多模态推荐系统综述:一、特征交互 Bridge
一、特征交互
挑战1.如何融合不同语义空间中的模态特征并获得每种模态的偏好。GNN+注意力
挑战2.如何在数据稀疏的情况下获得推荐模型的全面表示。对比学习+解缠学习
挑战3. 如何优化轻量级推荐模型和参数化模态编码器。
1. Bridge
侧重于考虑多模态信息来捕获用户和项目之间的相互关系。
大多数早期作品只是简单地使用多模态内容来增强项目表达,但它们往往忽略了用户和项目之间的交互。
1.1 用户-相互二部图
利用用户和物品之间的信息交换,可以捕获用户对不同模式的偏好。因此,一些模型利用了用户-项目图。
MMGCN: Multi-modal Graph Convolution Network for Personalized Recommendation of Micro-video 2019
MMGCN为每种模态建立了一个用户-项目二分图。对于每个节点,可以利用相邻节点的拓扑结构和项目的模态信息来更新该节点的特征表达。
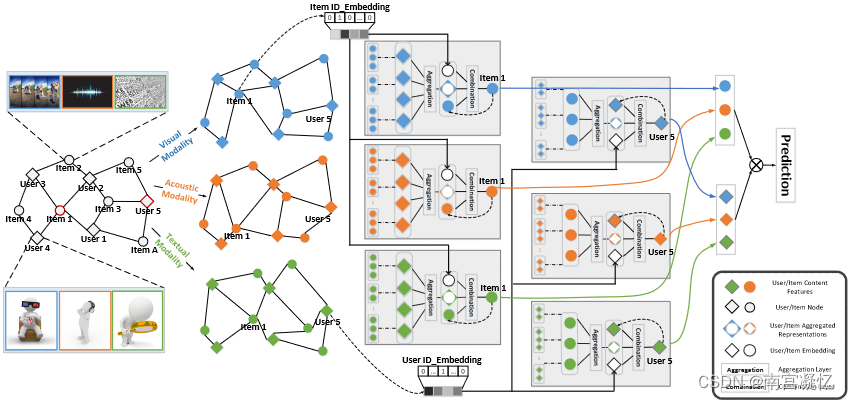
GRCN: Graph-Refined Convolutional Network for Multimedia Recommendation with Implicit Feedback 2021
通过在模型训练期间自适应修改图的结构来删除不正确的交互数据(用户点击了不感兴趣的视频)来提供建议。
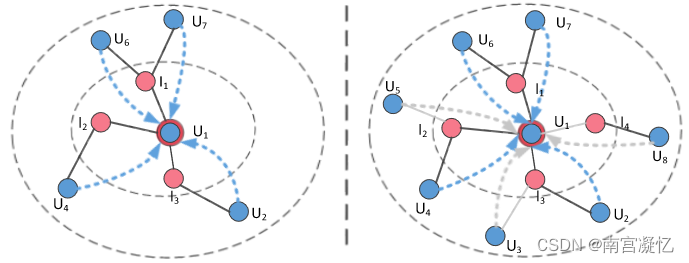
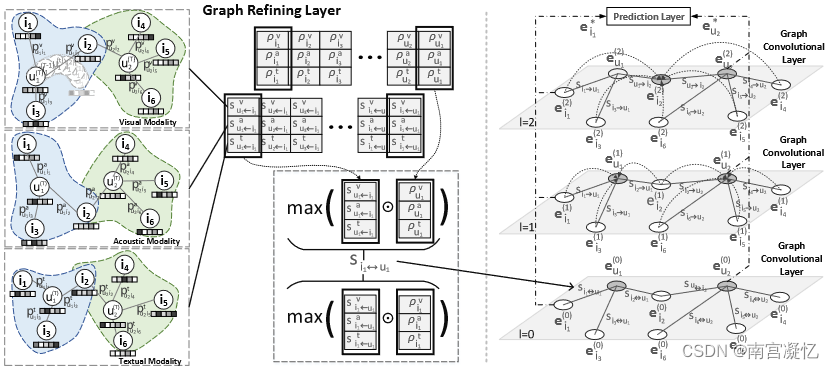
该模型由三个组件组成:1)图细化层,通过识别和修剪交互图中的噪声边来调整图结构; 2)图卷积层,对精化图进行图卷积运算,以丰富项目和用户的嵌入; 3)预测层,用于推断每个用户和项目对的交互。
注:MMGCN、GRCN这些方法仍然存在局限性,因为使用统一的方式来融合不同模态的用户偏好,忽略了用户对不同模态的偏好程度的差异。换句话说,给每种模态赋予相同的权重可能会导致模型的性能不佳。为了解决这个问题,DualGNN、MMGCL、MGAT学习模态之间的相关性
DualGNN: Dual Graph Neural Network for Multimedia Recommendation 2021
DualGNN利用用户之间的相关性,基于二分图和用户共现图来学习用户偏好。
1)单模态表示学习模块,该模块对每种模态的用户微视频图执行图操作,以捕获不同模态的单模态用户偏好;2)多模态表示学习模块来显式建模用户对不同模态的注意力,并归纳学习多模态用户偏好。3)预测模块来对用户的潜在微视频进行排名。
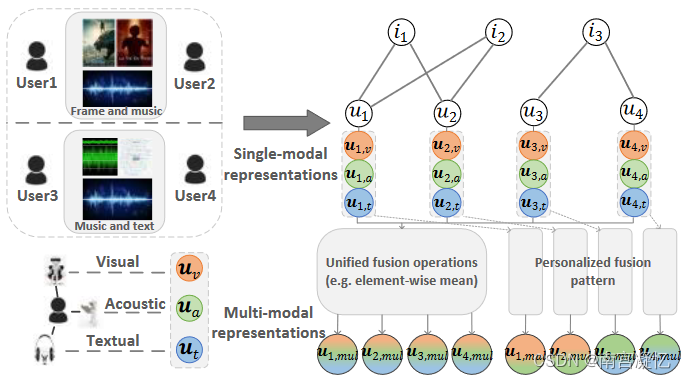
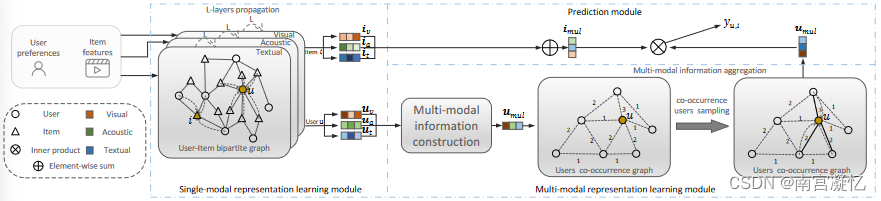
我们提出的 DualGNN 的总体框架。它由单模态表示学习模块和多模态表示学习模块组成,单模态表示学习模块捕获每个模态用户微视频二部图上的单模态用户偏好,多模态表示学习模块显式建模用户对不同模态的品味并归纳学习多模态用户偏好,预测模块估计用户对目标微视频的偏好。
* DualGNN在MMGCN基础上,多了层对用户多模态表示的学习
MMGCL: Multi-modal Graph Contrastive Learning for Micro-video Recommendation 2022
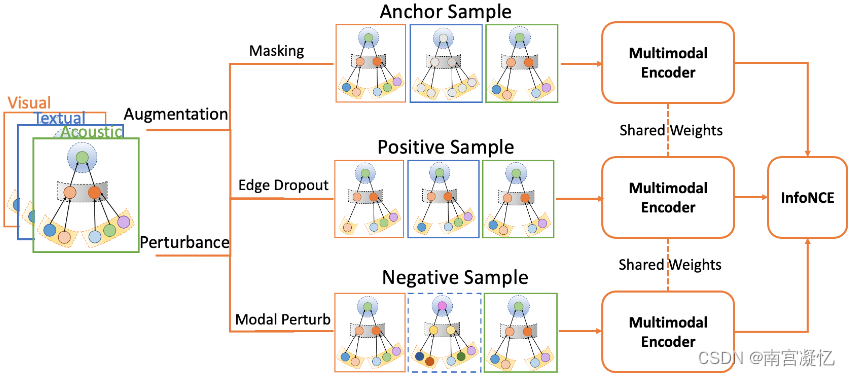
MMGCL设计了一种新的多模态图对比学习方法来解决这个问题。 MMGCL 使用模态边缘损失和模态掩蔽来生成用户-项目图,并引入一种新颖的负采样技术来学习模态之间的相关性。
MGAT: Multimodal Graph Attention Network for Recommendation 2020
MGAT引入了基于MMGCN的注意力机制,有利于自适应地捕获用户对不同模态的偏好。此外,MGAT利用门控注意力机制来判断用户对不同模态的偏好,可以捕获隐藏在用户行为中的相对复杂的交互模式。
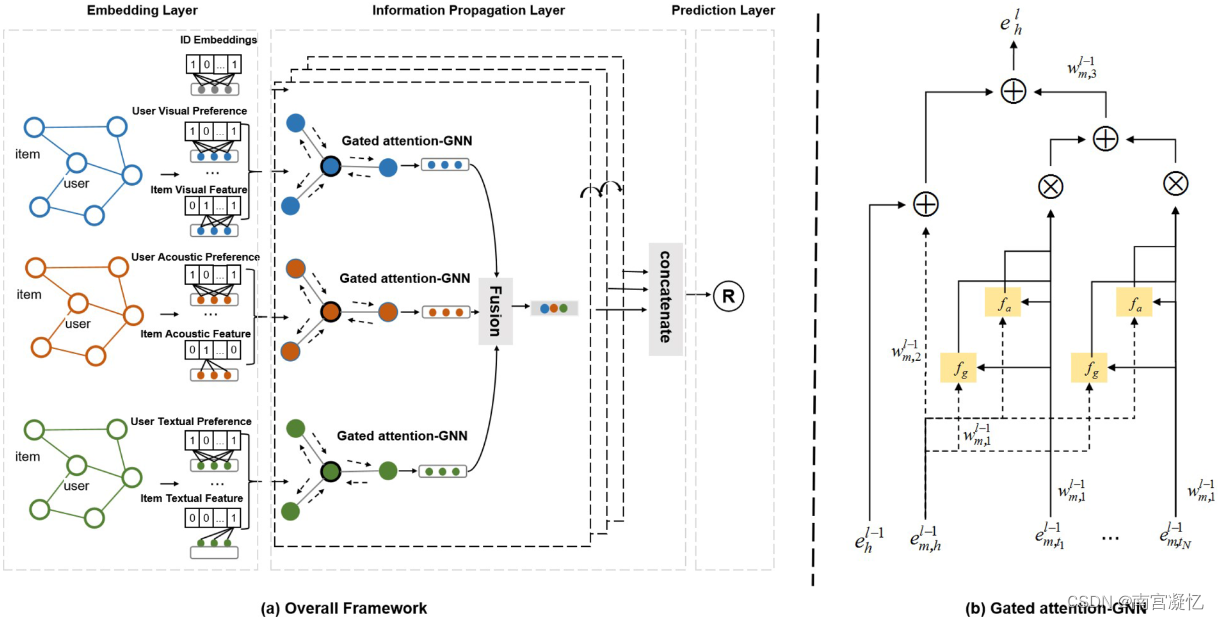
1)嵌入层,初始化用户和项目的ID嵌入;2)在单模态交互图上嵌入传播层,执行消息传递机制来捕获用户对各个模态的偏好;3)跨多模态交互图的门控注意力聚合,它利用与其他模态的相关性来学习每个邻居的权重以指导传播;4)预测层,根据最终表示估计交互的可能性。
1.2 项目-项目图。
注:使用item-item结构有利于更好地学习item表示,LATTICE、 MICRO。
LATTICE: Mining Latent Structures for Multimedia Recommendation 2021
多模态内容背后潜在的语义项目-项目结构可能有利于学习更好的项目表示并进一步促进推荐。
LATTICE设计了一种模态感知结构学习层,该层学习每种模态的项-项结构并聚合多个模态以获得潜在项图。基于学习到的潜在图,执行图卷积以显式地将高阶项目亲和力注入项目表示中。然后可以将这些丰富的项目表示插入现有的协同过滤方法中,以做出更准确的推荐。
数据集:Clothing, Sports,Baby
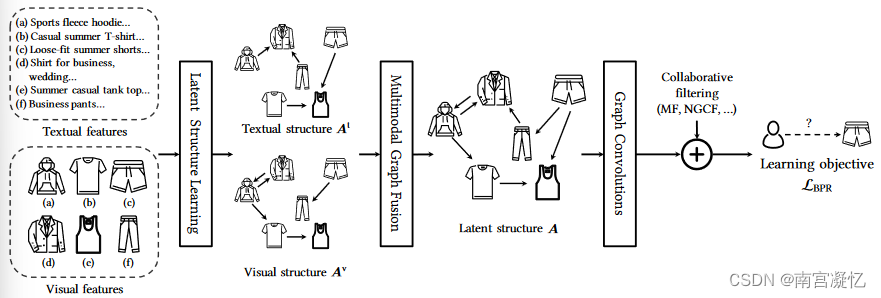
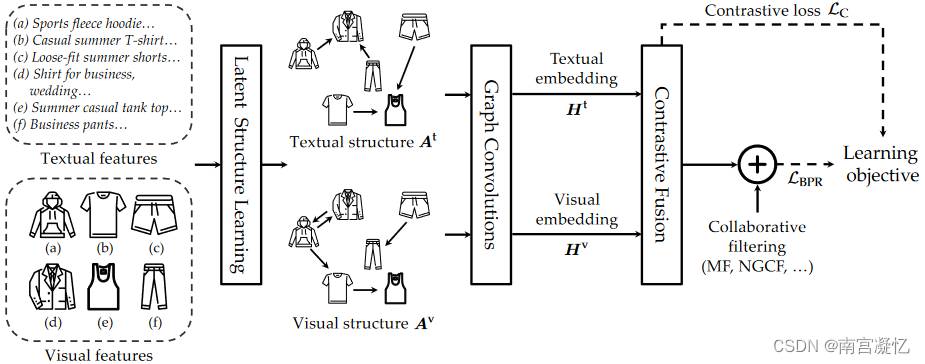
MICRO: Latent Structure Mining with Contrastive Modality Fusion for Multimedia Recommendation 2022
1)一种新颖的模态感知结构学习层,以从多模态特征中挖掘模态感知的潜在项目-项目语义关系;2)其次,我们在学习到的模态感知图上采用图卷积来分别显式地建模每种模态的项目关系;3)设计了一种新颖的对比多模态融合框架,以迫使融合的多模态表示以自我监督的方式自适应地捕获多种模态之间共享的项目关系。最后,生成的项目表示形式会融入多种模式的项目关系,这些关系将被添加到 CF 模型的输出项目嵌入中以进行推荐。对比损失和推荐(BPR)损失将一起优化。
数据集:Clothing, Sports,Baby
注:HCGCN考虑到各个特定用户群体之间偏好的差异。
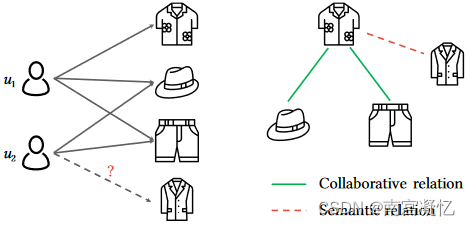
HCGCN: Learning Hybrid Behavior Patterns for Multimedia Recommendation 2022
HCGCN提出了一种聚类图卷积网络,它首先对项目-项目和用户-项目图进行分组,然后学习隐藏在图结构中的不同用户行为模式来预测用户偏好。
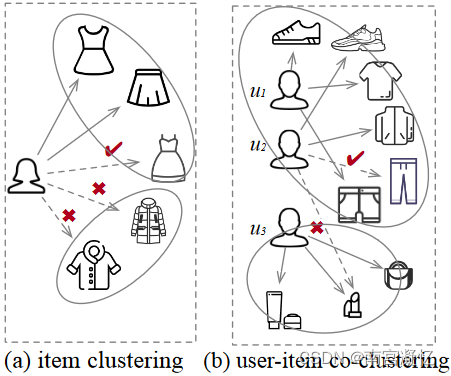
图1(a) 通过对相似的物品进行聚类,描绘了与其他衣服相比,女性更喜欢裙子。图1(b),运动员在线购物的原因可能与艺术家不同。
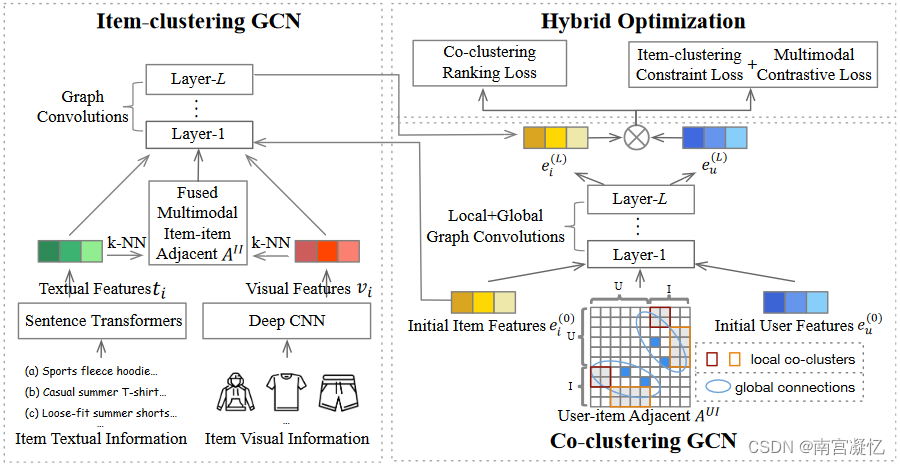
1)首先对项目进行聚类并构建项目-项目图来学习多模式项目特征。2)然后,在用户项目子图上本地学习用户偏好,并通过动态图聚类在全局范围内相互通信。此外,项目集成多模态特征和用户被联合用于计算偏好排名。3)最后,设计的共聚类排名损失和项目聚类约束损失可以促进用户-项目和项目-项目图上包含的用户模式的优化。
数据集:Clothing, Sports,Baby
注:受最近预训练模型成功的启发,PMGT 、BGCN。
PMGT: Pre-training Graph Transformer with Multimodal Side Information for Recommendation 2021
PMGT 参考 Bert 的结构提出了一种预训练图转换器,并以多模态形式提供了项目关系及其相关辅助信息的统一视图。
两个商品之间的优势由共同购买的数量来衡量。
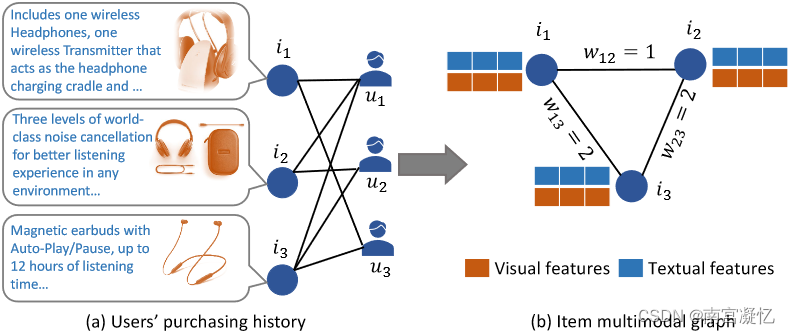
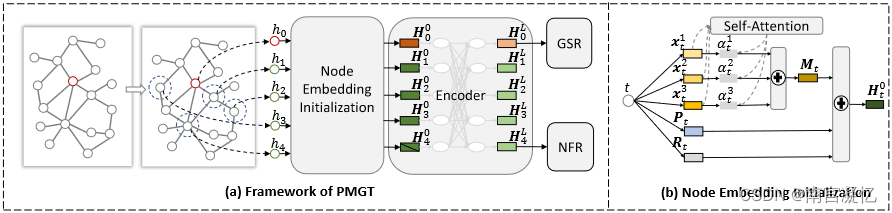
(a) PMGT 框架,包含四个组件(从左到右所示):上下文邻居采样、节点嵌入初始化、基于 Transformer 的图编码器、图重建。最后一步中的GSR和NFR分别表示图结构重建任务和屏蔽节点特征重建任务。
(b) 节点嵌入初始化:通过考虑节点的多模态特征、位置 ID 嵌入和角色标签嵌入来初始化节点嵌入。
数据集:VG, TG, THI, ML
BGCN: Bundle Recommendation with Graph Convolutional Networks 2020
BGCN作为捆绑推荐中的模型,将用户-项目交互、用户-捆绑交互和捆绑-项目隶属关系统一到异构图中,使用图卷积来提取精细增益的未来。

数据集:Netease, Youshu
注:对比学习
CrossCBR: Cross-view Contrastive Learning for Bundle Recommendation 2023
Cross-CBR构建用户捆绑图、用户项目图和项目捆绑图,使用对比学习将它们从捆绑包和项目视图中对齐。

顶部:U-B、U-I 和 B-I 图中显示的捆绑包和项目视图。底部:我们的工作对视图之间的协作关联进行建模,其中上标 B 和 I 表示捆绑包和项目视图,下标 u、b 和 i 代表用户、捆绑包和项目。
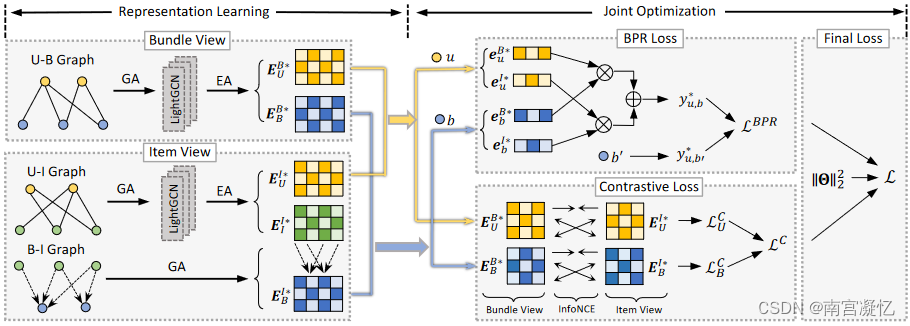
CrossCBR的整体框架由两部分组成:(1)用户和捆绑包两个视图的表示学习;(2)BPR损失LBPR和对比损失LC的联合优化。
数据集:Youshu, NetEase, iFashion
1.3 知识图谱
MKGAT: Multi-modal Knowledge Graphs for Recommender Systems 2020
MKGAT是第一个将知识图引入多模态推荐的模型。 MKGAT提出了一种多模态图注意力技术,分别从实体信息聚合和实体关系推理两个方面对多模态知识图进行建模。此外,采用新颖的图注意网络来聚合相邻实体,同时考虑知识图中的关系。


SI-MKR: An Enhanced Multi-Modal Recommendation Based on Alternate Training With Knowledge Graph Representation
SI-MKR提出了一种基于交替训练和基于MKR的知识图表示的增强型多模态推荐方法。此外,大多数多模态推荐系统都忽略了数据类型多样性的问题。 SI-MKR通过添加知识图谱中的用户和物品属性信息来解决这个问题。


MMKGV: Multi-modal Graph Attention Network for Video Recommendation 2022
MMKGV采用图注意力网络在知识图上进行信息传播和信息聚合,结合多模态信息并利用知识图的三元组推理关系。


整个模型由嵌入层、注意层、预测层三个关键层组成。在知识图嵌入模块和推荐模块中同时使用了嵌入层和注意层。
嵌入层使用不同的预训练模型对每个选定的多模态数据进行训练,并在训练后得到初始向量。注意层将每个实体的邻居实体的信息聚合到每个实体本身中,从而学习一个新的实体向量表示。然后预测层输出预测函数,表示预测用户u采用第i项的概率。
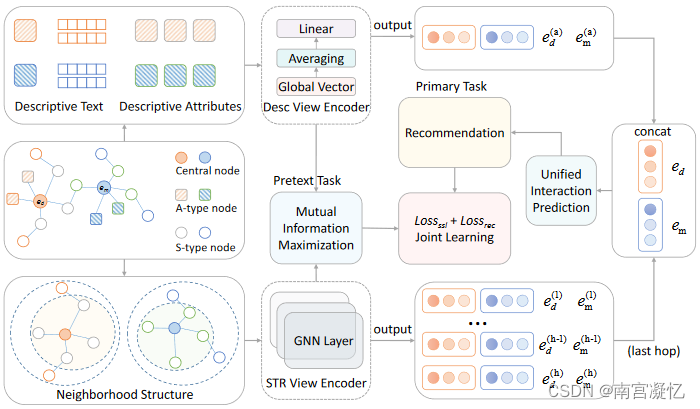
CMCKG: Cross-modal Knowledge Graph Contrastive Learning for Machine Learning Method Recommendation 2022
描述性属性和结构连接之间的区别。

CMCKG将来自描述性属性和结构连接的信息视为两种模式,并通过最大化这两种视图之间的一致性来学习节点表示。
参考文献
Multimodal Recommender Systems: A Survey
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!