一文通透文本embedding表示:从m3e、bge到..
前言
第一部分 衡量文本向量表示效果的榜单
1.2 《MTEB: Massive Text Embedding Benchmark(海量文本嵌入基准)》
判断哪些文本嵌入模型效果较好,通常需要一个评估指标来进行比较,《MTEB: Massive Text Embedding Benchmark(海量文本嵌入基准)》就是一个海量文本嵌入模型的评估基准
- 论文地址:https://arxiv.org/abs/2210.07316
MTEB包含8个语义向量任务,涵盖58个数据集和112种语言。通过在MTEB上对33个模型进行基准测试,我们建立了迄今为止最全面的文本嵌入基准。我们发现没有特定的文本嵌入方法在所有任务中都占主导地位。这表明该领域尚未集中在一个通用的文本嵌入方法上,并将其扩展到足以在所有嵌入任务上提供最先进的结果 - github地址:https://github.com/embeddings-benchmark/mteb#leaderboard

榜单地址:https://huggingface.co/spaces/mteb/leaderboard

1.2 中文海量文本embedding任务排行榜
从Chinese Massive Text Embedding Benchmark中可以看到目前最新的针对中文海量文本embedding的各项任务的排行榜,针对不同的任务场景均有单独的排行榜。
任务榜单包括:
- Retrieval
- STS
- PairClassification
- Classification
- Reranking
- Clustering
其中,在本地知识库任务中,主要是根据问题query的embedding表示到向量数据库中检索相似的本地知识文本片段。因此,该场景主要是Retrieval检索任务。检索任务榜单如下:

目前检索任务榜单下效果最好的是bge系列的bge-large-zh模型,langchain-chatchat项目中默认的m3e-base也处于比较靠前的位置
第二部分?m3e模型
2.1 m3e模型简介
M3E使用in-batch负采样的对比学习的方式在句对数据集进行训练,为了保证in-batch负采样的效果,使用A100来最大化batch-size,并在共计2200W+的句对数据集上训练了 1 epoch
使用了指令数据集,M3E 使用了300W+的指令微调数据集,这使得 M3E 对文本编码的时候可以遵从指令,这部分的工作主要被启发于?instructor-embedding
基础模型,M3E 使用?Roberta?系列模型进行训练
1.3.2.2 m3e模型微调
- 微调脚本:
m3e是使用uniem脚本进行微调from datasets import load_dataset from uniem.finetuner import FineTuner dataset = load_dataset('shibing624/nli_zh', 'STS-B') # 指定训练的模型为 m3e-small finetuner = FineTuner.from_pretrained('moka-ai/m3e-small', dataset=dataset) finetuner.run(epochs=3)
详细代码暂放在「大模型项目开发线上营」中,至于本文后续更新
第三部分 bge模型
3.1 bge模型的简介
BGE是北京智源人工智能研究院发布的中英文语义向量模型
- bge模型:https://huggingface.co/BAAI/bge-large-zh
- bge项目:https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md
以下是BGE的技术亮点
- 高效预训练和大规模文本微调;
- 在两个大规模语料集上采用了RetroMAE预训练算法,进一步增强了模型的语义表征能力;
- 通过负采样和难负样例挖掘,增强了语义向量的判别力;
- 借鉴Instruction Tuning的策略,增强了在多任务场景下的通用能力
3.1.1 RetroMAE
目前主流的语言模型的预训练任务都是token级别的,比如MLM或者Seq2Seq,但是这种训练任务难以让模型获得一个高质量的基于句子级别的句向量,这限制了语言模型在检索任务上的潜力。针对这个弊端,目前有两者针对检索模型的预训练策略
- 第一种是self-contrastive learning,这种方式往往受限于数据增强的质量,并且需要采用非常庞大数量的的负样本
- 另一种基于anto-encoding,一种自重建方法,不受数据增强跟负样本采样策略的影响,基于这种方法的模型性能好坏有两个关键因素,其一是重建任务必须要对编码质量有足够的要求,其二是训练数据需要被充分利用到
基于此,研究人员提出了RetraoMAE(RetroMAE论文:https://arxiv.org/abs/2205.12035),它包括两个模块,其一是一个类似于BERT的编码器,用于生成句向量,其二是一个一层transformer的解码器,用于重建句子,如下图所示

- Encoding
给定一个句子输入X,随机mask掉其中一小部分token后得到X_enc,这里通常会采用中等的mask比例(15%~30%),从而能保留句子原本大部分的信息,然后利用一个编码器对其进行编码,得到对应的的句向量h_x。由于采用了类似BERT的编码器,最终将[CLS]位置最后一层的隐状态作为句子向量 - Decoding
给定一个句子输入X,随机mask掉其中一部分token得到X_dec,这里通常会采取比encoder部分更加激进的mask比例(50%~70%),利用mask后的文本跟encoder生成的句向量对文本进行重建
在解码器部分采用了及其简单的网络结构跟非常激进的mask比例,从而使得解码任务变得极具挑战性,迫使encoder去生成高质量的句向量才能最终准确地完成原文本重建
- Enhanced Decoding
前面提及的解码策略有一种缺陷,就是训练信号只来源于被mask掉的token,而且每个mask掉的token都是基于同一个上下文重建的。于是研究人员提出了一种新的解码方法,Enhanced Decoding,具体做法如下
a) 首先生成两个不同的输入流H1(query)跟H2(context)
b) 通过attention机制得到新的输出A,这里的M是一个mask矩阵,第i个token所能看得到的其他token是通过抽样的方式决定的(当然要确保看不到自身token,而且都要看得见第一个token,也就是encoder所产出CLS句向量的信息)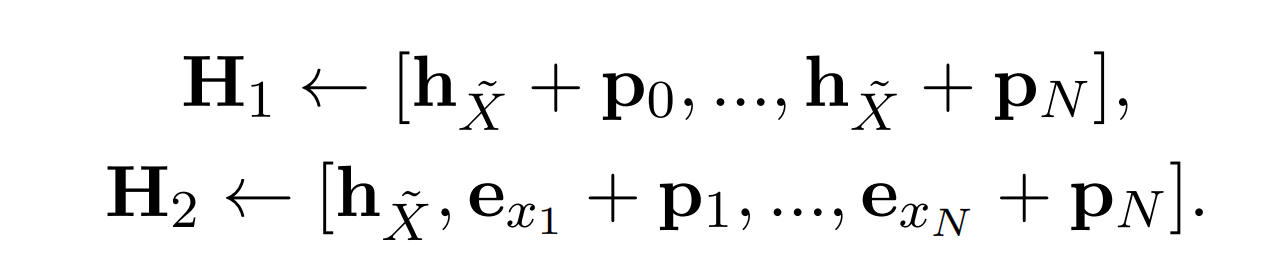
c)最终利用A跟H1去重建原文本,这里重建的目标不仅仅是被mask掉的token,而是全部token。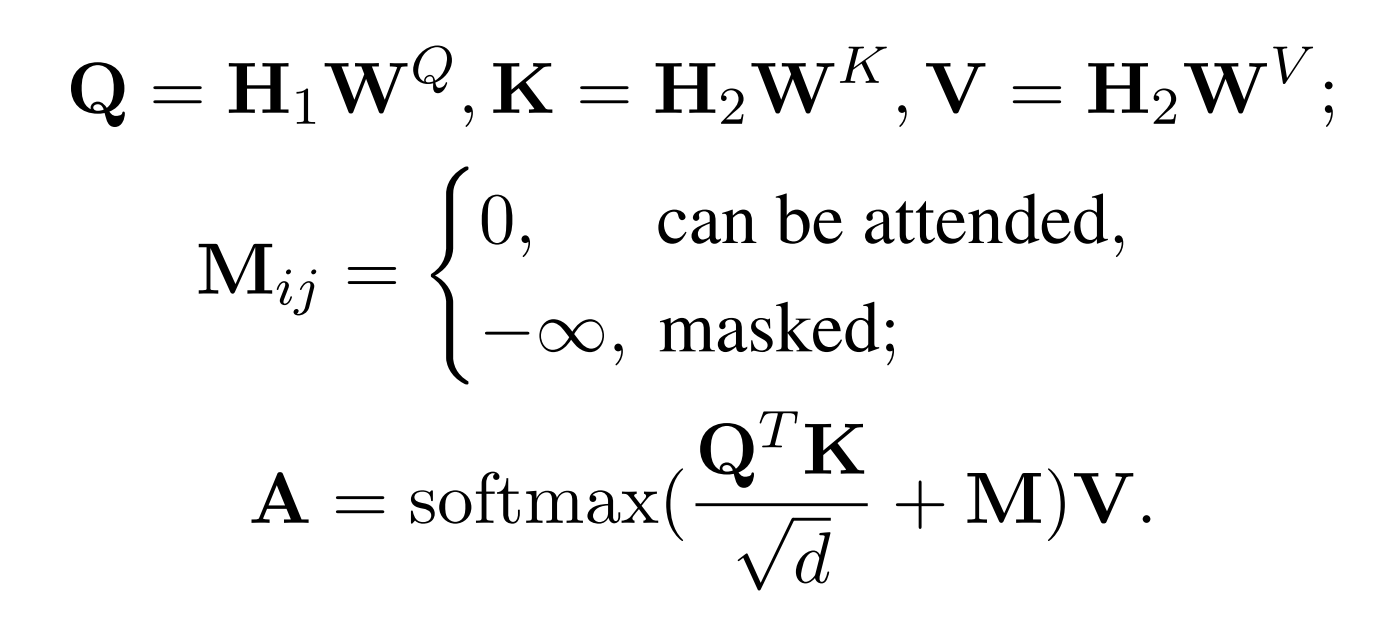
最终RetroMAE的损失由两部分相加得到,其一是encoder部分的MLM损失,其二是deocder部分自重建的交叉熵损失。
3.2.2 bge模型的微调
- ?微调脚本:https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune
- 数据格式
{"query": str, "pos": List[str], "neg":List[str]} - 难负样本挖掘
难负样本是一种广泛使用的提高句子嵌入质量的方法。可以按照以下方法挖掘难负样本python -m FlagEmbedding.baai_general_embedding.finetune.hn_mine \ --model_name_or_path BAAI/bge-base-en-v1.5 \ --input_file toy_finetune_data.jsonl \ --output_file toy_finetune_data_minedHN.jsonl \ --range_for_sampling 2-200 \ --use_gpu_for_searching - 训练
python -m FlagEmbedding.baai_general_embedding.finetune.hn_mine \ --model_name_or_path BAAI/bge-base-en-v1.5 \ --input_file toy_finetune_data.jsonl \ --output_file toy_finetune_data_minedHN.jsonl \ --range_for_sampling 2-200 \ --use_gpu_for_searching
参考文献与推荐阅读
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!