为 Compose MultiPlatform 添加 C/C++ 支持(3):实战 Desktop、Android、iOS 调用同一个 C/C++ 代码
theme: serene-rose
前言
在本系列的前两篇文章中我们已经学会了如何在 kotlin native 平台(iOS)使用 cinterop 调用 C/C++ 代码。以及在 jvm 平台(Android、Desktop)使用 jni 调用 C/C++ 代码,并且知道了如何自动编译 Android 端使用的 jni 代码给 Desktop 使用。
那么,我们还犹豫什么呢,是时候把它们都组合在一起,完成真正的 Compose MultiPlatform 全平台调用 C/C++ 了。
在本文中我们将以我去年使用 Compose 写的安卓端的一个简单的小游戏 demo 举例。(终于换项目举例了,哈哈哈)
项目地址:life-game-compose 。
准备工作
在正式开始之前,我们需要先简单的了解一下这个项目,可以看我之前写的这两篇介绍文章:基于 jetpack compose,使用MVI架构+自定义布局实现的康威生命游戏 、使用compose实现康威生命游戏之二:我是如何将计算速度缩减将近十倍的 。
简单介绍一下就是这是个模拟"细胞演化"的小游戏,随着时间的推移,其中的细胞会因为周围的环境(周围细胞数量)而死亡或继续存活。
而在我这个 demo 中,关于细胞状态的逻辑运算使用的是 C 语言写的,因为这部分是动画的帧间计算,对运算速度的要求比较高,使用 C 来实现速度将大幅提升。
当然,这只是我去年测试时的情况,今年当我重新测试时,发现其实在一般设备上直接使用 kotlin 运算的速度和调用 C 运算的速度实际上相差无几,甚至使用 kotlin 比调用 C 更快。
这并不是因为 kotlin 速度真的比 C 快,只是因为如果想要调用 C 的话,需要首先将 kotlin 的数据类型转为 C 中可用的数据类型,时间大多数耗在了数据类型转换上。说句不好听的,有转数据的这个功夫,我直接拿 kotlin 算都已经算出结果来了。
也许你也会说,那我不转数据可以吗?
欸,还真可以。只是对于我们这篇文章要讲的情况不可以,因为我们想要实现的是同一套 C 代码,提供给不同的平台使用,显然 cinterop 和 jni 对于 kotlin 的数据类型与 C 之间的数据类型映射不一样,因此我们为了实现通用性,只能在将数据传递给 C 之前先转为通用的数据类型。
(以上表述比较片面,也不太准确,后文会有详细的解释)
上面说了这么多,只是想叠个 buff ,那就是我们这里使用的这个项目用于举例并不是很恰当,因为这反而会让程序的性能下降。
但是用于理解如何实现在 KMP 中调用 C/C++ 还是非常有用的,权当是抛砖引玉。
最后,上面提到过,原本这个项目只是个 Android 项目,所以在开始我们今天的修改之前,需要先把它移植为 KMP 项目,这里就不再赘述了,因为之前很多篇文章都有说过怎么移植,需要的可以自行翻阅我之前的历史文章。
开始修改
项目整体结构
开始之前,我们先来看看修改完成之后的项目整体结构,需要重点关注的是图中圈起来的部分:
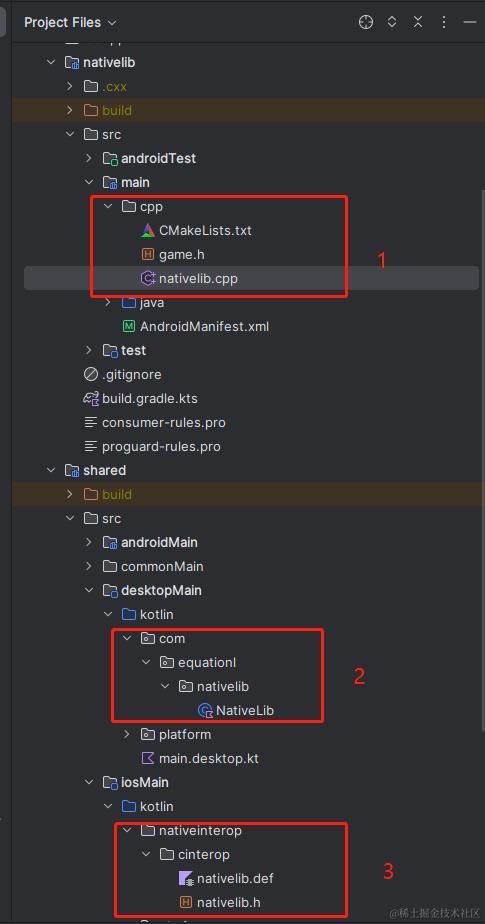
其中 圈1 是项目的 nativelib 模块,这个模块实际上是一个 Android native library 模块,但是我们这里把核心运算代码直接放到这个模块里面了。
game.h 文件即我们需要的算法的具体实现。
nativelib.cpp 是提供给 jni (Android、Desktop)调用的入口函数。
圈 2 是 Desktop 实现调用上述 C++ 代码编译成的二进制库的 kotlin 代码。
圈 3 是 iOS 使用 cinterop 实现调用上述 C++ 算法的入口函数。
接下来,我们挨个看它们的具体代码和需要注意的地方。
核心算法实现
在 nativelib 模块下的 game.h 文件是整个项目的细胞状态运算核心代码,所有平台最终都是调用其中的 updateStep(int **board, int len1, int len2) 函数实现对细胞状态的计算,代码如下:
#ifndef LIFEGAME_GAME_H
#define LIFEGAME_GAME_H
/*
* 该算法来源如下:
*
* 作者:Time-Limit
* 链接:https://leetcode.cn/problems/game-of-life/solution/c-wei-yun-suan-yuan-di-cao-zuo-ji-bai-shuang-bai-b/
* 来源:力扣(LeetCode)
* 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
*/
void updateStep(int **board, int len1, int len2) {
int dx[] = {-1, 0, 1, -1, 1, -1, 0, 1};
int dy[] = {-1, -1, -1, 0, 0, 1, 1, 1};
for(int i = 0; i < len1; i++) {
for(int j = 0 ; j < len2; j++) {
int sum = 0;
for(int k = 0; k < 8; k++) {
int nx = i + dx[k];
int ny = j + dy[k];
if(nx >= 0 && nx < len1 && ny >= 0 && ny < len2) {
sum += (board[nx][ny]&1); // 只累加最低位
}
}
if(board[i][j] == 1) {
if(sum == 2 || sum == 3) {
board[i][j] |= 2; // 使用第二个bit标记是否存活
}
} else {
if(sum == 3) {
board[i][j] |= 2; // 使用第二个bit标记是否存活
}
}
}
}
for(int i = 0; i < len1; i++) {
for(int j = 0; j < len2 ; j++) {
board[i][j] >>= 1; //右移一位,用第二bit覆盖第一个bit。
}
}
}
#endif //LIFEGAME_GAME_H
可以看到,这是个纯粹的 C 代码,没有参杂任何涉及到平台相关的东西,因此它也是我们的共享代码部分。
具体的运算逻辑这里就不说了,我们只需要知道我们项目中的细胞状态使用一个二维整数数组存放,数组索引即为游戏中对应位置细胞的状态,其中数组内容为 0 时表示该位置细胞已死亡,1 表示该位置细胞处于存活状态。
所以该函数接收三个参数 board 、len1 、 len2 ,其中 board 即表示当前状态的二维数组,该函数会在运算中直接修改该数组的内容;len1 、 len2 分别表示数组的行长度和列长度。
了解了核心运算函数,接下来我们看看各个平台如何使用它。
jvm 使用 jni 调用核心算法
在 Android 和 Desktop 将使用 jni 调用上一小节中的 updateStep 函数。
这里我们的 Android 和 Desktop 虽然编译方式不同,但是依旧可以直接复用同一个入口函数,即 nativelib 模块中的 nativelib.cpp 文件的 Java_com_equationl_nativelib_NativeLib_stepUpdate 函数。
该函数签名如下:
extern "C" JNIEXPORT jobjectArray JNICALL
Java_com_equationl_nativelib_NativeLib_stepUpdate(
JNIEnv* env,
jobject,
jobjectArray lifeList
)
可以看到,该函数接收 3 个参数: JNIEnv* env 、 jobject、 jobjectArray lifeList ,其中前两个是 jni 的固定参数,最后一个 jobjectArray 类型的参数 lifeList 才是我们实际需要传递的参数,该函数返回的数据类型也是一个 jobjectArray。
接下来,我们看下在 kotlin 中调用这个函数的签名:
external fun stepUpdate(lifeList: Array<IntArray>): Array<IntArray>
可以看到,C 中的 jobjectArray 被映射为了 kotlin 中的 Array<IntArray> 类型。
事实上,jobjectArray 并不是 C 的类型,而是 jni 定义的一个自定义数据类型:
class _jobject {};
class _jarray : public _jobject {};
class _jobjectArray : public _jarray {};
typedef _jobjectArray* jobjectArray;
而我们的核心运算代码使用的是纯粹的 C 类型,所以这里就需要对数据类型进行一个转换。
我们来看 Java_com_equationl_nativelib_NativeLib_stepUpdate 函数的完整代码:
#include <jni.h>
#include <string>
#include <valarray>
#include "game.h"
extern "C" JNIEXPORT jobjectArray JNICALL
Java_com_equationl_nativelib_NativeLib_stepUpdate(
JNIEnv* env,
jobject,
jobjectArray lifeList
) {
// jni 数据转为 c 数据
int len1 = env -> GetArrayLength(lifeList);
auto dim = (jintArray)env->GetObjectArrayElement(lifeList, 0);
int len2 = env -> GetArrayLength(dim);
int **board;
board = new int *[len1];
for(int i=0; i<len1; ++i){
auto oneDim = (jintArray)env->GetObjectArrayElement(lifeList, i);
jint *element = env->GetIntArrayElements(oneDim, JNI_FALSE);
board[i] = new int [len2];
for(int j=0; j<len2; ++j) {
board[i][j]= element[j];
}
// 释放数组
env->ReleaseIntArrayElements(oneDim, element, JNI_ABORT);
// 释放引用
env->DeleteLocalRef(oneDim);
}
// 实际的处理逻辑
updateStep(board, len1, len2);
// C 数据转回 jni 数据
jclass cls = env->FindClass("[I");
jintArray iniVal = env->NewIntArray(len2);
jobjectArray result = env->NewObjectArray(len1, cls, iniVal);
for (int i = 0; i < len1; i++)
{
jintArray inner = env->NewIntArray(len2);
env->SetIntArrayRegion(inner, 0, len2, (jint*)board[i]);
env->SetObjectArrayElement(result, i, inner);
env->DeleteLocalRef(inner);
}
return result;
}
可以看到,在这个代码中,仅仅只有一句 updateStep(board, len1, len2); 是真正的运算代码,而剩余的代码都只是在做数据转换。
其实这里如果我们不是为了能够复用运算逻辑代码,我们完全不需要转换数据,直接在运算时使用 jni 自定义的数据类型就可以了。
我们来看这里的转换代码,有一点需要额外注意的是,在开头将 jobjectArray 转为 int **board 时,有两行我添加了注释的代码:
// 释放数组
// ① 模式 0 : 刷新 Java 数组 , 释放 C/C++ 数组
// ② 模式 1 ( JNI_COMMIT ) : 刷新 Java 数组 , 不释放 C/C ++ 数组
// ③ 模式 2 ( JNI_ABORT ) : 不刷新 Java 数组 , 释放 C/C++ 数组
env->ReleaseIntArrayElements(oneDim, element, JNI_ABORT);
// 释放引用
env->DeleteLocalRef(oneDim);
这两行代码简单理解就是在我们已经完成了将 kotlin 中传过来的 jobjectArray lifeList 复制到了 C 的 int **board 中后就释放掉 lifeList 的内存。
这里一开始我不小心把释放内存的代码写到了复制完成之前,也就是写成了:
env->ReleaseIntArrayElements(oneDim, element, JNI_ABORT);
env->DeleteLocalRef(oneDim);
board[i] = new int [len2];
for(int j=0; j<len2; ++j) {
board[i][j]= element[j];
}
而我在写这段代码时使用的是 Windows 系统,所以我当时并没有发现不妥,运行代码也没有报错,运行结果也符合预期。
只是当我在 macOS 上测试时却发现,无论我传值是什么,返回结果始终为全是 0 的数组。
为此我还调试了很久,最终在 B 大佬的帮助下才发现原来是我把释放内存写在了复制完成之前。
那么问题来了,为什么同样的代码在 Windows 上运行却没有任何问题?
我们猜测可能是 Windows 和 macOS 的内存回收策略不同,在 macOS 回收更为激进,所以在我调用释放内存后,它的内存就被立即回收了,而 Windows 回收没有这么激进,所以甚至能允许我复制完了都还没有被回收。
记住这个内存回收的问题,在后面我们还会被这个坑一次。
kotlin native 使用 cinterop 调用核心算法
在 iOS 中我们将使用 cinterop 调用核心运算函数 updateStep()。
在正式开始之前,我们插个题外话,我们先写一个更简单的 demo 来演示一下上文中提到过的内存回收策略问题的坑。
看下面的代码,
C:
#ifndef LIB2_H_INCLUDED
#define LIB2_H_INCLUDED
int** get_message(int** name, int row, int col) {
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
printf("current value from c: name[%d][%d]=%d\n", i, j, name[i][j]);
}
}
// 随便改一个值
name[1][1] = 114514;
return name;
}
#endif
kt:
@OptIn(ExperimentalForeignApi::class)
fun main() {
println("Hello, Kotlin/Native!")
val list1 = listOf(intArrayOf(0, 1, 2), intArrayOf(4, 5, 6))
val row = list1.size
val col = list1[0].size
val passList = list1.map { it.pin() }
val list2 = passList.map { it.addressOf(0) }
val newList = get_message(list2.toCValues(), row, col)
for (i in 0 until row) {
for (j in 0 until col) {
println("current value from kotlin: result[$i][$j] = ${newList?.get(i)?.get(j)}")
}
}
}
无奖竞猜,将上述代码在 Desktop native 中运行,输出结果是什么?
哈哈,不卖关子了,在 Windows 上运行输出如下:
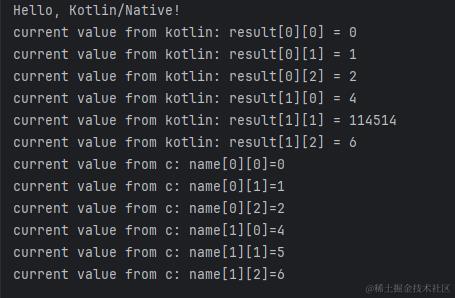
在 macOS 中输出如下:

显然,和我们上文说的内存回收策略有关。
我们先来看以上的 kt 代码,为了把 kt 的数据传递给 C ,我们使用:
val passList = list1.map { it.pin() }
val list2 = passList.map { it.addressOf(0) }
val newList = get_message(list2.toCValues(), row, col)
首先使用 pin() 函数将 kt 的 Array 中的 IntArray 地址固定以方便传递给 C 使用,然后使用 addressOf(0) 获取到 IntArray 第一个元素的地址,最后使用 toCValues() 将其转为指针引用传递给 C 的 get_message() 函数。
咋一看好像没有问题是吧?
那么,我们来看看文档中关于 toCValues() 的解释:

重点在于第一段最后一句 In this case the sequence is passed “by value”, i.e., the C function receives the pointer to the temporary copy of that sequence, which is valid only until the function returns.
换句话说就是,我们在上面代码中传递给 C 的数据只是一个拷贝的“副本”,并且这个副本数据的有效期只有函数的运行时间这么短,只要函数运行结束,这个“副本”就会被销毁。
这就不难解释为什么在 macOS 上这段代码运行结果会是这样,至于为什么同样的代码在 Windwos 上运行没有出现问题,我想还是和上一节说的原因一样,就是 Windows 和 macOS 的内存回收策略不同,在 Windows 上内存回收没有 macOS 激进,所以得以在数据本应该已经被回收了还能继续使用。
也就是说,其实我们上面代码的写法是错误的,虽然可以在 Windows 上运行,但是也是极其不可靠的,保不准数据量大时、内存紧张时、甚至在不知道的情况下随机就会出现问题。
那么,怎么解决这个问题呢?根据文档,我们需要使用 nativeHeap.alloc() 或者 nativeHeap.allocArray() 在 kotlin 代码中事先分配一段内存,然后将该内存指针传给 C 使用,此时这个内存就不会被自动释放,需要我们手动释放 nativeHeap.free() 。
当然,也可以直接使用 memScoped { ... } 语句,在该语句中分配的内存会自动在该语句结束时释放。
现在,让我们回到我们的项目中来。
首先看看 iOS 调用核心运算函数的入口 sahred 模块下的 iosMain 包中的 /nativeinterop/cinterop/nativelib.h 文件。
在该文件使用 #include "../../../../../../nativelib/src/main/cpp/game.h" 引入了 nativelib 模块的核心运算文件 game.h 。
然后定义了入口函数: int* update(int** board, int row, int col, int* newList) 。
可以看到不同于 jni 的入口函数,它多了几个参数:row 、 col、 newList 。
row 、 col 即 board 的行和列数量,因为这里传递给 C 的数组是指针的形式,所以不好确定长度,索性直接从 kotlin 传过来,而 newList 则是我们在 kotlin 中分配的内存地址的指针,用于将运算完成的结果存入。
这里我将返回类型写为了 int* 其实这里可以不用返回值,在 kotlin 直接使用传给它的 newList 指针即可,但是我只是为了保持一致性,所以把 newList 又返回回去了。
另外,这里我的返回值 newList 不使用二维数组而是使用一维数组是因为返回二维数组有点麻烦,索性转成一维来返回了。
查看 nativelib.h 函数的完整代码如下:
#include "../../../../../../nativelib/src/main/cpp/game.h"
#ifndef LIB2_H_GAME
#define LIB2_H_GAME
int* update(int** board, int row, int col, int* newList) {
updateStep(board, row, col);
// 将结果转为一维数组传回
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
int value = board[i][j];
int index = i * col + j;
newList[index] = value;
}
}
return newList;
}
#endif
对了,上述代码还有个问题,就是我在将二维数组转为一维时直接遍历了整个数组来转,这样效率非常低,完全可以直接使用 memcpy批量复制内存数据,这样会快的多。
接下来,我们来看一下 iOS 端调用这个函数的 kotlin 代码,我们在 iosMain 包中定义了一个函数 stepUpdateNative :
@OptIn(ExperimentalForeignApi::class, ExperimentalForeignApi::class)
fun stepUpdateNative(sourceData: Array<IntArray>): Array<IntArray> {
val row = sourceData.size
val col = sourceData[0].size
val list1 = sourceData.map { it.pin() }
val passList = list1.map { it.addressOf(0) }
val result = mutableListOf<IntArray>()
memScoped {
val arg = allocArray<IntVar>(row * col)
val resultNative = update(passList.toCValues(), row, col, arg)
for (i in 0 until row) {
val line = IntArray(col)
for (j in 0 until col) {
val index = i * col + j
line[j] = resultNative!![index]
// println("current value from kotlin: result[$index] = ${resultNative?.get(index)}")
}
result.add(line)
}
}
return result.toTypedArray()
}
代码很简单,重点在于中间:
memScoped {
val arg = allocArray<IntVar>(row * col)
val resultNative = update(passList.toCValues(), row, col, arg)
}
我们在 memScoped 语句中使用 allocArray<IntVar>(row * col) 分配了一块类型为 IntVar 长度为 row * col 的数组空间,然后将其作为 C 函数 update 的参数传入。
返回值 resultNative 即 C 函数运算结束后得到的一维数组结果,所以我们在后面遍历了一遍将其转回二维数组:
for (i in 0 until row) {
val line = IntArray(col)
for (j in 0 until col) {
val index = i * col + j
line[j] = resultNative!![index]
// println("current value from kotlin: result[$index] = ${resultNative?.get(index)}")
}
result.add(line)
}
简单总结一下
通过上面两个小节的讲解,相信读者也看出问题来了,这时候如果我再说调用 C 的运算速度实际上比直接使用 kotlin 还慢读者应该也恍然大悟知道什么原因了吧。
其实并不是 C 本身慢,而在于我为了在调用 C 的同时复用 C 代码,做了大量的数据转换工作,而每次数据转换的代价都是极其昂贵的,这就导致运算时间反而相比于直接使用 kt 计算还要慢了。
这也是我说的使用这个项目举例是不恰当的原因,因为这就相当于为了这碗醋还特意去大张旗鼓的包了顿饺子一样。
实际上,这系列文章只是为了说明如何在 kmp 中调用 C 代码而不需要每个平台都单独写一套适配代码。
或许在我举的这个例子中小题大做了,但是如果是调用第三方的优秀 C 项目,例如 FFmpeg ,那就是收益远大于付出。
不管怎么说,现在我们已经在所有平台中复用了同一套 C 代码,并且编写好了相应的调用函数,接下来只需要按照我前两篇文章的步骤依次将其接入我们的 KMP 项目中即可。
文章中有没有说到的地方各位读者也可以直接看我的项目代码:life-game-compose
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!