当python词云遇到网易云民谣
前言
词云,就是用文字词语来生成各种有趣的可视化图片。在python中使用wordcloud模块来实现词云。
采集数据
构建词云首先需要文本数据,很多时候我们都是将分好的词语,或者大段落的文本存放到本地文件中,然后在程序中完成分词,最后用来构建词云。
作为一个资深网抑云患者,数据这一块,我打算用网易云民谣的评论作为文本输入。其中就有我比较喜欢的这首《玫瑰》。
这首歌一共接近8W条评论,我们就用爬虫技术来对部分评论做数据爬取。爬虫这一块代码我知道大家不爱看,所以直接将爬取结果放出来。
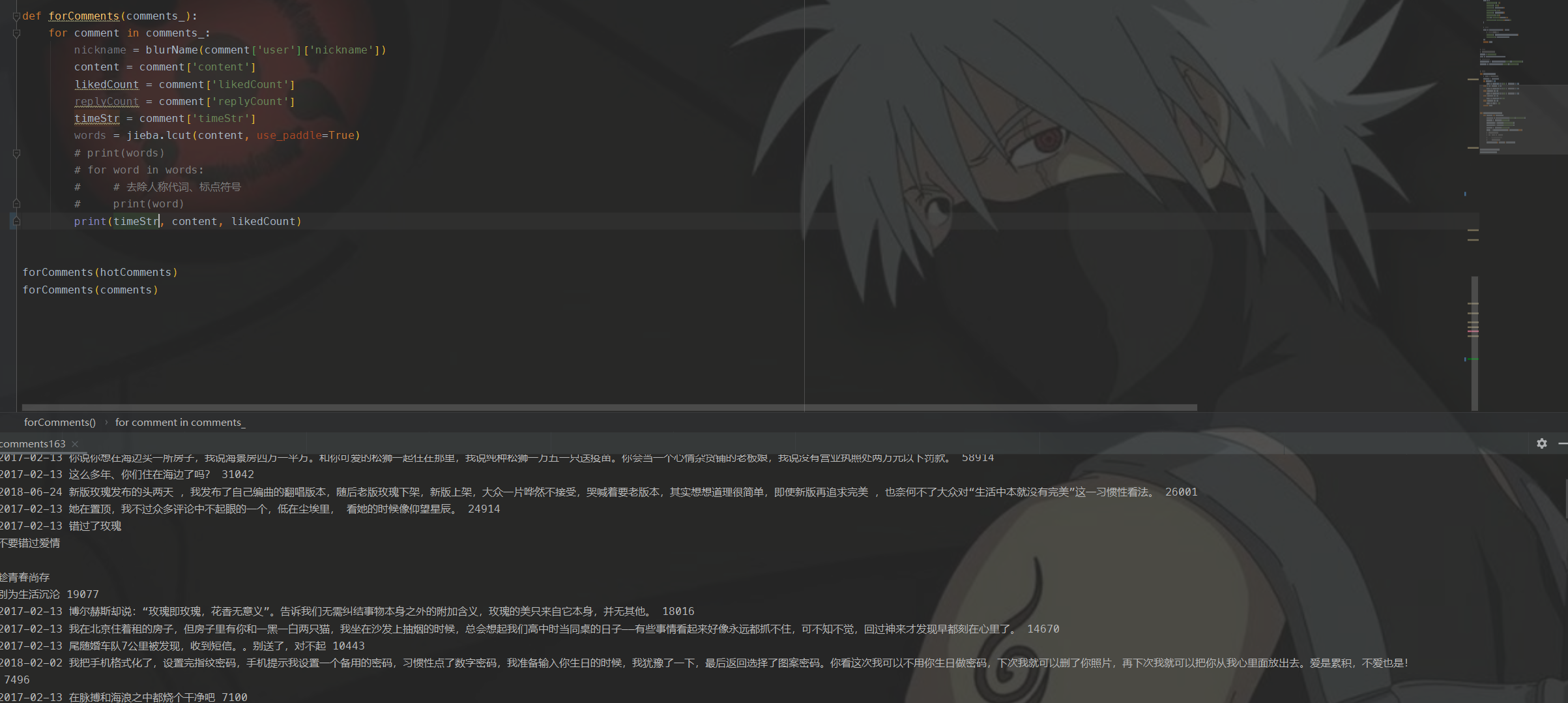
上面是一条条原始未处理的评论,后面我们会完成分词、无效词语剔除等操作。
分词
分词使用的是jieba模块,对每条评论内容进行分词。在将评论内容分割为一个个词语的同时,像一些人称代词、数字以及“的、地”词语,需要去掉。最后一些名词、动词、形容词才是我们需要的目标单词。
jieba提供了很多分词的方法,这里我使用的是jieba.posseg完成分词和词性标注,核心代码如下:
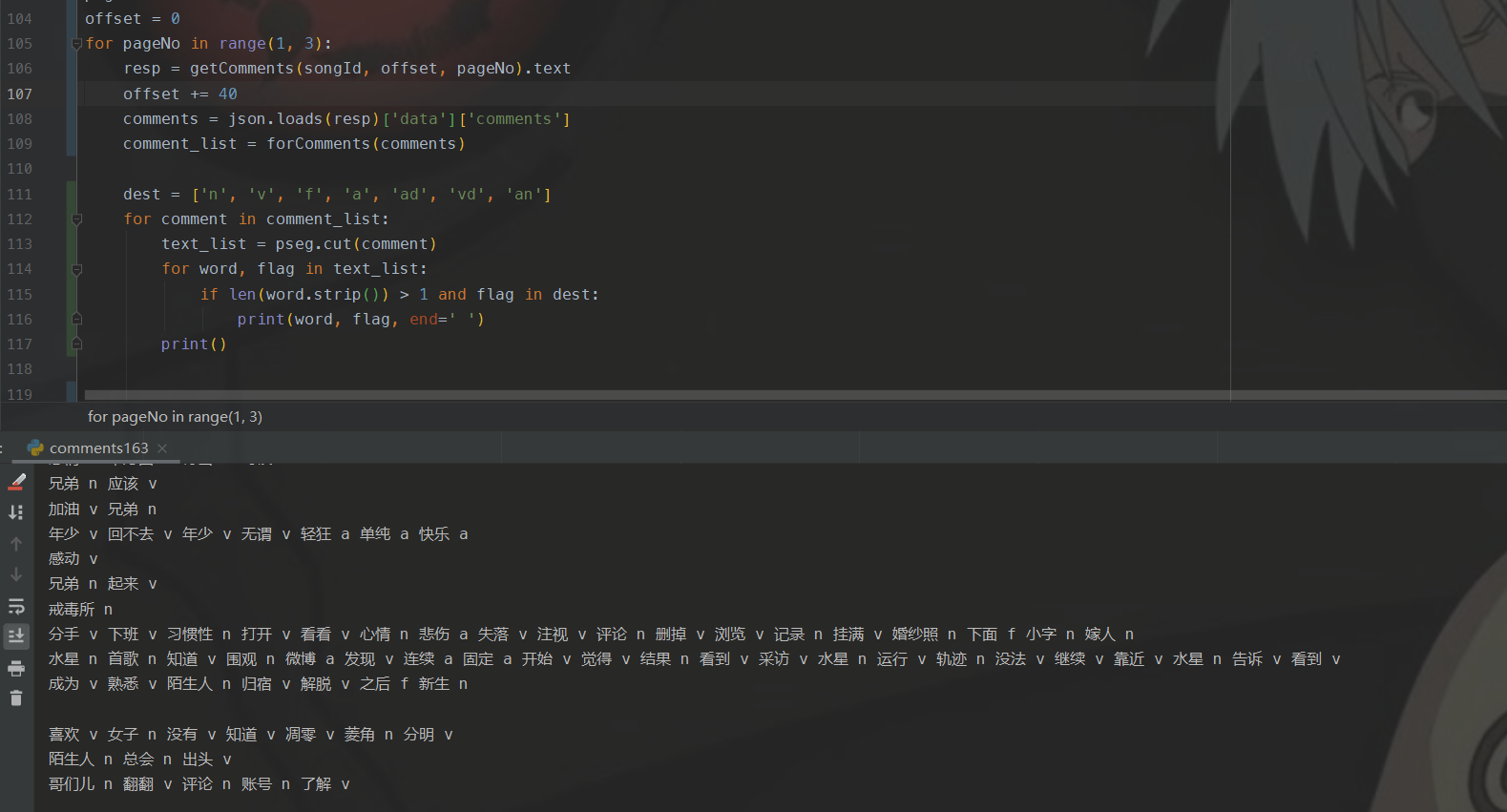
- getCommnets():爬取网易云评论
- forComments():解析爬取的评论json
- dest定义了目标词性,例如n表示名词,v表示动词
- pesg是jieba.posseg的别名,cut完成分词和词性标注
生成图云
将分词好的数据筛选之后,存放到list中,然后使用空格分割每个单词。
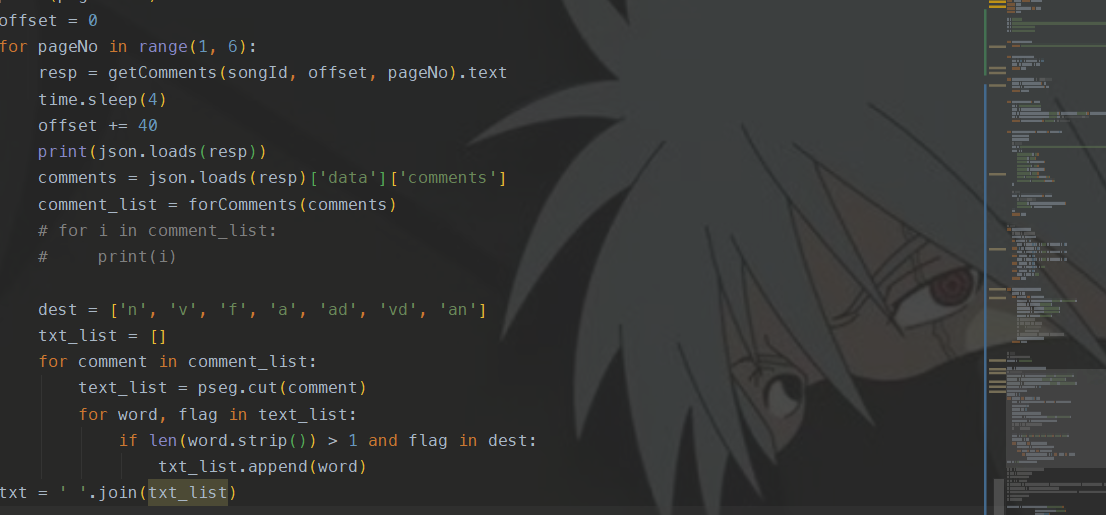
1. 基本图云
然后通过WordCloud构建基本的图云。
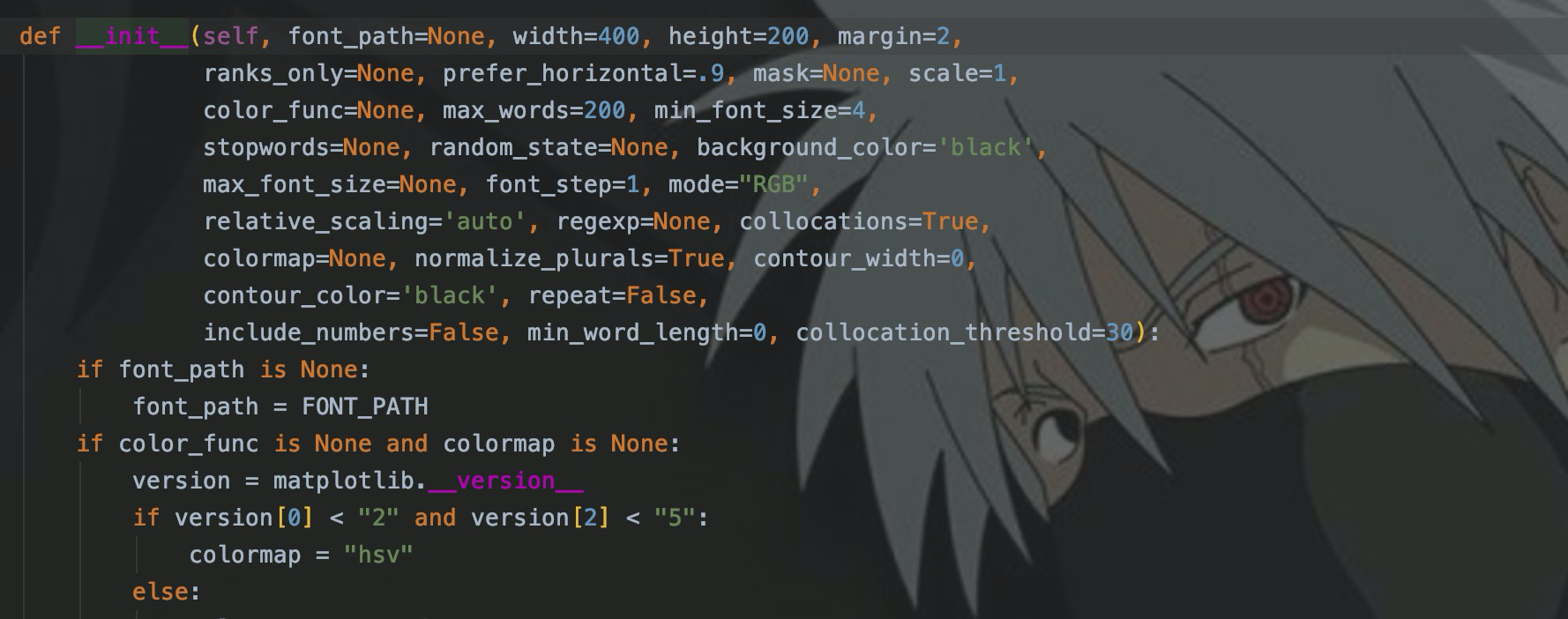
WordCloud的参数有很多,我们这里只设置字体、图云背景颜色、图云宽和高。
wordcloud = WordCloud(font_path="simsun.ttc",
background_color="white",
height=1000,
width=800,
random_state=42)
wordcloud.generate(txt)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
其中,random_state用来控制每次运行程序,生成的图云都是一样的。这里使用的字体是宋体,txt是处理后的网易云评论的文本。使用matplotlib模块来展示图云。

这样,一张简单的词云就构建完成了,单词的大小根据词语出现的频次进行展示。
2. 以图片为背景
还有一种就是以图片为背景,图云的形状、颜色会根据背景图片生成。
im = Image.open('123.jpeg')
pic = np.array(im)
w, h = im.size
wordcloud = WordCloud(mask=pic, background_color='white', random_state=42, max_words=20000, max_font_size=60, scale=10, height=h, font_path='xknlt.ttf').generate(txt)
image_colors = ImageColorGenerator(pic)
plt.imshow(wordcloud.recolor(color_func=image_colors), interpolation='bilinear')
plt.axis("off")
plt.show()
这个是用作图云背景的图片,字体使用的是小可奶酪体,字体颜色设置为image_colors。

下面是运行程序后生成的图云:

图片使用PS抠图之后再用作背景。在运行程序时,在Image.py中报MemoryError的错误,后来用PS将图像尺寸缩小了一半之后,程序就能正常运行了。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!