基于Python的电商手机数据可视化分析和推荐系统
2023-12-30 22:47:31
1. 项目简介
本项目旨在通过Python技术栈对京东平台上的手机数据进行抓取、分析并构建一个简单的手机推荐系统。主要功能包括:
- 网络爬虫:从京东获取手机数据;
- 数据分析:统计各厂商手机销售分布、市场占有率、价格区间和好评率;
- 可视化展示:使用ECharts进行数据可视化;
- 推荐系统:根据分析结果为用户推荐手机。
基于Python的京东手机数据可视化分析和推荐系统
2. 电商手机数据网络爬虫
使用Python的requests库和BeautifulSoup库实现对京东手机页面的爬取。需要处理分页、动态加载等问题。
def getCommentData(prod_id, format_url, proc, i, maxPage):
'''
format_url: 格式化的字符串架子,在循环中给它添上参数
proc: 商品的productID,标识唯一的商品号
i: 商品的排序方式,例如全部商品、晒图、追评、好评等
maxPage: 商品的评论最大页数
'''
sig_comment = []
global list_comment
cur_page = 0
while cur_page < maxPage:
cur_page += 1
# url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv%s&score=%s&sortType=5&page=%s&pageSize=10&isShadowSku=0&fold=1'%(proc,i,cur_page)
url = format_url.format(proc, i, cur_page) # 给字符串添上参数
try:
response = requests.get(url=url, headers=comment_headers, verify=False)
time.sleep(np.random.rand() * 2)
jsonData = response.text
startLoc = jsonData.find('{')
# print(jsonData[::-1])//字符串逆序
jsonData = jsonData[startLoc:-2]
jsonData = json.loads(jsonData)
pageLen = len(jsonData['comments'])
print("当前第%s页,最大%s页" % (cur_page, maxPage))
for j in range(0, pageLen):
userId = jsonData['comments'][j]['id'] # 用户ID
# 数据解析代码
# ...........
except:
time.sleep(5)
cur_page -= 1
print('网络故障或者是网页出现了问题,五秒后重新连接')
def fetch_phone_comment(product, product_id):
print('抓取 {} 产品的评论数据。。。。。。'.format(product))
format_url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&{0}&score={1}&sortType=5&page={2}&pageSize=10&isShadowSku=0&fold=1'
list_comment = []
sig_comment = []
proc = 'productId={}'.format(product_id)
i = -1
while i < 7: # 遍历排序方式
i += 1
if (i == 6):
continue
# 先访问第0页获取最大页数,再进行循环遍历
url = format_url.format(proc, i, 0)
print(url)
try:
response = requests.get(url=url, headers=comment_headers, verify=False)
# 数据解析代码
# ...........
getCommentData(proc, format_url, proc, i, jsonData['maxPage']) # 遍历每一页
except Exception as e:
i -= 1
print("the error is ", e)
time.sleep(5)
return list_comment
def fetch_brand_phones(brand_name, brand_href):
""" 抓取该品牌的手机数据 """
page = 1
size = 1
while page < 10:
brand_page_href = brand_href + '&page={}&s={}&click=0'.format(page, size)
resp = requests.get(brand_page_href, headers=headers)
soup = BeautifulSoup(resp.text, 'lxml')
items = soup.find_all('li', attrs={'class': 'gl-item'})
all_phones = []
for item in items:
# 图片
# 价格
# 手机产品名称
# 产品的详细链接
# 抓取该产品的详细信息,此处为销量
# 数据解析代码
# ...........
phone = {
'品牌': brand_name,
'图片': img,
'价格': price,
'产品名称': name,
'链接': phone_href,
'评论': json.dumps(comment_dict, ensure_ascii=False)
}
all_phones.append(phone)
3.?电商手机数据可视化分析和推荐系统
3.1 首页与注册登录

3.2?各厂商手机销售分布
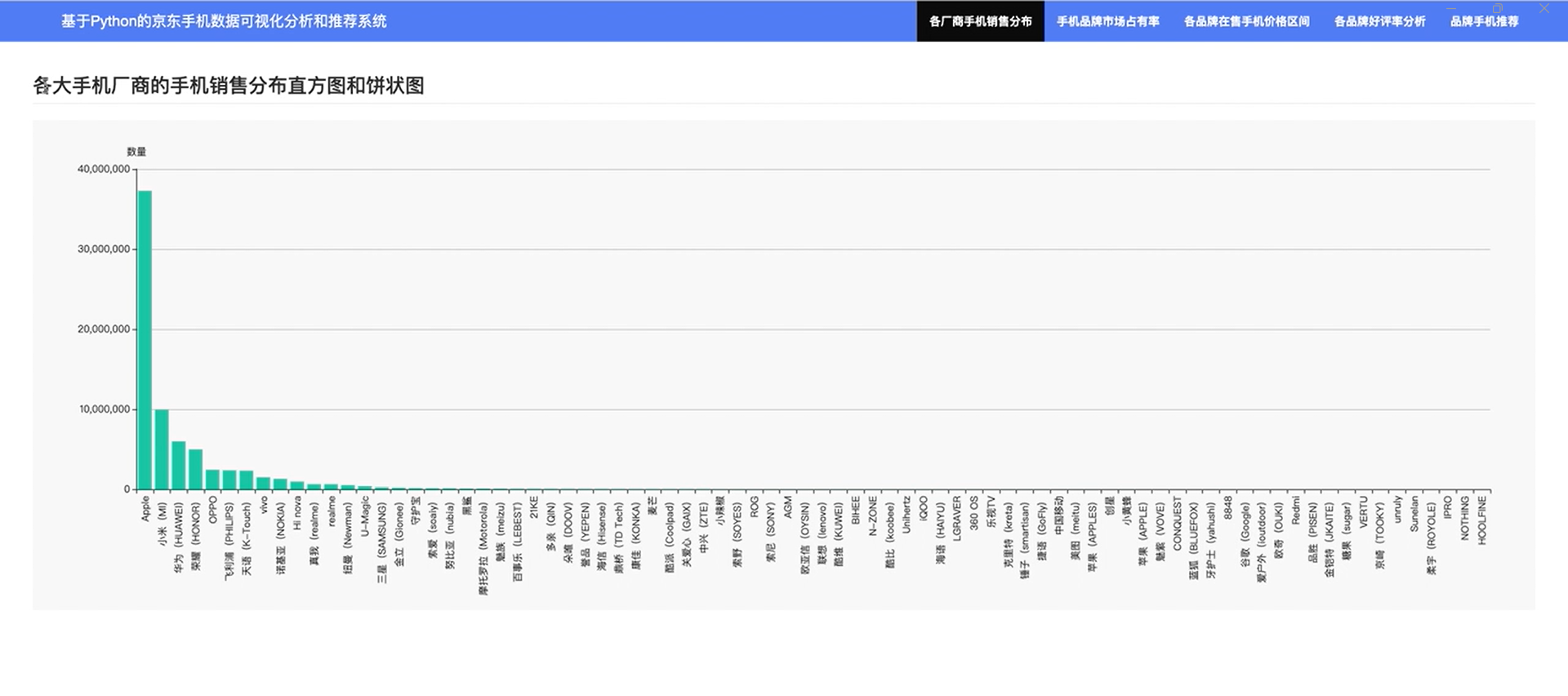
3.3?手机品牌市场占有率
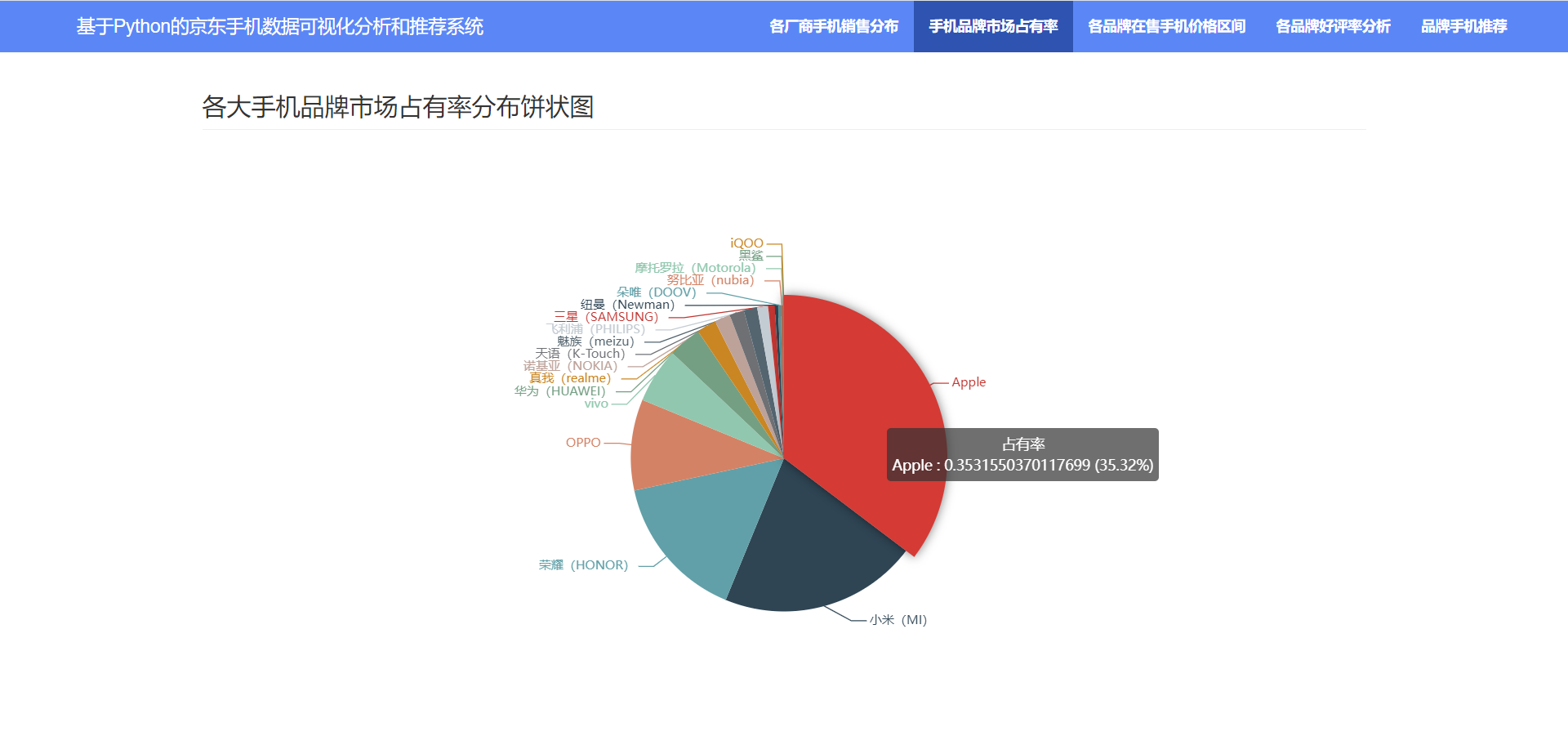
3.4 各品牌在售手机价格区间
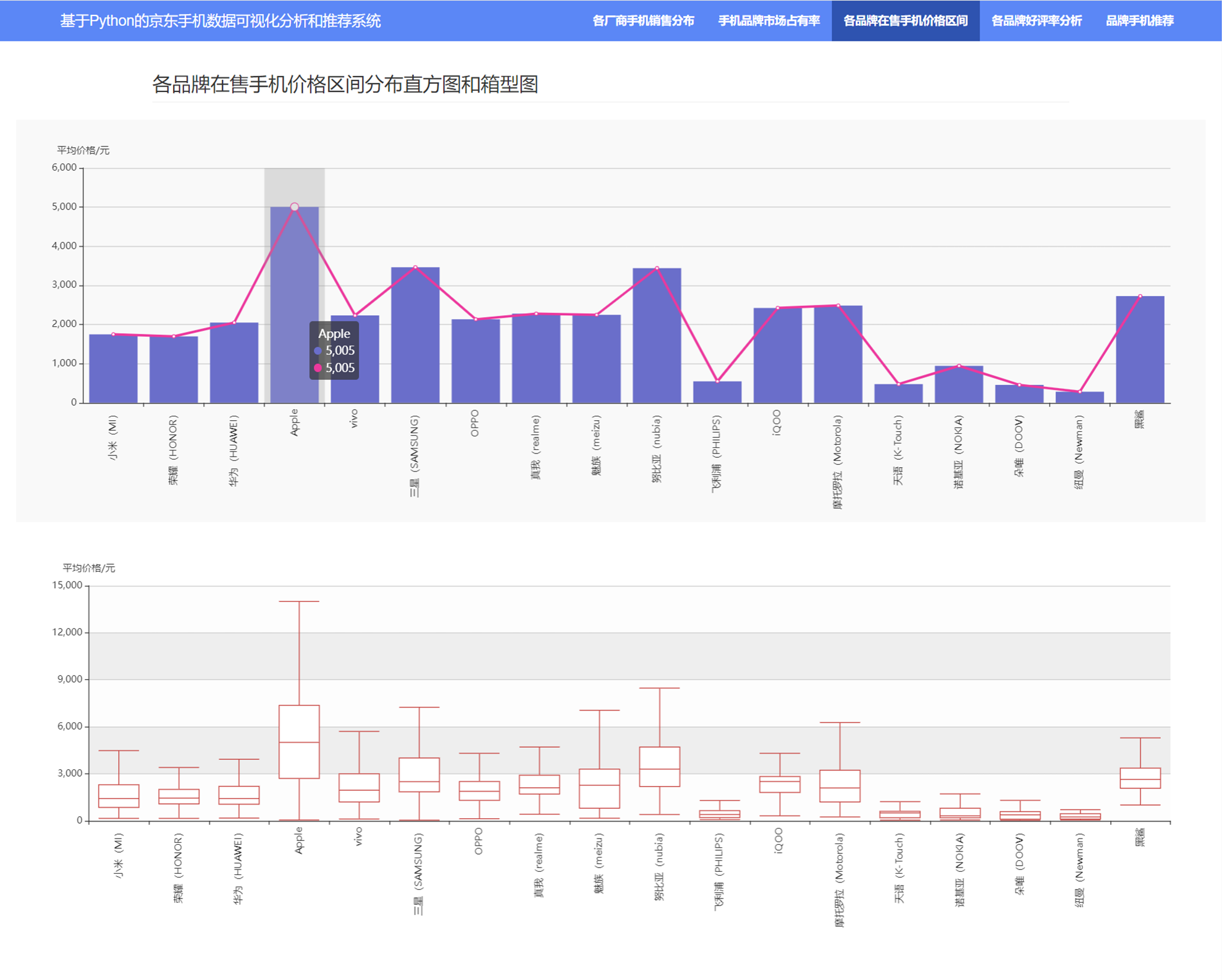
3.5 各品牌好评率分析
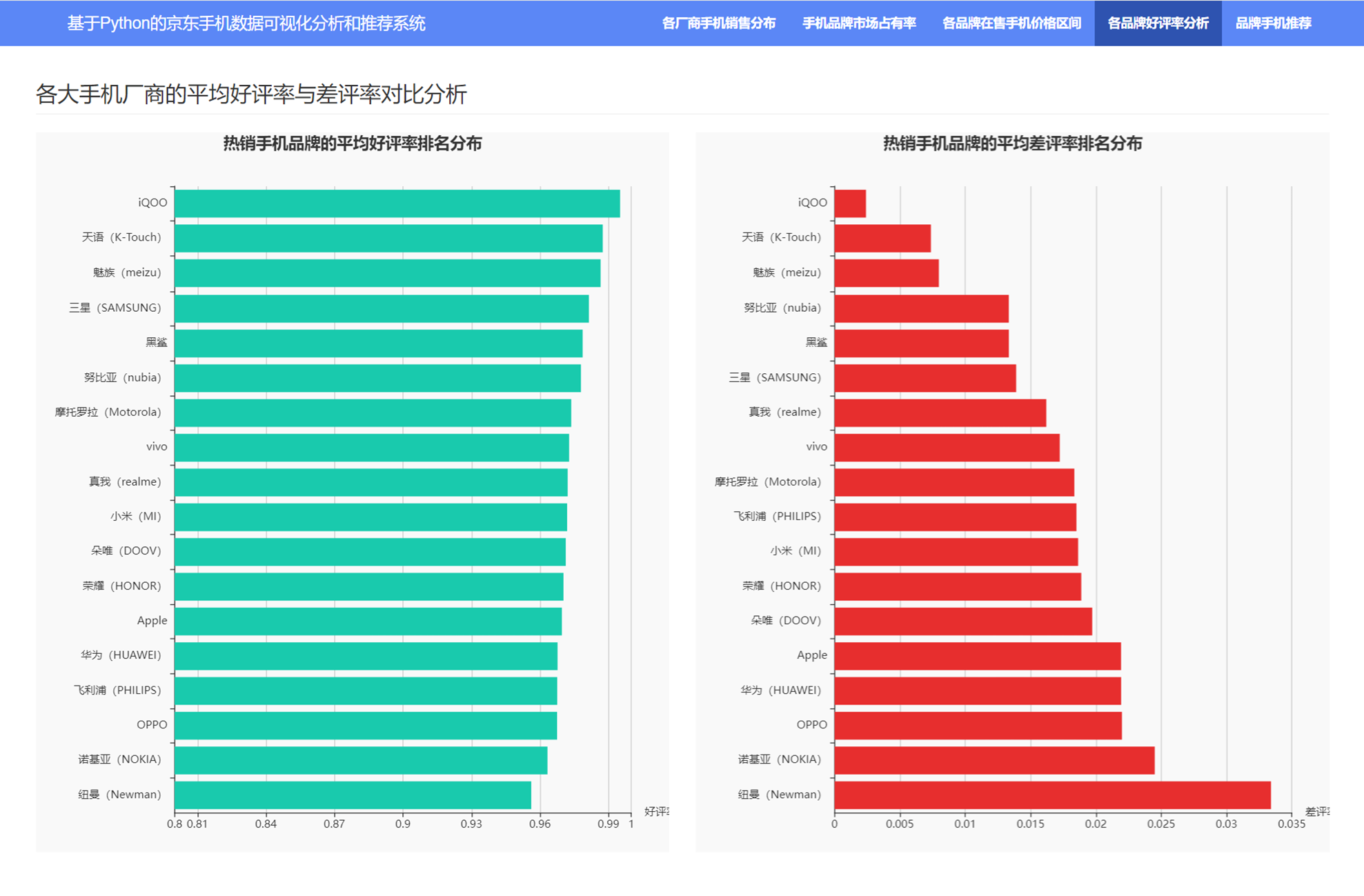
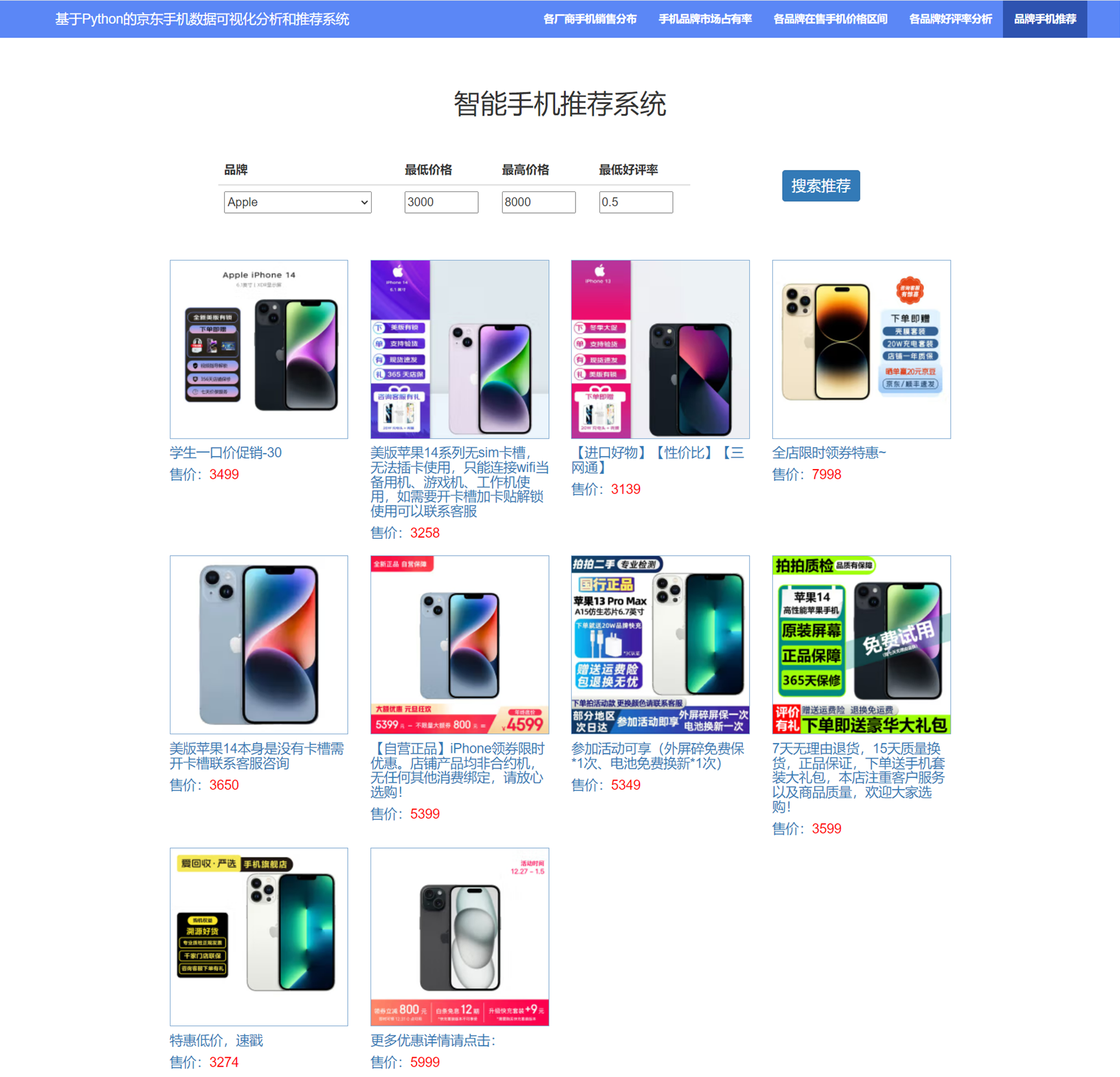
3.6 品牌手机推荐
6. 总结
????????本项目利用Python强大的数据处理能力,结合网络爬虫技术,对京东手机数据进行了有效的抓取和分析,并通过可视化手段直观展示了分析结果。同时,通过简单的推荐算法,实现智能手机推荐系统。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取认准下方?CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:

文章来源:https://blog.csdn.net/andrew_extra/article/details/135310129
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!