分片并不意味着分布式
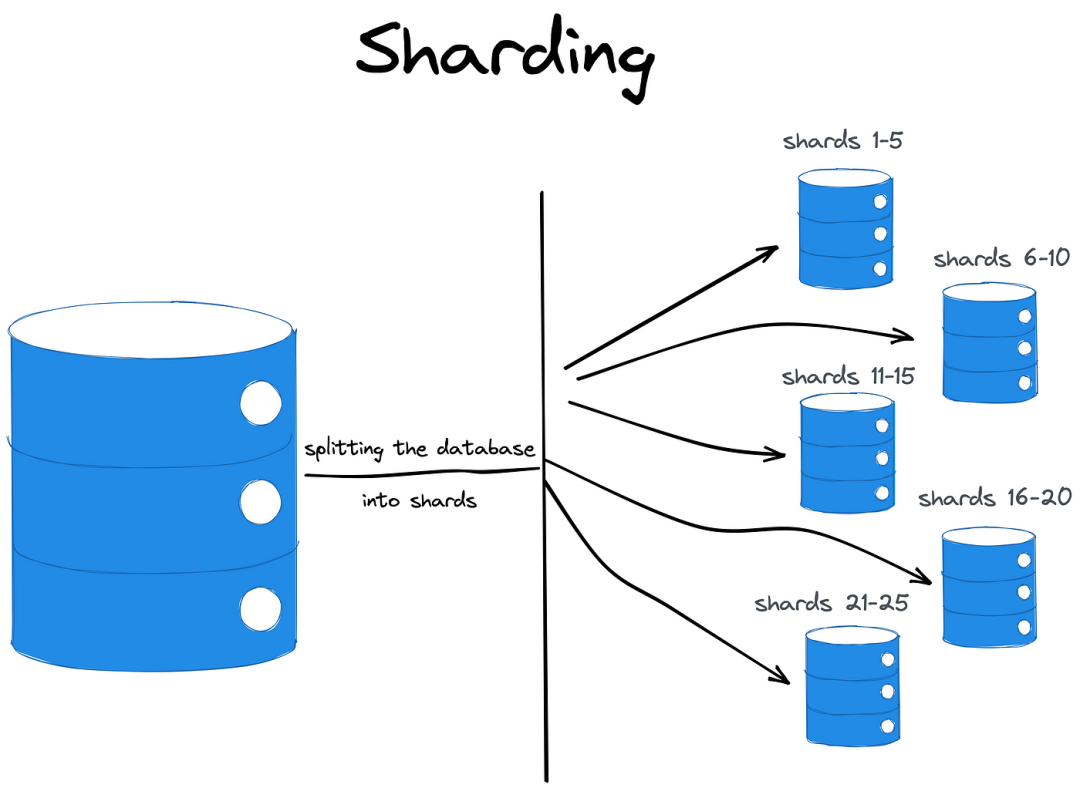
Sharding(分片)是一种将数据和负载分布到多个独立的数据库实例的技术。这种方法通过将原始数据集分割为分片来利用水平可扩展性,然后将这些分片分布到多个数据库实例中。
1*yg3PV8O2RO4YegyiYeiItA.png
但是,尽管"分布"一词出现在分片的定义中,但分片数据库并不是分布式数据库。
分片解决方案
每个分片解决方案在其架构中都有一个关键组件。该组件可以有各种名称,包括协调器、路由器或导演:

1*kp39_8mQ0E9bIO0Lw3PGFw.png
协调器是唯一一个知道数据分布的组件。它将客户端请求映射到特定的分片,然后转发到相应的数据库实例。这就是为什么客户端必须始终通过协调器路由其请求的原因。
例如,如果客户端想要将新记录插入到Car表中,请求首先会传递到协调器。协调器将记录的主键映射到其中一个分片,然后将请求转发到负责该分片的数据库实例。

1*YNUB6y8WJnp0CCVAXSjQ0g.png
在上面的示意图中,首先,协调器将键121映射到分片10,然后将记录插入到存储在拥有分片10的数据库实例上的表car_10中。
然而,还有一个问题:为什么在分片解决方案中需要协调器呢?答案很直接。分片存储在设计用于单服务器部署的数据库实例上。
这些数据库实例不相互通信,也不支持任何能促进这种通信的协议。它们彼此不知道,存在于各自的隔离环境中,对于它们是一个更大系统的一部分这一事实毫不知情。
因此,在分片解决方案中,协调器是不可或缺的。如果您有兴趣更深入地了解分片数据库架构,请考虑探索用于PostgreSQL的CitusData或Azure CosmosDB,用于MySQL的Vitess,用于Oracle的Distributed Autonomous Database以及MongoDB Sharded Cluster。
分布式数据库
与分片数据库解决方案类似,分布式数据库也使用类似的分片技术在数据库节点群集中分发数据和负载。但是,与分片解决方案不同,分布式数据库不依赖于协调器组件。
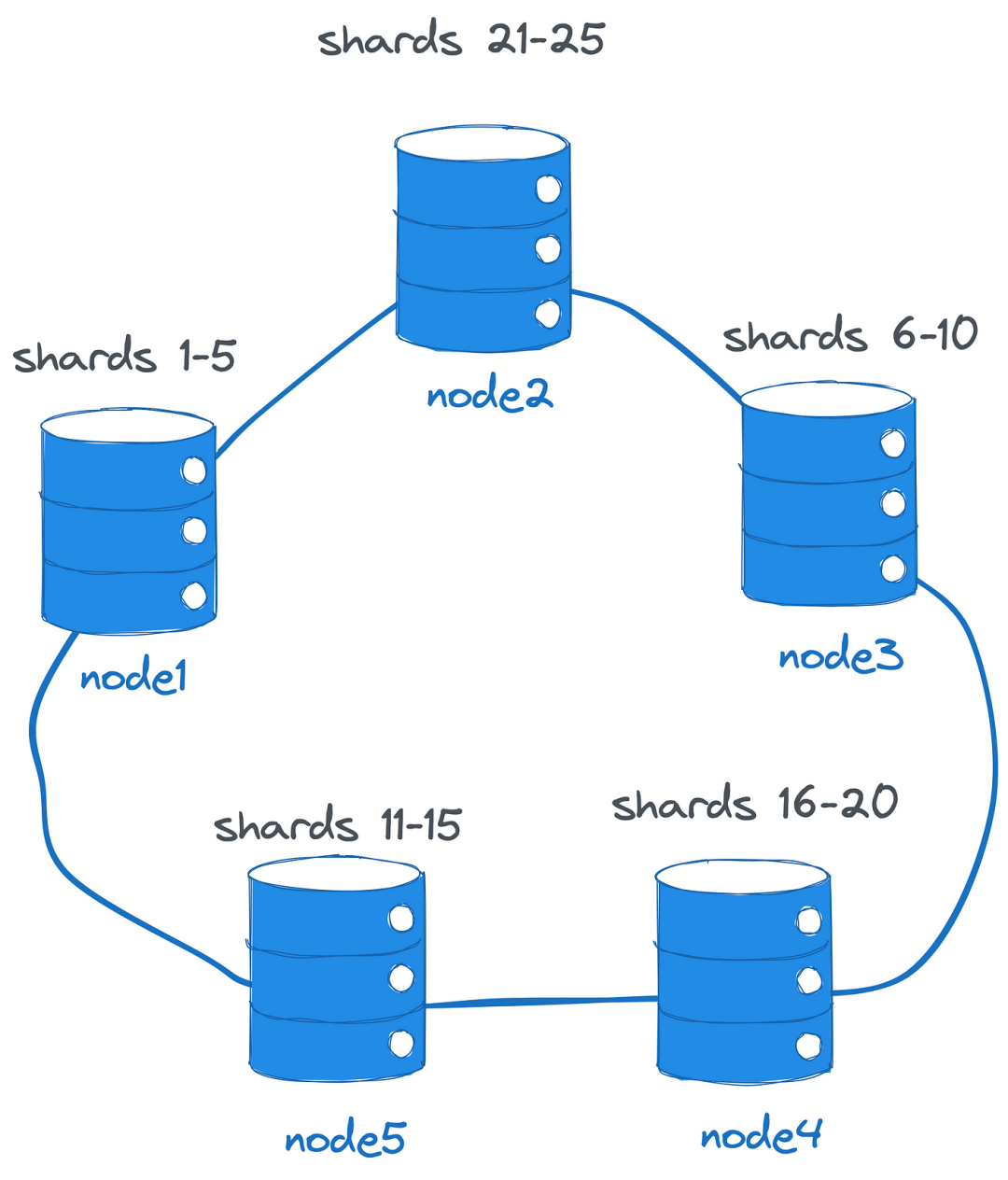
分布式数据库建立在共享无关架构上,没有像协调器这样的单一组件负担着做出许多决策:
1*deOgcXccWs9lKUSgLPNOww.png
集群中的所有节点都知道对方,因此也知道数据的分布。通过直接通信,每个节点可以将客户端请求路由到适当的分片所有者。此外,它们可以执行和协调多节点事务。当扩展到更多节点时,集群会自动重新平衡和分割分片。节点保持数据的冗余副本(基于配置的复制因子),即使某些节点失败,也可以继续操作而无需停机。
所有这些对于客户端来说是透明的,客户端只需与任何节点建立连接,然后允许该节点管理分布式方面。
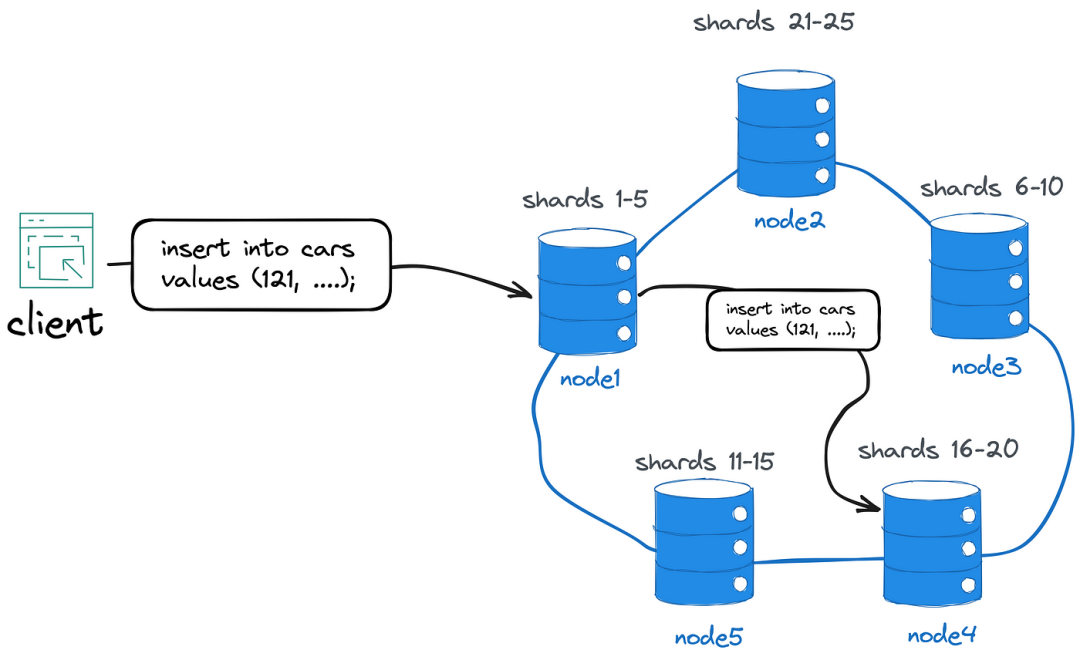
例如,客户端可能连接到node1并插入具有id121的新的Car记录。如果node1是记录分片的所有者,则它将在本地存储记录,并使用共识算法将更改复制到其他节点的子集。如果不是,node1将记录转发到分片的所有者,可能是node4。
1*weEdq2BxIpf6GiLjipns5Q.png
如果您有兴趣探索真正分布式数据库的架构,请考虑研究Google Spanner,YugabyteDB,CockroachDB,Apache Cassandra或Apache Ignite。
在数据库领域,分片和分布经常被混为一谈,但它们有着不同的目的。
虽然分片涉及将数据分割到多个独立的实例中,但这并不意味着系统本质上是分布式的。分片解决方案中协调器的存在,该协调器指导客户端请求到适当的分片,突显了这一区别。
另一方面,建立在共享无关架构上的分布式数据库缺乏这种集中式协调器。这些系统中的节点都知道对方,管理数据分布,并无缝处理客户端请求。
这两种架构都有其优点,了解它们的细微差别对于进行数据库设计和选择至关重要。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!