【Python】Numpy库近50个常用函数详解和示例,可作为工具手册使用
本文以yolo系列代码为基础,在其中查找用到的numpy函数,包含近50个函数,本文花费多天,三万多字,通过丰富的函数原理和示例对这些函数进行详解。以帮助大家理解和使用。
目录
- np.array()
- np.asarray()
- np.random.uniform()
- np.arange()
- np.clip()
- np.append()
- np.mod()
- np.eye()
- np.zeros()
- np.ones()
- np.concatenate()
- np.random.beta()
- np.maximum()
- np.maximum.accumulate()
- np.minimum()
- np.full()
- np.ascontiguousarray()
- np.random.seed()
- np.stack()
- np.unique
- np.zeros_like
- np.save ()
- np.load ()
- np.floor()
- np.ceil()
- np.flipud()
- np.fliplr()
- np.hstack()
- np.vstack()
- np.bincount()
- np.argmax()
- np.argmin()
- np.argsort()
- np.set_printoptions()
- np.loadtxt()
- np.linspace()
- np.copy()
- np.interp()
- np.ndarray()
- np.fromfile()
- np.convolve()
- np.trapz()
- np.where()
- np.sum()
- np.nan()
- np.log()
- np.linalg.lstsq()
- np.empty()
- 结束语
np.array()
np.array()函数是NumPy库中创建数组的主要方法,它接受一组参数,每个参数都可以是数组,公开数组接口的任何对象,或者任何(嵌套)序列。
np.array()函数的作用是将输入的对象(或对象序列)转换为一个新的NumPy数组。
函数原型:
numpy.array(object, dtype=None, copy=True, order='K', subok=False, ndmin=0)
参数详解:
object:可以是一个列表、元组、字典或者另一个 NumPy 数组。也可以是公开数组接口的任何对象,或者任何(嵌套)序列。
dtype:可选参数,用来指定数组元素的类型。例如,np.array([1, 2, 3]) 默认情况下元素的类型是 int,但如果你指定了 dtype=np.float32,那么元素类型就会变成 float32。
copy:可选参数,默认为 True。如果为 True,那么会创建一个新的数组,复制输入的对象。如果为 False,那么可能会共享数据,即改变原数据也会影响返回的数组。
order:可选参数,默认为 'K'。这决定了数据的存储顺序。'K' 代表 Fortran 的存储顺序(行优先),'C' 代表 C 的存储顺序(列优先)。
subok:可选参数,默认为 False。如果为 True,那么返回的数组将是输入对象的子类。如果为 False,那么返回的数组将是基类数组。
ndmin:可选参数,默认为 0。这决定了返回的数组的最小维度数。例如,如果你指定了 ndmin=2,那么即使输入的是一个标量,也会返回一个一维数组。
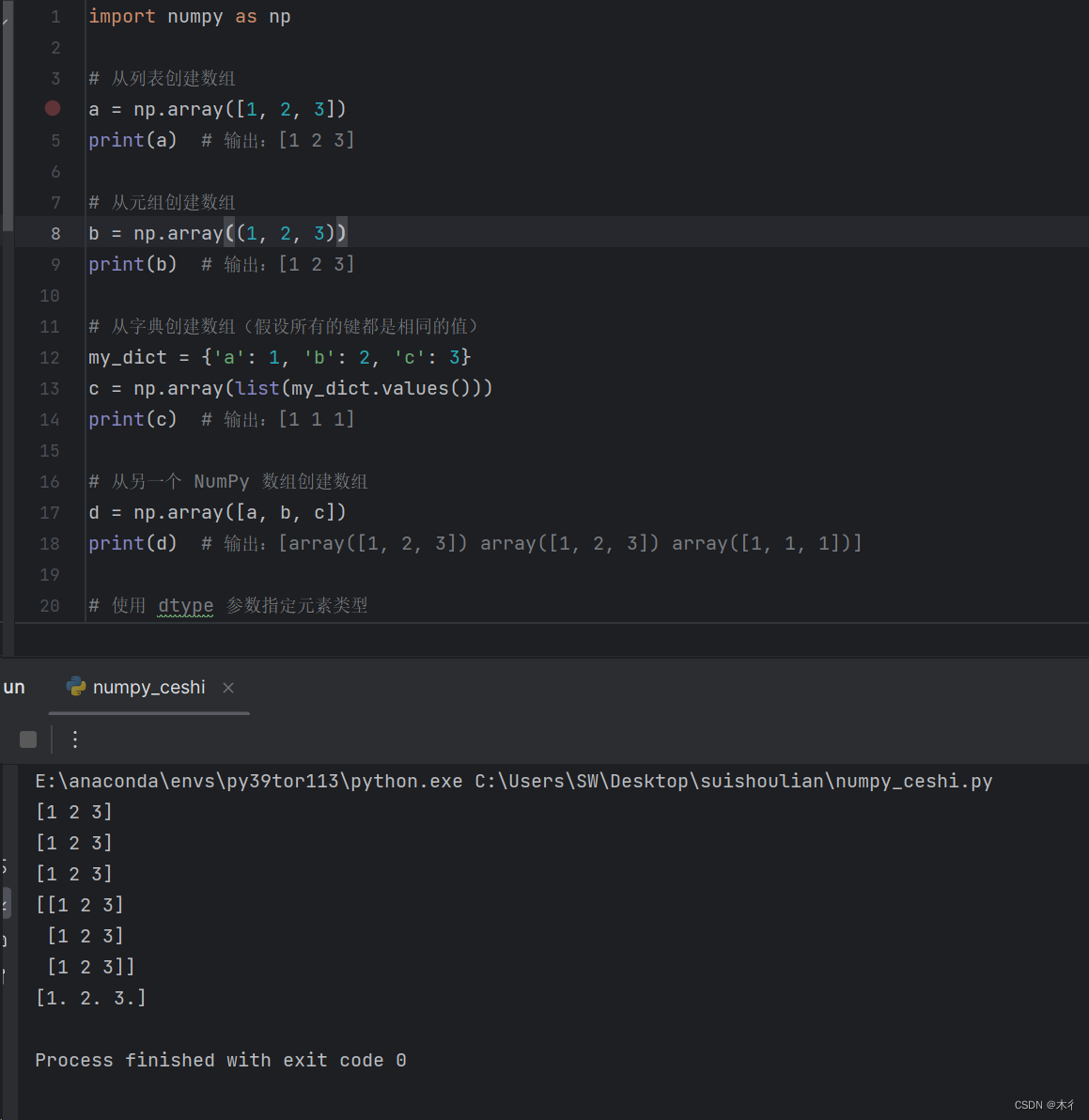
运行示例
import numpy as np
# 从列表创建数组
a = np.array([1, 2, 3])
print(a) # 输出:[1 2 3]
# 从元组创建数组
b = np.array((1, 2, 3))
print(b) # 输出:[1 2 3]
# 从字典创建数组(假设所有的键都是相同的值)
my_dict = {'a': 1, 'b': 2, 'c': 3}
c = np.array(list(my_dict.values()))
print(c) # 输出:[1 1 1]
# 从另一个 NumPy 数组创建数组
d = np.array([a, b, c])
print(d) # 输出:[array([1, 2, 3]) array([1, 2, 3]) array([1, 1, 1])]
# 使用 dtype 参数指定元素类型
e = np.array([1, 2, 3], dtype=np.float32)
print(e) # 输出:[1. 2. 3.]
np.asarray()
np.asarray 是 NumPy 库中的一个函数,用于将一个具有不同类型的数据集合(例如 Python 列表、元组或 NumPy 数组)转换为一个 NumPy 数组。
函数解析
函数原型:
numpy.asarray(a)
参数:
a:一个可迭代对象(例如 Python 列表、元组或其他 NumPy 数组)。
返回值:
返回一个新的 NumPy 数组,其中包含 a 中的数据,但以 NumPy 数组的形式表示。
注意事项:
如果 a 已经是一个 NumPy 数组,那么 np.asarray 不会进行任何转换,直接返回该数组。
如果 a 是一个 Python 列表或其他不可直接转换为 NumPy 数组的对象,np.asarray 会尝试将其转换为 NumPy 数组。
如果 a 是一个可迭代对象,但其中的元素不是同一种类型,那么 np.asarray 将返回一个 object 类型的数组,其中包含原始对象的引用。
运行示例
列表转换为 NumPy 数组
import numpy as np
list1 = [1, 2, 3, 4, 5]
arr1 = np.asarray(list1)
print(arr1)
输出:
[1 2 3 4 5]
元组转换为 NumPy 数组
import numpy as np
tuple1 = (1, 2, 3, 4, 5)
arr2 = np.asarray(tuple1)
print(arr2)
输出:
[1 2 3 4 5]
np.random.uniform()
np.random.uniform() 是 NumPy 库中的一个函数,用于生成一个指定形状的数组,数组元素的值均匀分布在指定的范围内。
函数解析
函数原型:
np.random.uniform(low, high, size)
参数详解:
low:生成随机数的最小值(含)。默认为0。
high:生成随机数的最大值(不含)。不能小于 low。默认为1。
size:生成的随机数数组的形状。可以是正整数、负整数或零,分别代表的形状为(n,),(n,n),(n,n,n)等。默认为None,代表生成的随机数数组形状为一个。
返回值:生成的随机数数组。
运行示例
(1)生成一个元素范围在0到1之间的随机数数组,形状为(3,):
import numpy as np
print(np.random.uniform(0, 1, 3))
输出的一种:
[0.59394381 0.64440999 0.91008711]
(2)生成一个元素范围在1到10之间的随机数数组,形状为(2,2):
import numpy as np
print(np.random.uniform(1, 10, (2, 2)))
输出的一种:
[[7.2666767 6.93297231]
[9.65006062 8.67068568]]
np.arange()
np.arange() 是 NumPy 库中的一个函数,用于生成一个包含一定范围内整数的数组。这个函数在 Python 的内置 range() 函数的基础上提供了更多的灵活性和功能。
函数解析
函数原型为:
np.arange([start,] stop[, step,], dtype=None)
参数详解:
start:起始值。默认为0。
stop:结束值。生成的数组将包含到此值之前的所有整数。请注意,数组的最后一个元素将是 stop-1。
step:步长。默认为1。生成的数组的每个元素之间的差值就是这个步长。
dtype:可选参数,生成的数组的数据类型。如果未指定,则默认为当前 NumPy 数据类型。
返回值:一个包含一定范围内整数的 NumPy 数组。
运行示例
(1)生成从0到9(包含0,不包含10)的整数数组,步长为2:
import numpy as np
print(np.arange(0, 10, 2))
输出:
[0 2 4 6 8]
(2)生成一个长度为10的数组,元素从1开始,到100结束(不包含100),步长为10:
import numpy as np
print(np.arange(1, 100, 10))
输出:
[ 1 11 21 31 41 51 61 71 81 91]
np.clip()
np.clip()是NumPy库中的一个函数,它用于将数组中的元素限制在指定的范围内。这个函数接受两个参数,即最小值和最大值,所有超过这个范围的元素都会被限制在这个范围内。
函数解析
函数原型为:
np.clip(a, a_min, a_max)
参数详解:
a:输入数组。
a_min:限制下限。所有小于a_min的a中的元素将被替换为a_min。
a_max:限制上限。所有大于a_max的a中的元素将被替换为a_max。
返回值:一个新的数组,其中的元素被限制在a_min和a_max之间。
运行示例
import numpy as np
# 创建一个随机数组
arr = np.random.rand(5) * 100
print("Original array:", arr)
# 使用np.clip()将数组中的元素限制在0到10之间
clipped_arr = np.clip(arr, 0, 10)
print("Clipped array:", clipped_arr)
输出:
Original array: [89.01030861 7.78381296 52.43930124 70.35602011 62.99517335]
Clipped array: [10. 7.78381296 10. 10. 10. ]
在这个示例中,原始数组中的元素被限制在0到10之间。所有超过这个范围的元素都被替换为对应的边界值(小于0的元素被替换为0,大于10的元素被替换为10)。
np.append()
np.append() 是 NumPy 库中的一个函数,它用于将一个或多个数组添加到另一个数组的末尾。这个函数不会改变原始数组,而是返回一个新的数组。
函数解析
函数原型为:
np.append(arr, values[, axis])
参数详解:
arr:要添加其他数组的数组。
values:要添加到 arr 的数组或列表。这可以是多个数组或列表。
axis:可选参数,定义了 values 中的数组沿着哪个轴添加到 arr 中。默认值为 None,这意味着 values 中的数组将被展平并添加到 arr 的末尾。如果指定了 axis,则 values 中的数组将被添加到 arr 的指定轴上。
运行示例
不使用 axis 参数:
import numpy as np
arr = np.array([1, 2, 3])
values = np.array([4, 5, 6])
appended_arr = np.append(arr, values)
print(appended_arr)
输出:
[1 2 3 4 5 6]
使用 axis =0:
import numpy as np
arr = np.array([[1, 2], [3, 4]])
values = np.array([5, 6])
# 将 values 转换为二维数组
values_2d = np.reshape(values, (1, -1))
appended_arr = np.append(arr, values_2d, axis=0)
print(appended_arr)
输出:
[[1 2]
[3 4]
[5 6]]
使用 axis =1
import numpy as np
arr = np.array([[1, 2], [3, 4]])
values = np.array([5, 6])
# 将 values 转换为二维数组
values_2d = np.reshape(values, (-1, 1))
appended_arr = np.append(arr, values_2d, axis=1)
print(appended_arr)
输出:
[[1 2 5]
[3 4 6]]
注意:按照行或列拼接时注意要相同的维度,0是行拼接,1是列。
np.mod()
np.mod() 是 NumPy 库中的一个函数,它用于计算两个数的模(余数)。该函数的语法为 np.mod(x, y),其中 x 和 y 是要计算模的两个数。
函数解析
函数的工作方式与 Python 内置的 % 运算符类似,但有一个重要的区别:np.mod() 函数可以处理浮点数和非整数,而 Python 的 % 运算符只能处理整数。
运行示例
import numpy as np
x1 = np.array([10, 10.5])
x2 = np.array([3, 3.2])
result = np.mod(x1, x2)
print(result)
输出:
[1. 0.9]
在上面的示例中,我们使用 np.mod() 函数计算了 x1 对 x2 的模,并将结果存储在 result 数组中。
np.eye()
函数解析
函数原型:
np.eye(n, m=None, k=0, dtype=<class 'NoneType'>)
参数:
n:整数,表示要生成的单位矩阵的行数或列数,取决于是否指定了m参数。如果m未指定,则n既是行数也是列数。
m:整数,表示要生成的单位矩阵的列数或行数,取决于是否指定了n参数。如果n未指定,则m既是列数也是行数。
k:整数,表示对角线偏离中心的偏移量。默认值为0,表示对角线居中。
dtype:数据类型,默认为None。如果指定了数据类型,则生成矩阵的数据类型将被指定为该类型。
该函数返回一个单位矩阵,其中对角线上的元素为1,其他位置的元素为0。通过调用 np.eye(),我们可以创建不同大小和维度的单位矩阵。
运行示例
创建2*2矩阵
mport numpy as np
identity_matrix = np.eye(2)
print(identity_matrix)
输出:
[[1. 0.]
[0. 1.]]
创建4*5矩阵
import numpy as np
identity_matrix = np.eye(4, 5,dtype=np.float32)
print(identity_matrix)
输出:
[[1. 0. 0. 0. 0.]
[0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0.]]
np.zeros()
np.zeros() 是 NumPy 库中的一个函数,用于创建一个形状和大小都为零的数组。该函数的主要参数是形状,可以接受的形式有:一个整数,一个元组,或者一个表示形状的数组。
函数解析
函数的详细解释如下:
np.zeros(shape)
shape:一个整数或一个元组,指定要创建的数组的形状。例如,np.zeros(3) 会创建一个长度为3的零向量,np.zeros((2,3)) 会创建一个2行3列的全零矩阵。
函数返回的是一个填充了0的数组。
运行示例
import numpy as np
# 创建一个长度为10的零向量
v = np.zeros(10)
print(v)
# 结果:[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
# 创建一个3行2列的全零矩阵
m = np.zeros((3,2))
print(m)
# 结果:[[0. 0.] [0. 0.] [0. 0.]]
# 创建一个复杂的多维数组
n = np.zeros((2,3,4))
print(n)
# 结果:[[[0. 0. 0.] [0. 0. 0.] [0. 0. 0.]] [[0. 0. 0.] [0. 0. 0.] [0. 0. 0.]]]
输出:
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[[0. 0.]
[0. 0.]
[0. 0.]]
[[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]]
np.ones()
np.ones() 是 NumPy 库中的一个函数,用于创建一个全为1的数组。该函数的主要参数是形状,可以接受的形式有:一个整数,一个元组,或者一个表示形状的数组。
函数解析
与np.zeros()函数类似
np.ones(shape)
shape:一个整数或一个元组,指定要创建的数组的形状。例如,np.ones(3) 会创建一个长度为3的全1向量,np.ones((2,3)) 会创建一个2行3列的全1矩阵。
函数返回的是一个填充了1的数组。
运行示例
import numpy as np
# 创建一个长度为10的全1向量
v = np.ones(10)
print(v)
# 结果:[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
# 创建一个3行2列的全1矩阵
m = np.ones((3,2))
print(m)
# 结果:[[1. 1.] [1. 1.] [1. 1.]]
# 创建一个复杂的多维数组
n = np.ones((2,3,4))
print(n)
# 结果:[[[1. 1. 1.] [1. 1. 1.] [1. 1. 1.]] [[1. 1. 1.] [1. 1. 1.] [1. 1. 1.]]]
输出:
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[[1. 1.]
[1. 1.]
[1. 1.]]
[[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]]
np.concatenate()
np.concatenate() 是 NumPy 库中的一个函数,用于将两个或更多的数组连接在一起。这个函数接受一个元组作为输入,该元组中的每个元素都是一个要连接的数组。
函数解析
np.concatenate((a1, a2, ...), axis=0)
a1, a2, ...:一个或多个要连接的数组。
axis:连接操作沿着哪个轴进行。如果 axis=0,那么数组将会在第一个轴上进行连接,这是默认值。如果 axis=1,那么数组将会在第二个轴上进行连接,以此类推。注意,axis 参数必须是整数。
函数返回一个新的数组,该数组包含所有输入数组在指定轴上的连接。
运行示例
import numpy as np
# 创建两个一维数组
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
#按行拼接
# 在第一个轴(默认)上连接这两个数组
c = np.concatenate((a, b))
print(c)
print("*************")
#按列拼接
# 创建两个二维数组
a2 = np.array([[1, 2], [3, 4]])
b2 = np.array([[5, 6], [7, 8]])
# 按列拼接这两个数组
c2 = np.concatenate((a2, b2), axis=1)
print(c2)
输出:
[1 2 3 4 5 6]
*************
[[1 2 5 6]
[3 4 7 8]]
np.random.beta()
np.random.beta() 是 NumPy 库中的一个函数,用于生成服从 Beta 分布的随机数。Beta 分布是一种连续概率分布,通常用于描述在一定范围内介于两个值之间的随机变量。
函数解析
函数:
np.random.beta(a, b)
a:代表 Alpha 分布的参数,也称作形状参数1。
b:代表 Beta 分布的参数,也称作形状参数2。
返回值:
从 Beta 分布中抽取的随机样本。
运行示例
import numpy as np
import matplotlib.pyplot as plt
# 设置随机种子以确保结果可复现
np.random.seed(0)
# 设置参数 a 和 b
a = 2.0
b = 5.0
# 生成服从 Beta 分布的随机数
samples = np.random.beta(a, b, 1000)
# 使用 matplotlib 绘制 Beta 分布图
plt.hist(samples, bins=30, density=True, alpha=0.6, color='g')
plt.xlabel('Value')
plt.ylabel('Probability Density')
plt.title('Beta Distribution')
plt.show()

在上面的示例中,我们设置了 a=2.0 和 b=5.0 作为 Beta 分布的参数,生成了 1000 个服从该分布的随机数,并使用 Matplotlib 绘制了它们的直方图。
np.maximum()
np.maximum() 是 NumPy 库中的一个函数,用于比较两个或更多个数组元素,并返回每个元素的最大值。
函数解析
函数原型:
np.maximum(x1, x2, *args)
参数:
x1, x2, *args:要进行比较的数值或数组。可以输入任意数量的参数。
返回值:
返回一个相同的形状和类型与输入参数的数组,其中每个元素都是输入参数在该位置上的最大值。
运行示例
import numpy as np
# 对于两个数值
print(np.maximum(3, 4))
# 对于numpy数组
arr1 = np.array([1, 2, 3])
arr2 = np.array([3, 2, 1])
print(np.maximum(arr1, arr2))
输出:
4
[3 2 3]
在上面的示例中,我们看到 np.maximum() 函数可以用于两个数值或两个numpy数组。对于两个数值,它返回较大的那个数值。对于numpy数组,它在每个位置上比较两个数组的元素,并返回一个新数组,其中每个元素都是输入数组在该位置上的最大值。
np.maximum.accumulate()
np.maximum.accumulate 是 NumPy 库中的一个函数,它用于计算输入数组中元素的累积最大值。这个函数接受一个输入数组,然后返回一个累积最大值数组。
函数解析
函数原型为:
numpy.maximum.accumulate(array)
其中 array 是输入的数组。
运行示例
例子1
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
result = np.maximum.accumulate(arr)
print(result)
输出结果:
[1 2 3 4 5]
这个例子中,输入数组 [1, 2, 3, 4, 5] 的累积最大值数组仍然是 [1, 2, 3, 4, 5],因为每个元素本身都是它之前的最大值。
例子2
import numpy as np
arr = np.array([5, 3, 8, 9, 6])
result = np.maximum.accumulate(arr)
print(result)
输出:
[5 5 8 9 9]
np.minimum()
该函数与np.maximum()原理类似,是 NumPy 库中的一个函数,用于比较两个或更多个数组元素,并返回每个元素的最小值。
函数解析
函数原型:
np.minimum(x1, x2, *args)
参数:
x1, x2, *args:要进行比较的数值或数组。可以输入任意数量的参数。
返回值:
返回一个相同的形状和类型与输入参数的数组,其中每个元素都是输入参数在该位置上的最小值。
运行示例
import numpy as np
# 对于两个数值
print(np.minimum(3, 4))
# 对于numpy数组
arr1 = np.array([1, 2, 3])
arr2 = np.array([3, 2, 1])
print(np.minimum(arr1, arr2))
输出:
3
[1 2 1]
在上面的示例中,我们看到 np.minimum() 函数可以用于两个数值或两个numpy数组。对于两个数值,它返回较小的那个数值。对于numpy数组,它在每个位置上比较两个数组的元素,并返回一个新数组,其中每个元素都是输入数组在该位置上的最小值。
np.full()
np.full() 是 NumPy 库中的一个函数,用于创建一个具有指定形状和填充值的数组。
函数解析
函数原型:
np.full(shape, fill_value, dtype=None)
参数:
shape:一个表示数组形状的元组或整数。例如,(3, 4) 表示一个 3 行 4 列的二维数组。
fill_value:要填充在数组中的值。可以是任何 NumPy 数据类型。
dtype:可选参数,表示数组的数据类型。如果未指定,则默认为 None,即根据 fill_value 的类型进行推断。
返回值:
返回一个具有指定形状和填充值的 NumPy 数组。
运行示例
import numpy as np
# 创建一个形状为 (3, 4) 的二维数组,填充值为 0
arr = np.full((3, 4), 0)
print(arr)
# 创建一个形状为 (2, 3) 的二维数组,填充值为 1.5,数据类型为 float
arr = np.full((2, 3), 1.5, dtype=float)
print(arr)
输出:
[[0 0 0 0]
[0 0 0 0]
[0 0 0 0]]
[[1.5 1.5 1.5]
[1.5 1.5 1.5]]
在上面的示例中,我们看到 np.full() 函数可以用于创建一个具有指定形状和填充值的数组。第一个示例中,我们创建了一个形状为 (3, 4) 的二维数组,并将所有元素填充为 0。第二个示例中,我们创建了一个形状为 (2, 3) 的二维数组,并将所有元素填充为 1.5,并指定了数据类型为 float。
np.ascontiguousarray()
np.ascontiguousarray() 是 NumPy 库中的一个函数,用于将输入的数组重新构造为连续的内存块。这个函数在处理需要连续内存的函数(如 np.dot() 或 np.fft.fft2())时非常有用。
函数解析
函数原型:
np.ascontiguousarray(a, dtype=None)
参数:
a:输入数组。可以是任何形状和类型的数组。
dtype:可选参数,表示返回数组的数据类型。如果未指定,则默认为 None,即使用与输入数组相同的类型。
返回值:
返回一个连续的内存块表示的数组,与输入数组 a 具有相同的形状和值。
运行示例
import numpy as np
# 创建一个形状为 (3, 4) 的二维数组,填充值为 0
arr = np.zeros((3, 4))
print("Original array:")
print(arr)
# 使用 np.ascontiguousarray() 重构数组
arr_contiguous = np.ascontiguousarray(arr)
print("Reconstructed array:")
print(arr_contiguous)
输出:
Original array:
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
Reconstructed array:
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
在上面的示例中,我们首先创建了一个形状为 (3, 4) 的二维数组,并将所有元素填充为 0。然后,我们使用 np.ascontiguousarray() 函数将该数组重构为连续的内存块表示。可以看到,返回的数组与原始数组具有相同的形状和值。
np.random.seed()
np.random.seed() 是 NumPy 库中的一个函数,用于设置随机数生成器的种子。种子是一个整数或一个整数序列,用于控制随机数生成器的行为,以确保生成的随机数序列是可重复的。
函数解析
函数原型:
np.random.seed(seed)
参数:
seed:可选参数,用于设置随机数生成器的种子。可以是整数或一个整数序列。如果未指定,则默认为 None,此时随机数生成器会生成一个随机种子。
返回值:
该函数没有返回值。
运行示例
import numpy as np
# 设置随机数生成器的种子为 100
np.random.seed(100)
# 生成一个随机数
random_number = np.random.rand()
print("Random number:", random_number)
# 设置随机数生成器的种子为 None(默认)
np.random.seed()
# 再次生成一个随机数
random_number = np.random.rand()
print("Random number:", random_number)
输出:
Random number: 0.5434049417909654
Random number: 0.7352229465659721
在上面的示例中,我们首先使用 np.random.seed(100) 设置随机数生成器的种子为 100,并生成一个随机数。然后,我们使用 np.random.seed() 将种子重置为默认值(None),并再次生成一个随机数。可以看到,由于种子不同,生成的随机数也不同。因此,通过设置种子,我们可以确保在多次运行程序时得到相同的随机数序列。
np.stack()
np.stack() 是 NumPy 库中的一个函数,用于将一个或多个数组沿着新的维度堆叠在一起。这个函数返回一个新数组,其中包含原始数组中的所有元素,但它们沿着新的维度排列。
函数解析
函数原型:
np.stack(arrays, axis=0)
参数:
arrays:一个或多个数组,这些数组将被堆叠在一起。
axis:可选参数,表示沿着哪个维度进行堆叠。默认为 0,表示在第一个维度(行)上进行堆叠。
返回值:
返回一个新的 NumPy 数组,其中包含原始数组中的所有元素,但它们沿着新的维度排列。
运行示例
import numpy as np
# 创建两个一维数组
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
# 使用 np.stack() 将它们堆叠在一起,得到一个二维数组
c = np.stack((a, b))
print("Stacked array:")
print(c)
#按列堆叠
c1 = np.stack((a, b),axis=1)
print("Stacked array1:")
print(c1)
输出:
Stacked array:
[[1 2 3]
[4 5 6]]
Stacked array1:
[[1 4]
[2 5]
[3 6]]
在上面的示例中,我们创建了两个一维数组 a 和 b,然后使用 np.stack() 将它们堆叠在一起,得到一个二维数组 c。可以看到,c 是一个二维数组,其中包含了 a 和 b 中的所有元素,但它们沿着新的维度排列。
np.unique
np.unique 是 NumPy 库中的一个函数,用于从数组中返回唯一值,并按升序排序。它返回一个包含唯一值的数组,以及一个包含这些唯一值在原数组中首次出现的索引的数组。
函数解析
函数原型:
np.unique(arr, return_index=False, return_inverse=False)
参数:
arr:输入数组,可以是多维数组。
return_index:可选参数,如果为 True,则除了返回唯一值之外,还返回这些唯一值在原数组中首次出现的索引。默认为 False。
return_inverse:可选参数,如果为 True,则除了返回唯一值之外,还返回一个索引数组,该数组可用于将唯一值数组重新构造为原始数组。默认为 False。
返回值:
返回一个包含唯一值的数组,以及可选的索引数组或索引数组的组合(根据参数 return_index 和 return_inverse 的设置)。
运行示例
import numpy as np
# 创建一个一维数组
arr = np.array([2, 5, 1, 2, 4, 3, 5])
# 使用 np.unique() 找到唯一值并按升序排序
unique_values = np.unique(arr)
print("Unique values:", unique_values)
# 使用 np.unique() 找到唯一值并按升序排序,并返回首次出现的索引
unique_values, indices = np.unique(arr, return_index=True)
print("Unique values:", unique_values)
print("Indices:", indices)
# 使用 np.unique() 找到唯一值并按升序排序,并返回一个索引数组,用于重新构造原始数组
unique_values, inverse = np.unique(arr, return_inverse=True)
print("Unique values:", unique_values)
print("Inverse:", inverse)
输出:
Unique values: [1 2 3 4 5]
Unique values: [1 2 3 4 5]
Indices: [2 0 5 4 1]
Unique values: [1 2 3 4 5]
Inverse: [1 4 0 1 3 2 4]
在上面的示例中,我们首先创建了一个包含重复值的一维数组 arr。然后使用 np.unique() 找到 arr 中的唯一值并按升序排序,将结果存储在变量 unique_values 中。接下来,我们使用 return_index=True 和 return_inverse=True 参数来获取更多信息。当 return_index=True 时,函数返回一个包含唯一值及其在原数组中首次出现的索引的元组。当 return_inverse=True 时,函数返回一个索引数组,该数组可用于将唯一值数组重新构造为原始数组(根据原数组中的值在排序中的位置,如原数组中第一个值2,在排序中是在第二个位置,则最后生成的索引则为1,即得到的新数组第一个值为1)。
np.zeros_like
np.zeros_like 是一个 NumPy 函数,它创建一个与给定数组形状相同、元素值全为零的新数组。这个函数对于快速复制形状并填充零非常有用。
函数解析
函数原型:
np.zeros_like(a, dtype=None, order='K', subok=False)
参数解释:
a: 输入数组。函数将创建与这个数组形状相同的新数组。
dtype: 数据类型,可选参数。如果未指定,则默认为 None,这意味着新数组的数据类型将与输入数组相同。
order: 排序方式,可选参数。如果为 'K',则按照输入数组的内存顺序创建新数组。如果为 'C',则使用行优先方式创建数组。默认值为 'K'。
subok: 如果为 True,则允许创建子类的实例。默认值为 False。
返回值:
返回一个新数组,其形状与输入数组相同,所有元素值都为零。
运行示例
import numpy as np
# 创建一个形状为 (3, 3) 的随机数组
a = np.random.rand(3, 3)
print("Original array:", a)
# 创建一个与 a 形状相同、元素值全为零的新数组
b = np.zeros_like(a)
print("Zero array:", b)
输出:
Original array:
[[0.03055982 0.10393955 0.52521327]
[0.24149545 0.23694233 0.41798272]
[0.72414372 0.26958905 0.2894202 ]]
Zero array:
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
这段代码将首先创建一个形状为 (3, 3) 的随机数组 a,然后使用 np.zeros_like 函数创建一个与 a 形状相同、元素值全为零的新数组 b。
np.save ()
np.save() 是 NumPy 库中的一个函数,用于将数组保存到 .npy 文件中。这种文件格式可以用于在之后重新加载数组。
函数解析
函数原型:
numpy.save(file, arr, allow_pickle=True, fix_imports=True, do_compression=False)
参数:
file:要保存到的 .npy 文件的路径。
arr:要保存的数组。
allow_pickle:布尔值,决定是否允许 pickling 数据。默认为 True。
fix_imports:布尔值,决定是否应该尝试修复不兼容的导入。默认为 True。
do_compression:布尔值,决定是否应该对文件进行压缩。默认为 False。
运行示例
import numpy as np
# 创建一个数组
arr = np.array([[1, 2], [3, 4]])
# 将数组保存到 .npy 文件
np.save('my_array.npy', arr)
同级别文件夹中生成了一个“my_array.npy”文件,内容为:
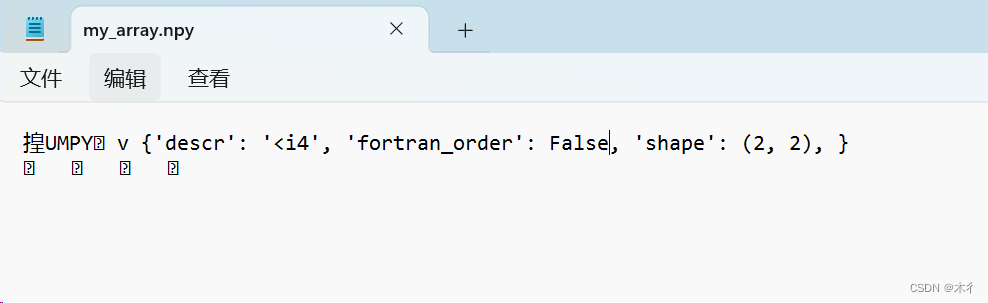
用记事本打开有些乱码。
np.load ()
np.load 是 NumPy 库中的一个函数,用于从 .npy 文件中加载数组。这种文件是由 np.save 函数创建的。np.load 函数非常适合用于恢复之前保存的数组,以便可以在之后的代码中使用。
函数解析
函数原型:
numpy.load(file, mmap_mode=None, allow_pickle=True, fix_imports=True, encoding='ASCII')
参数:
file:要加载的 .npy 文件的路径。
mmap_mode:可选参数,用于指定内存映射模式的文件加载。默认值是 None。
allow_pickle:布尔值,决定是否允许加载 pickle 数据。默认为 True。
fix_imports:布尔值,决定是否应该尝试修复不兼容的导入。默认为 True。
encoding:字符串,用于指定编码方式。默认为 'ASCII'。
运行示例
import numpy as np
# 创建一个数组
arr = np.array([[1, 2], [3, 4]])
# 将数组保存到 .npy 文件
np.save('my_array.npy', arr)
# 加载 .npy 文件
loaded_arr = np.load('my_array.npy')
# 打印加载的数组
print(loaded_arr)
输出:
[[1 2]
[3 4]]
np.floor()
np.floor() 是 NumPy 库中的一个函数,用于对输入的数字或数组进行向下取整。具体来说,np.floor(x) 会返回不大于 x 的最大整数。如果 x 是一个数组,那么 np.floor(x) 会返回一个新的数组,其中每个元素都是 x 中相应元素的最大整数。
函数解析
函数原型为:
numpy.floor(x)
其中 x 是输入的数字或数组。
运行示例
import numpy as np
# 对单个数字进行向下取整
print(np.floor(3.14))
print("**********")
print(np.floor(3))
print("**********")
# 对数组进行向下取整
print(np.floor([3.14, 2.71, 1.41]))
print("**********")
print(np.floor([[3.14, 2.71], [1.41, 1.69]]))
输出:
3.0
**********
3.0
**********
[3. 2. 1.]
**********
[[3. 2.]
[1. 1.]]
np.ceil()
np.ceil() 是 NumPy 库中的一个函数,用于对输入的数字或数组进行向上取整。具体来说,np.ceil(x) 会返回大于等于 x 的最小整数。如果 x 是一个数组,那么 np.ceil(x) 会返回一个新的数组,其中每个元素都是 x 中相应元素的最小整数。
函数解析
函数原型为:
numpy.ceil(x)
其中 x 是输入的数字或数组。
运行示例
import numpy as np
# 对单个数字进行向上取整
print(np.ceil(3.14))
print("**********")
print(np.ceil(3))
print("**********")
# 对数组进行向上取整
print(np.ceil([3.14, 2.71, 1.41]))
print("**********")
print(np.ceil([[3.14, 2.71], [1.41, 1.69]]))
输出:
4.0
**********
3.0
**********
[4. 3. 2.]
**********
[[4. 3.]
[2. 2.]]
np.flipud()
np.flipud() 是 NumPy 库中的一个函数,用于沿着垂直轴翻转数组。具体来说,np.flipud(a) 会返回一个新数组,其中原数组 a 的每一行都被翻转。
函数解析
函数原型为:
numpy.flipud(a)
其中 a 是输入的数组。
运行示例
import numpy as np
# 创建一个 3x3 的二维数组
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print("Original array:")
print(a)
# 使用 np.flipud() 翻转数组
b = np.flipud(a)
print("Flipped array:")
print(b)
输出:
Original array:
[[1 2 3]
[4 5 6]
[7 8 9]]
Flipped array:
[[7 8 9]
[4 5 6]
[1 2 3]]
np.fliplr()
np.fliplr() 是 NumPy 库中的一个函数,用于沿着水平轴翻转数组。具体来说,np.fliplr(a) 会返回一个新数组,其中原数组 a 的每一列都被翻转。
函数解析
函数原型为:
numpy.fliplr(a)
其中 a 是输入的数组。
运行示例
import numpy as np
# 创建一个 3x3 的二维数组
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print("Original array:")
print(a)
# 使用 np.fliplr() 翻转数组
b = np.fliplr(a)
print("Flipped array:")
print(b)
输出结果:
Original array:
[[1 2 3]
[4 5 6]
[7 8 9]]
Flipped array:
[[3 2 1]
[6 5 4]
[9 8 7]]
np.hstack()
np.hstack() 是 NumPy 库中的一个函数,用于将两个或更多的数组沿着水平轴(即列)连接起来。这个函数会沿着水平轴(即列)将输入的数组堆叠起来。这意味着输出的数组的列数将是输入数组的列数之和,而行数将是输入数组中最大行数的值。
函数解析
函数原型为:
numpy.hstack(tup)
其中 tup 是一个元组,包含了你想要堆叠的数组。
运行示例
一维数组
import numpy as np
# 创建两个一维数组
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
# 使用 np.hstack() 将它们堆叠起来
c = np.hstack((a, b))
print(c)
输出:
[1 2 3 4 5 6]
二维数组
import numpy as np
# 创建两个二维数组
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
# 使用 np.hstack() 将它们堆叠起来
c = np.hstack((a, b))
print(c)
输出:
[[1 2 5 6]
[3 4 7 8]]
np.vstack()
在NumPy中,用于按行堆叠(即在水平方向上堆叠)的函数是np.vstack()。这个函数将两个或更多的数组沿着垂直轴(即行)堆叠起来。
函数解析
数原型为:
numpy.vstack(tup)
其中tup是一个元组,包含了你想要堆叠的数组。
运行示例
import numpy as np
# 创建两个二维数组
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
# 使用 np.vstack() 将它们堆叠起来
c = np.vstack((a, b))
print("按行堆叠:")
print(c)
输出:
按行堆叠:
[[1 2]
[3 4]
[5 6]
[7 8]]
np.bincount()
np.bincount()函数是NumPy库中的一个函数,用于统计数组中每个元素出现的次数。
函数解析
函数原型为:
numpy.bincount(x[, minlength])
参数:
x:一个数组,其中包含要统计的元素。
minlength:可选参数,指定返回结果的长度。如果指定了此参数,那么当x的长度小于minlength时,将会用0补充结果。
返回值:
这个函数会返回一个长度与x中不同元素个数相同的数组,其中每个元素表示相应元素在x中出现的次数。
运行示例
import numpy as np
# 创建一个一维数组
arr = np.array([0, 1, 1, 2, 3, 3, 3, 2])
# 使用 np.bincount() 统计每个元素出现的次数
counts = np.bincount(arr)
print("元素出现的次数:")
print(counts)
输出:
元素出现的次数:
[1 2 2 3]
np.argmax()
np.argmax() 是 NumPy 库中的一个函数,它返回输入数组中最大值的索引。这是一个非常实用的函数,特别是在处理多维数组时。
函数解析
函数原型为:
numpy.argmax(a, axis=None)
参数:
a:输入的数组。
axis:可选参数,表示沿着哪个轴进行操作。如果 axis 为 None,则函数会返回输入数组中最大值的索引。如果指定了 axis,则函数会返回该轴上最大值的索引。例如,如果 axis 等于 1,函数会返回每一行中最大值的索引。
运行示例
一维数组
import numpy as np
# 创建一个一维数组
arr = np.array([1, 3, 5, 2, 4])
# 使用 np.argmax() 找到最大值的索引
max_index = np.argmax(arr)
print("最大值的索引:", max_index)
输出:
最大值的索引: 2
二维数组(默认行为)
import numpy as np
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 使用 np.argmax() 找到最大值的索引(默认行为是沿着最后一维)
max_index = np.argmax(arr)
print("最大值的索引:", max_index)
输出:
最大值的索引: 8
二维数组(指定轴)
0是列,1是行
import numpy as np
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6], [2, 8, 9]])
# 使用 np.argmax() 沿着第一维找到最大值的索引(axis=0)
max_index_axis0 = np.argmax(arr, axis=0)
print("沿着第一维最大值的索引:", max_index_axis0)
# 使用 np.argmax() 沿着第二维找到最大值的索引(axis=1)
max_index_axis1 = np.argmax(arr, axis=1)
print("沿着第二维最大值的索引:", max_index_axis1)
输出:
沿着第一维最大值的索引: [1 2 2]
沿着第二维最大值的索引: [2 2 2]
np.argmin()
np.argmin() 是 NumPy 库中的一个函数,它返回输入数组中最小元素的索引。该函数的行为会根据输入数组的维度而变化。
函数解析
运行示例
一维数组
import numpy as np
# 创建一个一维数组
arr = np.array([1, 3, 5, 2, 4])
# 使用 np.argmin() 找到最小值的索引
min_index = np.argmin(arr1)
print("最大值的索引:", max_index)
输出:
最小值的索引: 0
二维数组(默认行为)
import numpy as np
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 使用 np.argmin() 找到最小值的索引(默认行为是沿着最后一维)
min_index = np.argmin(arr)
print("最小值的索引:", min_index)
输出:
最大值的索引: 0
二维数组(指定轴)
0是列,1是行
import numpy as np
# 创建一个二维数组
arr2 = np.array([[3, 2, 1], [1, 5, 6], [7, 8, 9]])
# 使用 np.argmin() 沿着第一维找到最小值的索引(axis=0)
min_index_axis0 = np.argmin(arr2, axis=0)
print("沿着第一维最小值的索引:", min_index_axis0)
# 使用 np.argmin() 沿着第二维找到最小值的索引(axis=1)
min_index_axis1 = np.argmin(arr2, axis=1)
print("沿着第二维最小值的索引:", min_index_axis1)
输出:
沿着第一维最小值的索引: [1 0 0]
沿着第二维最小值的索引: [2 0 0]
np.argsort()
np.argsort() 是 NumPy 库中的一个函数,它返回输入数组中元素的排序索引。这个函数非常有用,特别是在需要排序数组并获取排序索引时。
函数解析
函数原型为:
numpy.argsort(a, kind='quicksort', axis=-1, order=None)
参数:
a:输入的数组。
kind:排序算法的类型。可以是 'quicksort'、'heapsort'、'stable' 等。默认是 'quicksort'。
axis:沿着哪个轴进行排序。默认是 -1,表示在最后一个轴上排序。
order:排序的顺序。可以是 'ascending'(升序)或 'descending'(降序)。
这个函数返回一个整数数组,表示输入数组中每个元素在排序后数组中的索引位置。这个数组可以用于重新构造排序后的数组,或者用于其他需要排序索引的操作。默认是升序
运行示例
一维数组排序索引
import numpy as np
# 创建一个一维数组
arr = np.array([3, 1, 2])
# 使用 np.argsort() 获取排序索引
sort_index = np.argsort(arr)
print("排序索引:", sort_index)
输出:
排序索引: [1 2 0]
二维数组排序索引
import numpy as np
# 创建一个二维数组
arr = np.array([[3, 1, 2], [5, 4, 7], [6, 8, 9]])
# 使用 np.argsort() 沿着最后一维获取排序索引
sort_index = np.argsort(arr, axis=-1)
print("排序索引:", sort_index)
输出:
排序索引: [[1 2 0]
[1 0 2]
[0 1 2]]
使用排序索引重新构造数组
import numpy as np
# 创建一个二维数组
arr = np.array([[3, 1, 2], [5, 4, 7], [6, 8, 9]])
# 使用 np.argsort() 沿着最后一维获取排序索引
sort_index = np.argsort(arr, axis=-1)
print("重新构造的数组:", sort_index )
# 使用排序索引重新构造数组
sorted_arr = arr[np.argsort(sort_index)]
print("重新构造的数组:", sorted_arr)
输出:
重新构造的数组: [[1 2 0]
[1 0 2]
[0 1 2]]
重新构造的数组: [[[6 8 9]
[3 1 2]
[5 4 7]]
[[5 4 7]
[3 1 2]
[6 8 9]]
[[3 1 2]
[5 4 7]
[6 8 9]]]
np.set_printoptions()
np.set_printoptions 是 NumPy 库中的一个函数,它用于设置打印数组时的默认选项。这可以帮助你控制 NumPy 打印输出的格式和精度。
函数解析
函数原型:
numpy.set_printoptions(precision, threshold, edgeitems, linewidth, max_line_width)
参数:
precision:控制浮点数的精度,即小数点后的位数。默认值是 None,表示使用默认精度。
threshold:控制数组元素的总数,当元素数量大于该阈值时,会使用省略号表示。默认值是 None,表示不使用省略号。
edgeitems:控制数组边缘的元素数量,当数组边缘的元素数量小于该值时,会在边缘添加省略号。默认值是 3。
linewidth:控制每行的最大字符数,超过该值的元素会被分割到下一行。默认值是 75。
max_line_width:控制每行的最大行数,超过该值的元素会被分割到多行。默认值是 None,表示不进行分割。
返回值:
该函数没有返回值。
运行示例
设置浮点数的精度
import numpy as np
np.set_printoptions(precision=4)
print(np.array([1.23456789]))
输出:
[1.2346]
设置数组元素的阈值
当元素个数大于10时,使用省略号。
import numpy as np
#控制元素个数
np.set_printoptions(threshold=10)
print(np.arange(20))
[ 0 1 2 ... 17 18 19]
设置每行的最大字符数
最大字符数设置为10
import numpy as np
np.set_printoptions(linewidth=10)
print(np.array([1, 2, 3, 4, 5]))
输出:
[1 2 3 4
5]
np.loadtxt()
np.loadtxt 是 NumPy 库中的一个函数,用于从文本文件中加载数据并返回一个 NumPy 数组。
函数解析
函数原型:
numpy.loadtxt(filename, dtype=float, delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0)
参数:
filename:要加载数据的文件名,可以是字符串类型。
dtype:返回的数组的数据类型,默认为浮点型(float)。也可以传入其他 NumPy 数据类型,如 int、str 等。
delimiter:指定分隔符,用于将文本文件中的数据拆分为不同列。默认为 None,表示根据输入文件的数据类型进行自动推断。常见的分隔符包括逗号(',')、制表符('\t')等。
converters:一个字典,用于指定某些列数据的转换函数。字典的键为列索引,值为转换函数。例如,设置 converters={0: lambda x: int(x)} 将第一列数据转换为整数类型。
skiprows:要跳过的行数,用于忽略文件开头的注释或无关数据。默认为 0,表示不跳过任何行。
usecols:一个切片对象,用于指定要加载的列范围。例如,设置 usecols=(0, 2, 4) 将只加载第一、第三和第五列数据。
unpack:布尔值,用于指示是否将返回的数组解包为单独的变量。默认为 False,表示不解包。
ndmin:指定返回的数组的维度最小值。默认为 0,表示根据数据自动推断数组维度。
data.csv文件内容为:
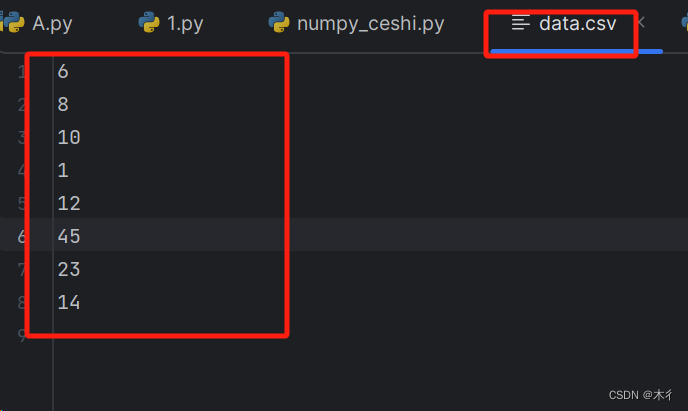
运行示例
用.号分隔数据的文本文件
import numpy as np
data = np.loadtxt('data.csv', delimiter='.')
print(data)
输出:
[ 6. 8. 10. 1. 12. 45. 23. 14.]
加载包含注释的文本文件,并跳过前三行
import numpy as np
data = np.loadtxt('data.csv', skiprows=3)
print(data)
输出:
[ 1. 12. 45. 23. 14.]
np.linspace()
np.linspace 是 NumPy 库中的一个函数,用于在指定的间隔内生成等间距的数值序列。它返回一个 NumPy 数组,其中包含指定数量的数字,这些数字沿着标准数轴均匀分布。
函数解析
函数原型:
np.linspace(start, stop, num, endpoint=True, retstep=False, dtype=None)
参数说明:
start:序列的起始值。默认值为 0。
stop:序列的终止值。这是唯一必需的参数。
num:生成的数字序列中元素的数量。默认值为 50。
endpoint:如果为 True,stop 值将被包含在结果中。默认值为 True。
retstep:如果为 True,返回 (num, start, stop, endpoint) 的元组。默认值为 False。
运行示例
import numpy as np
arr = np.linspace(0, 1, 10)
print(arr)
arr1 = np.linspace(0, 1, 10, endpoint=True)
print(arr1)
arr2 = np.linspace(2, 10, num=5, endpoint=True)
print(arr2)
输出:
[0. 0.11111111 0.22222222 0.33333333 0.44444444 0.55555556
0.66666667 0.77777778 0.88888889 1. ]
[0. 0.11111111 0.22222222 0.33333333 0.44444444 0.55555556
0.66666667 0.77777778 0.88888889 1. ]
[ 2. 4. 6. 8. 10.]
np.copy()
np.copy 是 NumPy 库中的一个函数,用于创建指定数组的副本。这个函数返回的是输入数组的一个拷贝,而不是对原始数组的引用。这意味着对返回的拷贝进行的任何更改不会影响到原始数组。
函数解析
函数原型:
numpy.copy(arr)
参数:
arr:要复制的数组。
返回值:
返回输入数组的副本。返回的数组是原始数组的一个全新副本,对它的更改不会影响原始数组。
运行示例
import numpy as np
# 创建一个数组
arr = np.array([1, 2, 3, 4, 5])
print("原始数组:")
print(arr)
# 使用 np.copy 复制数组
arr_copy = np.copy(arr)
print("复制的数组:")
print(arr_copy)
# 修改复制的数组
arr_copy[0] = 100
print("修改后的复制数组:")
print(arr_copy)
# 原始数组未受影响
print("原始数组:")
print(arr)
输出:
原始数组:
[1 2 3 4 5]
复制的数组:
[1 2 3 4 5]
修改后的复制数组:
[100 2 3 4 5]
原始数组:
[1 2 3 4 5]
np.interp()
np.interp 是 NumPy 库中的一个函数,用于执行一维线性插值。它可以在已知的数据点之间进行插值,生成新的数据点。
函数解析
函数原型:
numpy.interp(x, xp, fp)
参数:
x:要进行插值的数据点,可以是一个一维数组或一个单独的数值。
xp:已知的数据点,是一个一维数组,表示 x 的值。
fp:已知的数据点的函数值,是一个一维数组,与 xp 具有相同的长度,表示对应于每个 x 的函数值。
返回值:
返回插值后得到的新数据点的函数值。
np.interp通过获取xp与fp之间的对应线性函数关系,估计x处的对应值来进行线性插值。
运行示例
import numpy as np
# 已知数据点
x = np.array([1, 2, 3, 4, 5])
y = np.array([2, 3, 5, 7, 11])
# 进行插值,得到新的数据点对应的函数值
x_new = np.array([1.5, 2.5, 3.5])
y_new = np.interp(x_new, x, y)
print(y_new) # 输出 [2.5 4. 6. ]
输出:
[2.5 4. 6. ]
np.ndarray()
np.ndarray 是 NumPy 库中的一个类,用于创建和操作多维数组对象。np.ndarray 可以包含不同类型的数据,例如整数、浮点数、字符串等。
函数解析
class numpy.ndarray:
def __init__(self, shape, dtype=float, buffer=None, offset=0, strides=None, order=None):
# 构造函数,用于创建 ndarray 对象
self.shape = shape # 数组的形状
self.dtype = dtype # 数组的数据类型
self.buffer = buffer # 数组数据的内存块
self.offset = offset # 数组数据在内存块中的偏移量
self.strides = strides # 数组每个维度在内存中的跨度
self.order = order # 数组数据的存储方式(默认值:None)
常用参数:
shape:返回数组的形状。例如:arr.shape = (3,4) 表示数组是一个 3 行 4 列的二维数组。
dtype:返回数组的数据类型。例如:arr.dtype = int 表示数组中的元素都是整数类型。
运行示例
import numpy as np
# 创建一个 2x3x4 的三维数组
data = np.ndarray((2, 3, 4), dtype=int)
# 为数组元素赋值
for i in range(data.shape[0]):
for j in range(data.shape[1]):
for k in range(data.shape[2]):
data[i, j, k] = i + j + k
print("三维数组:")
print(data)
输出:
[[[0 1 2 3]
[1 2 3 4]
[2 3 4 5]]
[[1 2 3 4]
[2 3 4 5]
[3 4 5 6]]]
np.fromfile()
np.fromfile() 是 NumPy 库中的一个函数,它从一个二进制文件中读取数据并返回一个数组。这个函数特别适合处理大型数据集,因为它可以直接从文件中读取数据,而不需要将整个文件加载到内存中。
函数解析
函数原型:
函数原型:
numpy.fromfile(file, dtype=float, count=-1, sep='')
参数解释:
file:需要读取的二进制文件。
dtype:期望的数据类型。例如,np.int32、np.float64 等。默认值是 float。
count:要读取的元素数量。如果设置为 -1,将读取所有剩余的元素。默认值是 -1。
sep:元素之间的分隔符。在 NumPy 中,默认分隔符是 None,表示根据数据类型确定分隔符。
运行示例
import numpy as np
# 创建一个包含数据的二进制文件
data = np.array([1, 2, 3, 4, 5], dtype=np.int32).tofile('data.bin')
# 从文件中读取数据并存储为 NumPy 数组
arr = np.fromfile('data.bin', dtype=np.int32)
print(arr)
arr1 = np.fromfile('data.bin', dtype=np.int32, count=3)
print(arr1)
输出:
[1 2 3 4 5]
[1 2 3]
np.convolve()
np.convolve 是 NumPy 库中的一个函数,用于执行卷积运算。卷积是一种在信号处理、图像处理和机器学习等领域广泛应用的运算。
函数解析
函数原型:
numpy.convolve(in1, in2, mode='full', axis=-1)
参数:
in1:第一个输入数组。
in2:第二个输入数组。
mode:卷积的模式,有四种模式可选:'full'、'valid'、'same'、'linear'。默认为 'full'。
'full':输出是完整的重叠区域。
'valid':输出仅包含完全重叠的点。
'same':输出是输入的长度相同的中央部分。
'linear':使用线性滤波器,输出是输入的长度相同的中央部分,但边缘效应被线性滤波器处理。
axis:进行卷积操作的轴。默认为 -1,表示在最后一个轴上操作。
运行示例
卷积运算
import numpy as np
vector1 = np.array([1, 2, 3])
vector2 = np.array([4, 5, 6])
convolution = np.convolve(vector1, vector2, mode='full')
print(convolution)
输出:
[ 4 13 28 27 18]
np.trapz()
np.trapz 是 NumPy 库中的一个函数,用于计算梯形积分。这个函数在数值积分中非常有用,特别是在那些不能轻易找到解析解的问题中。
梯形法是一种数值积分方法,其基本思想是在被积函数曲线的下方“画梯形”,然后用梯形的面积近似代替所求的积分。
函数解析
可以这样形象地理解 np.trapz:想象你在平面上铺设了多个“梯形”小块(由函数在特定点的取值决定),这些梯形的宽度都是 dx ,高度就是函数的取值。然后,把这些梯形的面积加起来,就得到了这个函数在该区间上的积分值。
函数原型:
numpy.trapz(x, y=None, dx=1.0)
参数说明:
x:一维的数组或者列表,作为积分的下限。
y:一维的数组或者列表,作为积分的上限。如果未提供,默认为 None,此时函数会返回从 x[0] 到 x[-1] 的积分。
dx:间距的长度,如果 x 是等间隔的,那么 dx 应该被设定为 1.0。默认值为 1.0。
返回值:
返回一个浮点数,表示所求的梯形积分值。
运行示例
import numpy as np
x = np.linspace(0, 3, 100) # 创建一个等间隔的数组,作为积分的下限和上限
y = x**2 # 定义函数 f(x) = x^2 在每个点的取值
integral = np.trapz(y, x) # 计算积分
print(f"The integral of f(x) = x^2 from 0 to 3 is: {integral}") # 输出积分的结果
输出:
The integral of f(x) = x^2 from 0 to 3 is: 9.000459136822775
上述示例中,我们使用了 np.linspace(0, 3, 100) 来生成等间隔的数组 x,这只是为了方便我们手动构造一个具体的函数。在实际应用中,你可能会直接使用函数在其他点的取值作为 y。
np.where()
np.where() 是一个非常有用的函数,它返回输入数组中满足给定条件的元素的索引。这个函数在很多情况下都非常有用,比如在数据分析和处理中进行条件判断。
函数解析
函数原型:
numpy.where(condition[, x, y])
参数说明:
condition:当只使用一个条件时,它是一个用于测试每个元素的布尔(真/假)数组。当使用两个条件时,它是一个(n,2)数组,每行包含一个布尔测试。
x, y:当只使用一个条件时,x 和 y 是用于替换满足和不满足条件的元素的数组。当使用两个条件时,x 和 y 是用于替换每行的元素的数组。
返回值:
当只使用一个条件时,返回一个包含满足条件的元素的数组。当使用两个条件时,返回一个包含替换每行元素的数组。
运行示例
单条件
import numpy as np
# 创建一个随机数组
arr = np.random.randint(0, 10, size=(5,))
print("Original array:", arr)
# 使用np.where()找出所有大于5的元素,并用9替换它们
new_arr = np.where(arr > 5, 9, arr)
print("New array with replaced values:", new_arr)
输出:
Original array: [2 2 6 1 9]
New array with replaced values: [2 2 9 1 9]
多条件
import numpy as np
# 创建一个随机数组
arr = np.random.randint(0, 10, size=(5,2))
print("Original array:", arr)
# 使用np.where()找出第一列大于5的元素,并用9替换它们;同时找出第二列小于6的元素,并用11替换它们
new_arr = np.where(np.c_[arr[:,0] > 5, arr[:,1] < 6], [9, 11], arr)
print("New array with replaced values:", new_arr)
输出:
Original array: [[8 3]
[3 6]
[3 1]
[5 0]
[2 3]]
New array with replaced values: [[ 9 11]
[ 3 6]
[ 3 11]
[ 5 11]
[ 2 11]]
np.sum()
np.sum() 是 NumPy 库中的一个函数,用于计算数组中元素的总和。它接受一个或多个数组作为输入,并返回这些数组元素的和。
函数解析
函数原型:
numpy.sum(array, axis=None, dtype=None, out=None, keepdims=False, initial=0, where=True)
参数说明:
array:输入的数组。可以是标量(在调用 np.sum() 时将计算其和),也可以是 NumPy 数组。
axis:可选参数,表示沿哪个轴进行求和。默认值是 None,表示对整个数组进行求和。如果输入的是一个标量,则该参数无效。
dtype:可选参数,表示返回的数组的数据类型。默认值是 None,表示使用与输入数组相同的数据类型。
out:可选参数,表示输出的数组。如果提供了一个 out 参数,则求和操作将在这个数组中进行,而不是创建一个新的数组。
keepdims:可选参数,表示是否保持被求和的维度。如果为 True,则返回的数组将保留被求和的维度,这些维度的长度为 1。
initial:可选参数,表示在求和操作中添加到每个元素之前的初始值。默认值是 0。
where:可选参数,表示一个布尔掩码,决定哪些元素应该被包括在求和操作中。默认值是 True,表示对所有元素进行求和。
返回值:
返回一个 NumPy 数组,其中包含输入数组的元素的和。如果 axis 参数为 None,则返回一个标量。
运行示例
import numpy as np
#对一个 NumPy 数组进行求和:
arr = np.array([1, 2, 3, 4, 5])
result = np.sum(arr)
print(result)
#对多个 NumPy 数组进行求和:
import numpy as np
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
result1 = np.sum([arr1, arr2])
print(result1)
#沿着某个轴进行求和:
import numpy as np
arr3 = np.array([[1, 2], [3, 4]])
result3 = np.sum(arr3, axis=0)
print(result3)
输出:
15
21
[4 6]
np.nan()
函数解析
np.nan 是 NumPy 库中的一个特殊值,表示“非数字”(Not a Number)。它是 NaN 的缩写,是一个IEEE标准,用于表示结果无法定义或无法表示的数学运算。
使用方法:
创建 NaN 值的常用方法就是调用 np.nan 函数。
运行示例
import numpy as np
# 使用 np.nan 创建 NaN 数组
nan_array = np.array([1, 2, np.nan, 4])
print(nan_array)
输出:
[ 1. 2. nan 4.]
np.log()
np.log() 是 NumPy 库中的一个函数,用于计算自然对数(以 e 为底)。
函数解析
函数原型:
numpy.log(x)
参数说明:
x:一个数值或 NumPy 数组,表示要计算其自然对数的值。
返回值:
返回输入值的自然对数。
运行示例
import numpy as np
# 计算数字 10 的自然对数
result = np.log(10)
print(result)
array = np.array([-1, 10, 100, 1000])
# 计算这个数组中每个数字的自然对数
result1 = np.log(array)
print(result1)
输出:
2.302585092994046
[ nan 2.30258509 4.60517019 6.90775528]
C:\Users\SW\Desktop\suishoulian\csdn\numpy_ceshi.py:776: RuntimeWarning: invalid value encountered in log
result1 = np.log(array)
在这个示例中,如果输入数组中的值是负数或零,那么返回的将是 NaN(因为负数和零的自然对数是未定义的)。
np.linalg.lstsq()
np.linalg.lstsq() 是 NumPy 库中的一个函数,用于执行最小二乘法拟合线性方程组。它可以找到一个向量 b,使得对于给定的矩阵 A,np.dot(A, b) 尽可能接近 y。
函数解析
函数原型:
numpy.linalg.lstsq(A, y, rcond=None, overwrite_A=False, overwrite_b=False, check_finite=True, det_A=None, normed=True)
参数说明:
A:一个 n×m 的矩阵,其中 n 是线性方程组的未知数的数量,m 是方程的数量。
y:一个 n×1 的向量,表示等式右边的值。
rcond:一个可选参数,用于指定奇异值阈值。如果指定了该参数,那么当使用奇异值分解时,奇异值小于 rcond * sigma_max 的值将被截断为零,其中 sigma_max 是最大的奇异值。
overwrite_A:一个布尔值,表示是否覆盖输入的矩阵 A。
overwrite_b:一个布尔值,表示是否覆盖输入的向量 y。
check_finite:一个布尔值,表示是否检查矩阵 A 和向量 y 中的元素是否为有限值。
det_A:一个可选参数,表示矩阵 A 的行列式值的估计。
normed:一个布尔值,表示是否对解向量 b 进行归一化。
返回值:
返回一个元组 (x, residuals, rank, s = singular_values, rcond),其中:
x:一个 m×1 的向量,表示最小二乘解。
residuals:一个 1-D 数组,表示残差平方和。
rank:矩阵 A 的秩。
s:一个 1-D 数组,表示 A 的奇异值。
rcond:如果指定了该参数,那么就是使用的奇异值的倒数阈值;否则为 None。
运行示例
import numpy as np
# 定义一个矩阵 A 和一个向量 y
A = np.array([[3, 2], [1, 7]])
y = np.array([9, 1])
# 使用 np.linalg.lstsq() 求解最小二乘解
x, residuals, rank, s = np.linalg.lstsq(A, y)
# 输出结果
print("最小二乘解:", x)
输出:
最小二乘解: [ 3.21052632 -0.31578947]
这个示例中,我们有一个 2×2 的矩阵 A 和一个 2×1 的向量 y。我们使用 np.linalg.lstsq() 函数来找到一个向量 x,使得 np.dot(A, x) 最接近 y。输出结果将显示找到的最小二乘解
np.empty()
np.empty() 是 NumPy 库中的一个函数,用于创建一个指定形状和数据类型的空数组。这个函数不初始化数组元素,因此返回的数组中元素的值是不确定的。
函数解析
函数原型:
numpy.empty(shape, dtype=float, order='C')
参数说明:
shape:一个表示数组形状的元组。例如,(3, 4) 表示一个 3 行 4 列的二维数组。
dtype:一个可选参数,表示创建的数组的数据类型。默认值是 float。其他常用的数据类型包括 int、str 等。
order:一个可选参数,表示数组在内存中的存储方式。默认值是 'C',表示按行优先存储(类似于 C 语言中的数组)。如果指定为 'F',则表示按列优先存储(类似于 Fortran 语言中的数组)。
返回值:
np.empty() 返回一个新的数组对象,该对象是一个指定形状和数据类型的空数组。返回的数组中的元素值不确定,因此需要在使用之前进行初始化。
运行示例
import numpy as np
# 创建一个形状为 (3, 4) 的空数组,数据类型为 float
empty_array = np.empty((3, 4), dtype=float)
print(empty_array)
输出:
[[6.23042070e-307 7.56587584e-307 1.37961302e-306 6.23053614e-307]
[1.69121639e-306 1.05701279e-307 1.60220393e-306 6.23037996e-307]
[6.23053954e-307 9.34603679e-307 2.22522596e-306 2.56765117e-312]]
结束语
因搜集来源有限,写的可能不全,欢迎大家评论补充,后期不定时更新。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!