python数据分析
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
pandas统计分析基础实训
实训1 读取并查看某地区房屋销售数据的基本信息
1. 训练要点
(1)掌握CSV文件数据的读取方法
(2)掌握DataFrame的常用属性和方法
(3)掌握DataFrame的索引和切片操作
2. 需求说明
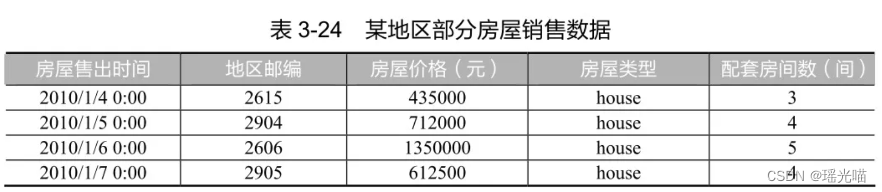
“居”是民生的重要组成部分,也是百姓幸福生活的重要保障。为了增进民生福祉,提高人民生活品质,对房地产市场进行精准调控决策,现需分析和统计某地区房屋销售数据。该地区房屋销售数据主要存放了房屋售出时间、地区邮编、房屋价格、房屋类型和配套房间数5个特征,部分数据如表 3-24 所示,其中房屋类型有普通住宅 (house)和单身公寓(unit)两种。探索数据的基本信息,通过索引操作查询到房屋类型为单身公寓的数据,同时观察数据的整体分布并发现数据间的关联。注意,地区邮编特征已完成脱敏处理,因此只存在 4位数。
3.实现思路及步骤
代码如下(示例):
# 1、使用read_csv函数读取“某地区房屋销售数据.csv”文件,创建DataFrame对象housesale
import pandas as pd
housesale=pd.read_csv('某地区房屋销售数据.csv',encoding='gbk')
print(housesale)
# 2、使用ndim、shape、columns属性分别查看数据的维度、形状以及所有特征名称
print(housesale.ndim)
print(housesale.shape)
print(housesale.columns)
# 3.使用iloc()、loc()方法对房屋类型为单身公寓(unit)的数据进行查询
housesale.loc[housesale['房屋类型']=='unit']
housesale.iloc[(housesale['房屋类型']=='unit').values,:]
实训2 提取房屋售出时间信息并描述房屋价格信息
1. 训练要点
(1)掌握时间字符串和标准时间的转换方法
(2)掌握 pandas 描述性统计方法
2. 需求说明
基于实训 1的数据,在房屋售出时间特征中存在时间数据,提取时间数据内存在的有用信息,如将“2010/1/4 0:00”转换成“2010-1-4”的形式。对时间信息的提取一方面可以加深房产销售经理对数据的理解,另一方面能够去除无意义的时间信息。此外,还可通过描述性统计分析该地区房屋的平均价格、价格区间、价格众数等,便于进一步获取该地区房屋价格信息。
3. 实现思路及步骤
# 4.使用to_datetime函数转换房屋出售时间字符串
housesale["房屋出售时间"]=pd.to_datetime(housesale["房屋出售时间"])
housesale.dtypes
# pandas描述性统计方法
# 5.使用mean、max、min、mode函数分别计算该地区房屋价格的均值、最大值、最小值和众数
print(housesale['房屋价格'].mean())
print(housesale['房屋价格'].max())
print(housesale['房屋价格'].min())
print(housesale['房屋价格'].mode())
# 使用quantile函数计算该地区房屋价格的分位数
print(housesale[['房屋价格']].quantile(.25))
print(housesale[['房屋价格']].quantile(.5))
print(housesale[['房屋价格']].quantile(.75))
# 6.使用describe()方法计算房屋价格数据的非空值数目、均值等统计量
housesale['房屋价格'].describe()
实训3 使用分组聚合方法分析房屋销售情况
1. 训练要点
(1)掌握分组聚合的步骤
(2)掌握 groupby0的使用方法。
(3)掌握 transform0、agg0、apply0聚合方法
2. 需求说明
为了解买房者购买房屋的类型喜好,需要根据房屋所在的地理位置进行分组聚合,然后进行组内和组间分析,从而为买房者提供更好的服务。基于实训 1 的数据,提取地区邮编特征中数据的前两位,如提取“2615”中的“26”,并生成 new_postcode 特征存储提取的内容,其目的是便于统计不同地区房屋价格以及房屋性价比。最后根据 new postcode 特征对数据进行分组操作,从而获取不同地区的房屋价格信息并进行比较。
3. 实现思路及步骤
# 7.使用apply()方法提取地区邮编特征中数据的前两位,如提取“2615”中的“26”,并新增new_postcode特征存储提取的内容
housesale['new_postcode']=housesale['地区邮编'].apply(lambda x :str(x)[0:2])
housesale
# 8.根据新地区邮编new_postcode进行分组,使用count函数计算出每个地区的房屋售出总数
group=housesale.groupby(by='new_postcode')
group['new_postcode'].agg('count')
# 9.使用groupby()方法对房屋类型进行分组
housesale1=housesale.groupby(by='房屋类型')
housesale1
# 10.根据房屋类型进行分组,使用transform()方法计算分组数据中房屋价格均值
housesale1['房屋价格'].transform('mean')
实训4 分析房屋地区、配套房间数和房屋价格的关系
1. 训练要点
(1)掌握透视表的制作方法
(2)掌握交叉表的制作方法
2. 需求说明
通过实训 1~3中对数据进行描述性统计、对时间数据进行信息提取和分组聚合操作已获得了相当多的信息。基于实训 1 的数据,如果需要获取更多的房屋价格信息,那么可以使用透视表和交叉表来实现。例如,比较不同地区和不同配套房间数的房屋价格、分析不同地区哪种类型的房屋价格最贵、比较不同类型房屋和不同配套房间数的房屋的价格和分析配有多少房间数的房屋最畅销等。
3. 实现思路及步骤
# 11. 使用pivot_table()函数创建数据透视表
# 比较不同地区和不同配套房间数的房屋价格
import numpy as np
housesalePivot1=pd.pivot_table(housesale[['new_postcode','配套房间数','房屋价格']],index=['new_postcode','配套房间数'],aggfunc=np.mean)
housesalePivot1
# 分析不同地区那种类型的房屋价格最贵
housesalePivot1=pd.pivot_table(housesale[['new_postcode','房屋类型','房屋价格']],index=['new_postcode','房屋类型'],aggfunc=np.max)
housesalePivot1
# 12.使用crosstab函数创建数据交叉表
# 比较不同类型房屋和不同配套房间数的房屋价格
housesaleCross1 = pd.crosstab(index=housesale['房屋类型'],columns=housesale['配套房间数'],values=housesale['房屋价格'],aggfunc=np.mean)
housesaleCross1
# 分析配有多少房间数的房屋最畅销
# typehouseSale=housesale.groupby(by='房屋类型')
housesaleCross2 = pd.crosstab(index=housesale['房屋类型'],columns=housesale['配套房间数'])
housesaleCross2
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!