记一次关于FunASR的效率测试
2023-12-28 17:18:17
FunASR github
modelscope
部分代码
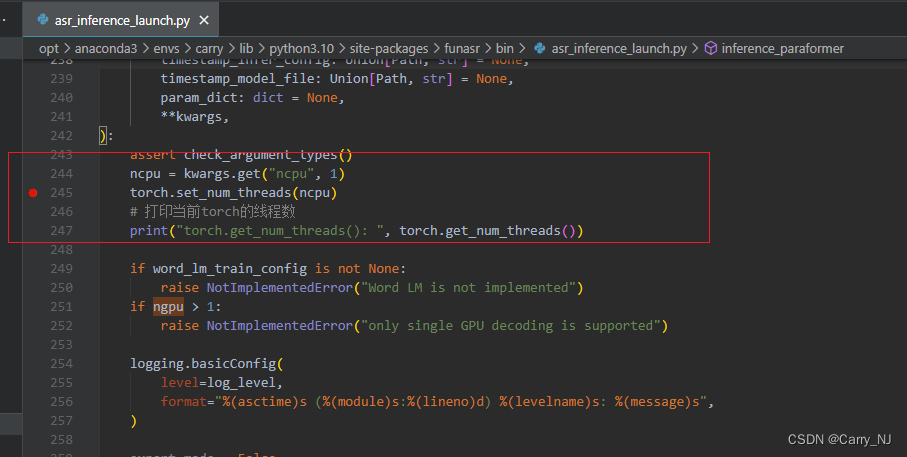
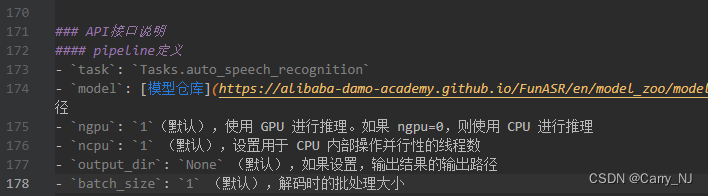
其中 pipeline 有 device 参数可以选择使用GPU或者CPU,这个参数比较好找。这里要说的是另一个参数:ncpu
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
param_dict = dict()
param_dict['hotword'] = "https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/hotword.txt"
inference_pipeline = pipeline(
task=Tasks.auto_speech_recognition,
model="damo/speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404",
param_dict=param_dict,
device=cfg.DEVICE,
ncpu=4,
)
rec_result = inference_pipeline(audio_in='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_hotword.wav')
print(rec_result)
debug 代码后发现, 这个参数实际上是设置torch线程数。torch 默认线程数是CPU核数,funasr这里做了阉割设置,默认为1了(不知道为啥。。。)修改此参数后可以使得推理速度加快,原本一条90秒的音频ncpu=1时,耗时10秒,i9-10900X(10c20t)。修改后读取默认值(ncpu=10),速度为2.7秒
附图参数说明:
文章来源:https://blog.csdn.net/xkx_07_10/article/details/135270826
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!