粒子群优化pso结合bp神经网络优化对csv文件预测matlab
2024-01-02 16:31:46
1.csv数据为密西西比数据集,获取数据集可以管我要,数据集内容形式如下图:
2.代码
这里参考的是b站的一位博主。
数据集导入教程在我的另一篇文章bp写过,需要的话可以去看一下

psobp.m
close all
clc
%读取数据
input=X;
output=Y;%10000行1列
%设置训练数据与测试数据
input_train=input(1:8000,:)';
output_train=output(1:8000,:)';
input_test=input(8001:10000,:)';
output_test=output(8001:10000,:)';%2000列1行
%节点个数
inputnum=26;%输入层节点数量
hiddennum=12;%隐藏层节点数量
outputnum=1;%输出层节点数量
w1num=inputnum*hiddennum;%输入层到隐藏层的权值个数
w2num=outputnum*hiddennum;%输出层到隐藏层的权值个数
N=w1num+hiddennum+w2num+outputnum;%待优化的变量个数
%训练数据归一化
[inputn,inputps]=mapminmax(input_train);
[outputn,outputps]=mapminmax(output_train);
%%定义pso算法参数
E0=0.001;%允许误差
MaxNum=10;%粒子最大迭代次数
narvs=N;%目标函数的子变量个数
particlesize=10;%粒子群规模
c1=2;%个体经验学习因子
c2=2;%社会经验学习因子
w=0.6;%惯性因子
vmax=0.8;%粒子最大飞行速度
x=-5+10*rand(particlesize,narvs);%粒子所在位置,规模是粒子群数和参数需求数设置x的取值范围[-5,5]
v=2*rand(particlesize,narvs);%粒子飞行速度,生成每个粒子飞行速度,只有一个变量,所以速度是一维的
trace=zeros(N+1,MaxNum);%寻优结果的初始值
objv=objfun(x,input_train,output_train,input_test,output_test);%计算目标函数值
personalbest_x=x;%用于存储个体最优,存储每个粒子经历的x值
personalbest_faval=objv;%存储个体最优的y,每个个体的误差的群体
[globalbest_faval,i]=min(personalbest_faval);
globalbest_x=personalbest_x(i,:);%全局最优的x
k=1;%开始迭代
while k<=MaxNum
objv=objfun(x,input_train,output_train,input_test,output_test);
for i=1:particlesize
if objv(i)<personalbest_faval(i)
personalbest_faval(i)=objv(i);%将第i个粒子作为个体最优解
personalbest_x(i,:)=x(i,:);%更新最优解位置
end
end
[globalbest_favalN,i]=min(personalbest_faval);
globalbest_xn=personalbest_x(i,:);
trace(1:N,k)=globalbest_xn;%每代最优x值
trace(end,k)=globalbest_favalN;
%%粒子更新
for i=1:particlesize
v(i,:)=w*v(i,:)+c1*rand*(personalbest_x(i,:)-x(i,:))+c2*rand*(globalbest_x-x(i,:));
%rand会随机生成一个(0,1)的随机降低学习因子的比例
for j=1:narvs%确定每个变量的速度,不超过最大速度
if v(i,j)>vmax
v(i,j)=vmax;
elseif v(i,j)<-vmax
v(i,j)=-vmax;
end
end
x(i,:)=x(i,:)+v(i,:);
end
globalbest_faval=globalbest_favalN;
globalbest_x=globalbest_xn;
k=k+1;
end
%%画图
figure(1);
plot(1:MaxNum,trace(end,:));
grid on;
xlabel('遗传代数');
ylabel('误差变化');
title('进化过程');
objfun.m
function [obj,T_sim]=objfun(X,input_train,output_train,input_test,output_test)
%%分别求解种群每个个体的目标值
%输入
%x:所有个体的初始权值与阈值
%input_train:训练样本输入
%output_train:训练样本输出
%hiddennum:隐藏神经元个数
%input_test:测试样本输入
%output_test:测试样本输出
%%输出
%obj:所有个体的预测样本的预测误差的范数,让这个误差最小,也就是每一个种群全都累加变成一个数,这里有10个种群,就是10个数
[M,N]=size(X);%返回一个M行N列的矩阵
obj=zeros(M,1);%所有个体误差初始化为M行1列也就是前面的粒子群规模,就是10行1列
T_sim=zeros(M,2000);%size(output_test,2)返回output_test的列数也就是2000个结果,也就是预测值是10行2000列的数值
for i=1:M
[obj(i),T_sim(i,:)]=BpFunction(X(i,:),input_train,output_train,input_test,output_test);
end
T_sim=T_sim';
endBpFunction.m
%%输入
function [err,T_sim]=BpFunction(x,input_train,output_train,input_test,output_test)
inputnum=26;%输入层节点数量
hiddennum=12;%隐藏层节点数量
outputnum=1;%输出层节点数量
%%数据归一化
[inputn,inputps]=mapminmax(input_train,0,1);
[outputn,outputps]=mapminmax(output_train,0,1);
%bp神经网络
net=newff(inputn,outputn,hiddennum);
%网络参数配置
net.trainParam.epochs=30;
net.trainParam.lr=0.001;
net.trainParam.goal=0.0001;
w1num=inputnum*hiddennum;%输入层到隐藏层的权值个数
w2num=outputnum*hiddennum;%输出层到隐藏层的权值个数
W1=x(1:w1num);
B1=x(w1num+1:w1num+hiddennum);
W2=x(w1num+hiddennum+1:w1num+hiddennum+w2num);
B2=x(w1num+hiddennum+w2num+1:w1num+hiddennum+w2num+outputnum);
net.iw{1,1}=reshape(W1,hiddennum,inputnum);
net.lw{2,1}=reshape(W2,outputnum,hiddennum);
net.b{1}=reshape(B1,hiddennum,1);
net.b{2}=reshape(B2,outputnum,1);
%%开始训练
%网络训练
net=train(net,inputn,outputn);
%%测试网络
t_sim=sim(net,input_test);
T_sim=mapminmax('reverse',t_sim,outputps);
err=norm(T_sim-output_test);
end3.结果
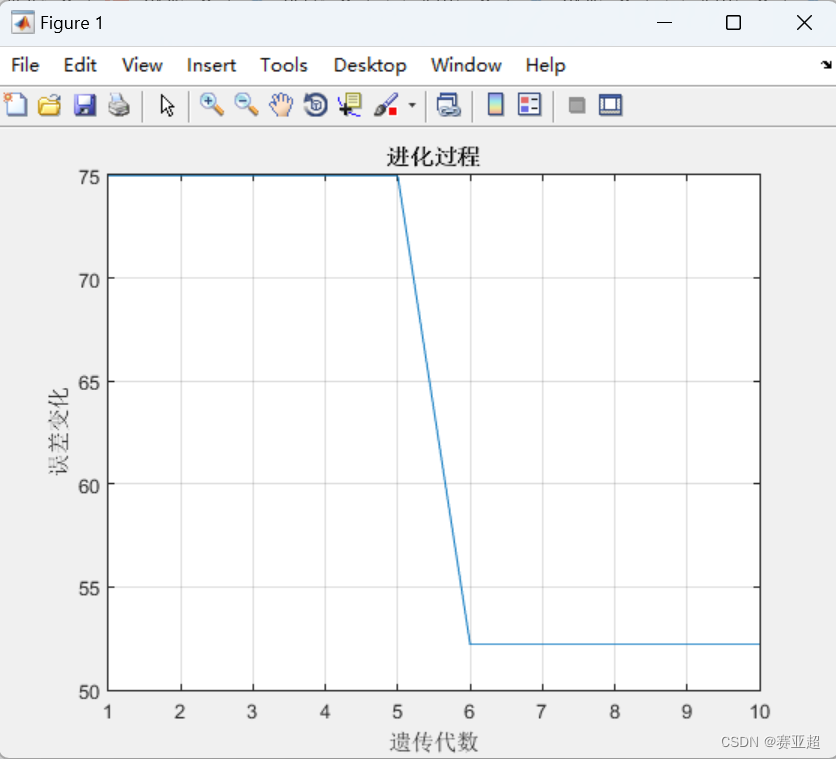
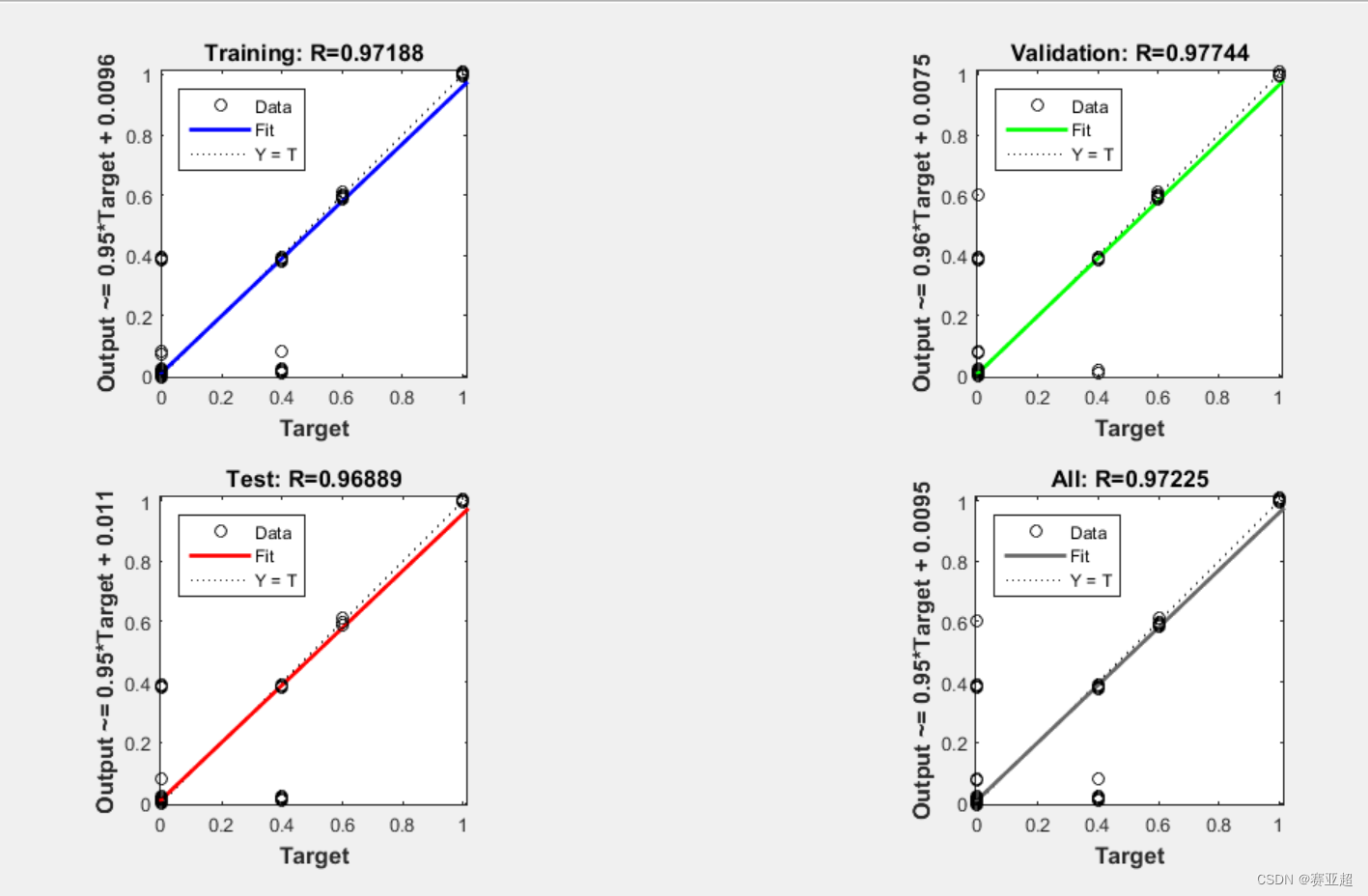
4.优化之前
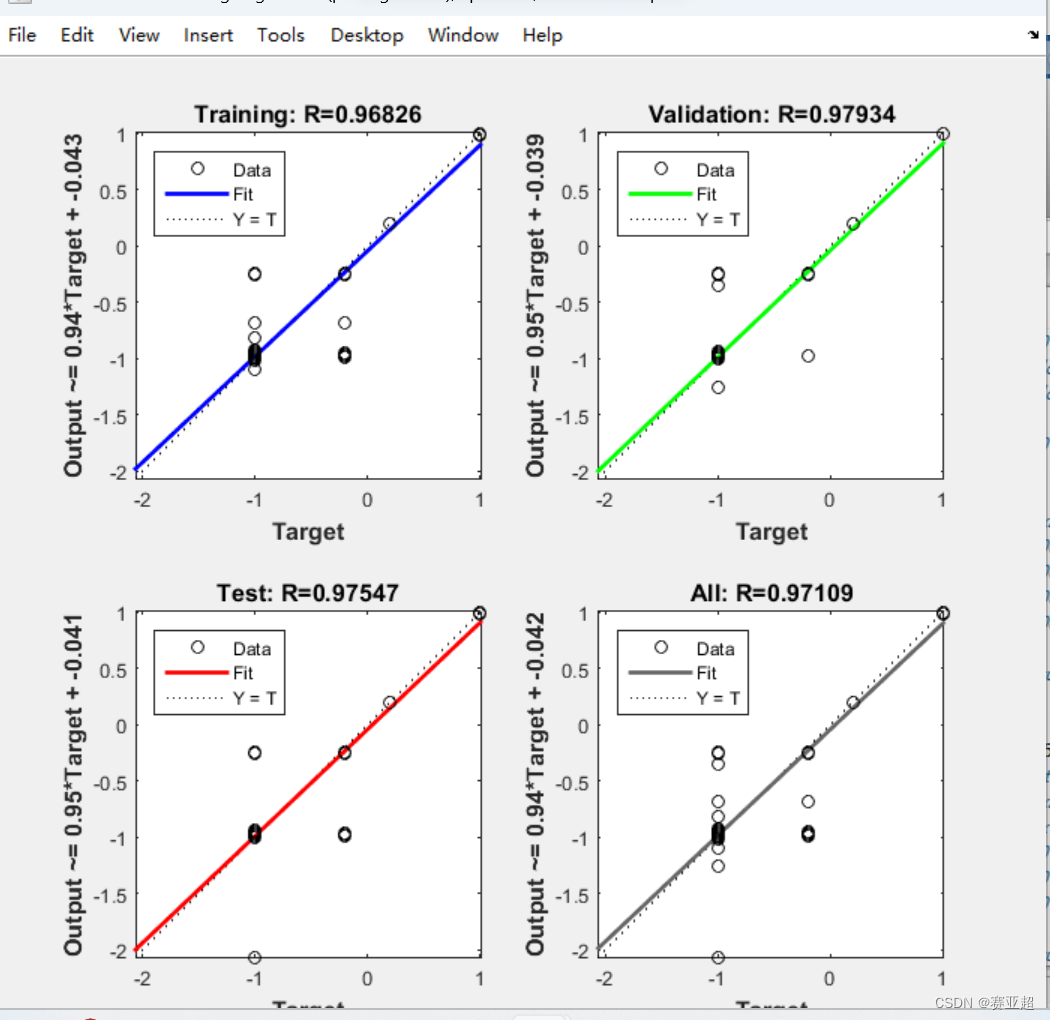
5.之所以上面有拟合差别大的地方在于bp网络自动将数据集中某一列全是一个数的给消去了,不知是系统消去的还是神经网络给消掉的。所以他会报错:
net.IW{1,1} must be a 12-by-8 matrix.
报这个错误的解决办法我是将某一列中第一行数据加个0.1。虽然是个解决办法,但是会影响到识别精度。所以不是个好办法。
文章来源:https://blog.csdn.net/weixin_48433993/article/details/135342458
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!