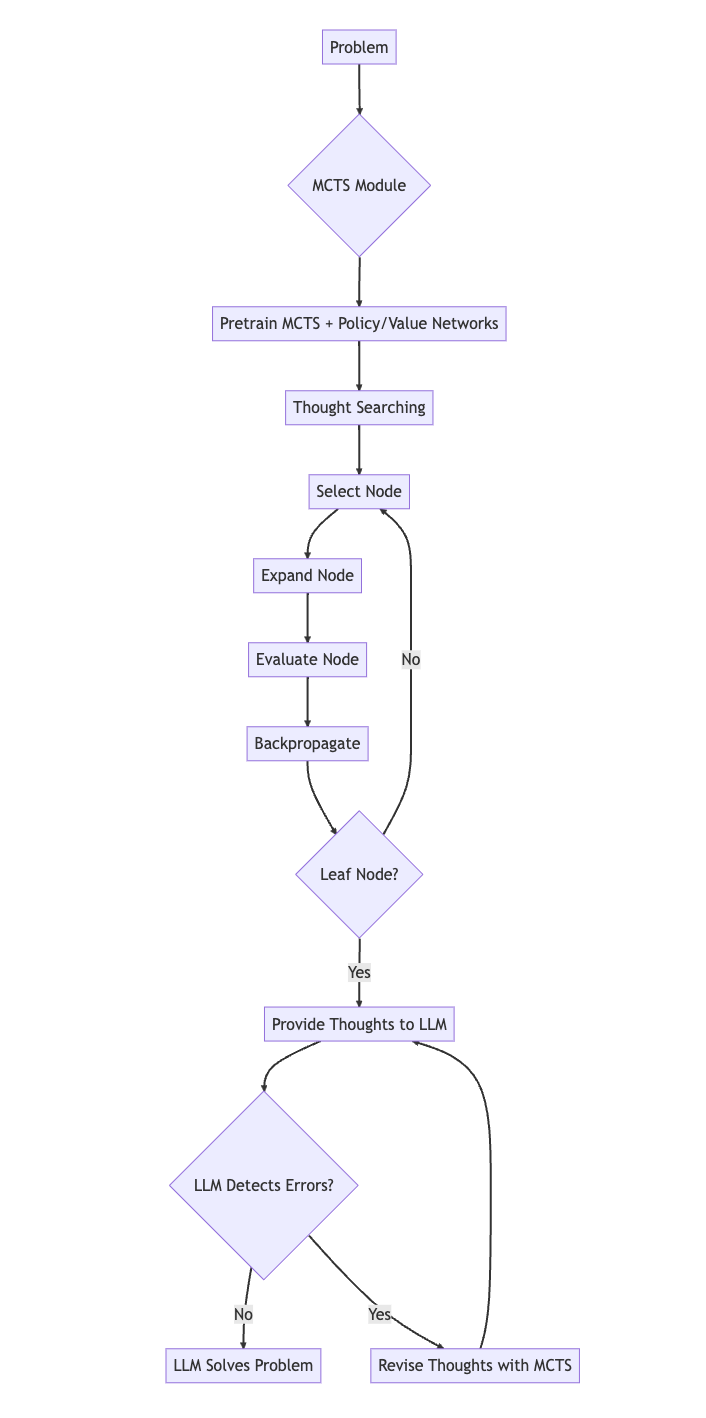
? ? ? ?MCTS模块针对特定任务进行预训练,使用策略和价值网络来指导搜索和学习领域知识。
-
在thought搜索过程中,预训练的MCTS使用策略和价值网络来有效地探索搜索空间并生成thought轨迹。整个过程迭代地选择、扩展、评估和反向传播节点;
-
thought轨迹提供给LLM作为Prompt;
-
LLM使用其内部知识来检测thought中的任何错误;
-
如果发现错误,MCTS模块将用于通过额外的模拟来修改thought;
-
该过程重复进行,直到LLM使用修订后的高质量thought解决问题。
四、XOT?Pocket Cube问题实战
? ? ? 我们使用Pocket Cube问题(2x2x2魔方)来看一下XOT是如何工作的?
-
选择:算法从根节点开始,从可用集合中选择一个动作,用于在当前状态下生成单步思想。这个过程一直持续到到达当前树中的一个叶节点为止。该选择由PUCT算法指导,旨在最大化置信上限(UCB);
-
评估和扩展:到达之前未选择的叶节点后,我们扩展到下一步新思想探索的状态。这种扩展涉及对其值和状态的作用概率的评估,这些值和作用概率由θ参数化的神经网络建模,(Pθ(s), vθ(s)) = fθ(s)。这里,Pθ(s)是s上所有动作的先验概率,vθ(s)表示其预测状态值。这两个值被保留和存储用于备份目的,状态s被标记为“已访问”;
-
反向传播:在上述阶段对叶节点进行扩展后,可能是未探索状态或终端状态,算法继续通过反向传播更新所有Q(s,a)值。对于未探索的节点,这种更新涉及计算其估计值vθ的平均值,而对于终止的节点,它是基于真实奖励r。这些更新是在信息沿着轨迹反向传播到后续节点时发生的。此外,每个状态操作对的访问计数也会增加;
-
思想推理:在MCTS完成搜索后,提取思想并将其提供给LLM。LLM然后审查和提炼这些想法,如果需要,继续MCTS搜索过程,并最终通过将这些外部想法与其内部知识相结合来制定最终答案。
PS:重复此过程,直到问题得到解决或达到预定义的迭代次数。
五、XOT的主要优点
? ? ? ?与现有Prompt技术相比,XOT有以下优点:
- 性能:MCTS探索将领域知识注入思想来增强LLM能力。协作修订过程进一步提高了thought质量;
- 效率:轻量级策略/价值网络指导MCTS,最大限度地减少昂贵的LLM呼叫。推理过程中只需要调用1-2次即可;
- 灵活性:MCTS可以探索不同的思维结构,如链、树和图,从而实现创造性思维。
PS:XOT实现了其他Prompt范式不能同时满足“Penrose Triangle”。
六、XOT实验结果
? ? ?研究人员在需要长期规划的复杂任务上评估了XOT,如《24小时游戏》、《8拼图》和《口袋魔方》。一些关键发现:
- XOT在所有任务中的准确性显著优于IO、CoT、ToT和GoT等基线;
- 经过thought修正,XOT在《24小时游戏》中仅使用1–2个LLM调用就实现了高达90%的准确率,证明了高效性;
- XOT高效地生成了多种多样的问题解决方案,展现了灵活性;
- 对于8-Puzzle和Pocket Cube等空间推理任务,XOT使LLM能够解决他们以前遇到的问题。
PS:这些结果突出了XOT如何通过高效灵活的提示释放LLM在复杂问题解决方面的潜力。
参考文献:
[1]?https://medium.com/@raphael.mansuy/xot-a-new-prompting-technique-for-ai-the-secret-sauce-to-level-up-your-llms-reasoning-prowess-3e19703ab582
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!