图像融合论文阅读:MURF: Mutually Reinforcing Multi-Modal Image Registration and Fusion
@article{xu2023murf,
title={MURF: Mutually Reinforcing Multi-modal Image Registration and Fusion},
author={Xu, Han and Yuan, Jiteng and Ma, Jiayi},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2023},
publisher={IEEE}
}
论文级别:SCI A1
影响因子:23.6
文章目录
🌻【如侵权请私信我删除】
📖论文解读
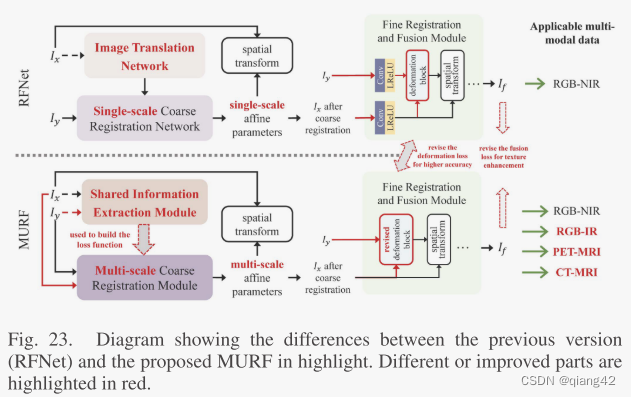
马佳义大佬团队2023年的一篇论文。该论文之前的版本是RFNet。下图为两个版本的区别和改进
MURF主要利用三个模块:
- SIEM 共享特征提取(shared information extraction module)
捕获跨多个模式共享的信息。它有助于将多模态配准问题转化为公共空间中的单模态配准问题。然后在配准模块中使用提取函数。
- MCRM 多尺度粗配准(multi-scale coarse registration module)
进行全局校正。利用SIEM提取的表示建立配准约束,并将其用于MCRM网络的训练。MCRM输出粗配准后的图像 I x R I_x^R IxR?。
- F2M 精准配准和融合(fine registration and fusion module)
将 I x R I_x^R IxR?和 I y I_y Iy?作为输入,得到最终的融合图像 I f I_f If?
🔑关键词
Multi-modal images, image registration, image fusion, contrastive learning.
多模态图像,图像配准,图像融合,对比学习
💭核心思想
如下图所示,以往的方法是将配准和融合分开,作者提出的新方法是将两者结合并相互促进。
图像配准采用由粗到细的方法进行处理。对于粗配准,SIEM首先将多模态图像转化为单模态信息,以消除模态间差异。在此基础上,MCRM通过多尺度仿射变换对全局刚性视差进行逐步校正。在单个模块中实现精细配准和融合,进一步提高了配准精度和融合性能。图像融合时在保留源信息的同时进行了纹理增强。
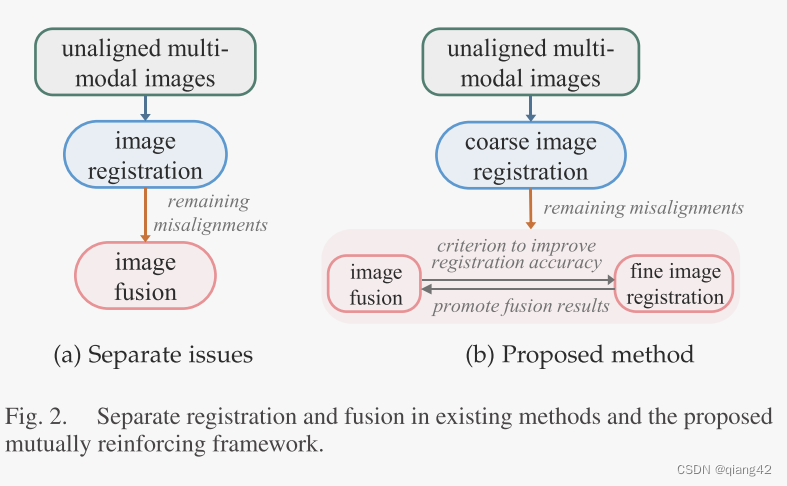
作者认为【图像融合可以反向消除未配准】,因为:
- 融合图像来源于不同模态,减轻了模态差异,降低了配准难度
- 融合过程去除了冗余信息,减少了这些信息对配准的负面影响
- 梯度稀疏可以作为融合评价标准,以反馈的方式提高配准精度
🪢网络结构
作者提出的网络结构如下所示。
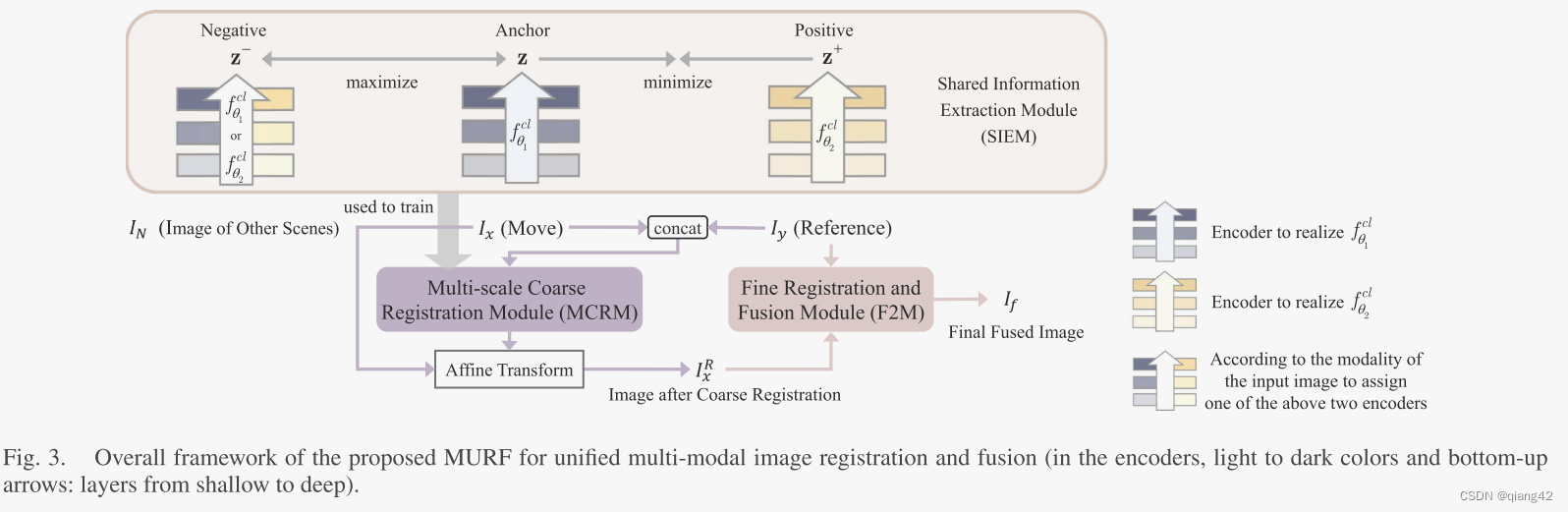
该网络模型由SIEM, MCRM和F2M组成。上节已经简单介绍了各个模块的作用。接下来让我们看模块内部在干嘛
🪢SIEM

采用了【对比学习】的思想。相同场景的图像对应于较近的表示,而不同场景的图像对应于较远的表示。
扩展学习链接
对比学习(contrastive learning)
多模态数据集包括了配准/粗配准的图像对
{
I
x
i
,
I
y
i
}
i
=
1
K
\{I_x^i,I_y^i\}_{i=1}^K
{Ixi?,Iyi?}i=1K?,K表示图像对的数量。
I
x
I_x
Ix?和
I
y
I_y
Iy?分别表示不同模态
X
\mathcal X
X和
Y
\mathcal Y
Y的图像。
这个模块的目标是学习两个函数
f
θ
1
c
l
(
?
)
f_{\theta1}^{cl}(·)
fθ1cl?(?)和
f
θ
2
c
l
(
?
)
f_{\theta2}^{cl}(·)
fθ2cl?(?),将不同模态的图像映射到共享潜在空间,从而提取其潜在表示
z
x
i
=
f
θ
1
c
l
(
I
x
i
)
z_x^i=f_{\theta1}^{cl}(I_x^i)
zxi?=fθ1cl?(Ixi?)和
z
y
i
=
f
θ
2
c
l
(
I
y
i
)
z_y^i=f_{\theta2}^{cl}(I_y^i)
zyi?=fθ2cl?(Iyi?)
{
I
x
i
,
I
y
i
}
\{I_x^i,I_y^i\}
{Ixi?,Iyi?}表示相同场景的图像对,因此
{
z
x
i
,
z
y
i
}
\{z_x^i,z_y^i\}
{zxi?,zyi?}是正对(positive pairs),应该被拉入潜在空间。
{
I
x
i
,
I
y
j
(
i
≠
j
)
}
\{I_x^i,I_y^{j(i \neq j)}\}
{Ixi?,Iyj(i=j)?}或者
{
I
x
i
,
I
x
j
(
i
≠
j
)
}
\{I_x^i,I_x^{j(i \neq j)}\}
{Ixi?,Ixj(i=j)?}表示多模态或者不同场景的单模态图像,是负对,应该被分离。
用来学习
f
θ
1
c
l
(
?
)
f_{\theta1}^{cl}(·)
fθ1cl?(?)和
f
θ
2
c
l
(
?
)
f_{\theta2}^{cl}(·)
fθ2cl?(?)对比学习的损失函数被定义为InfoNCE损失:
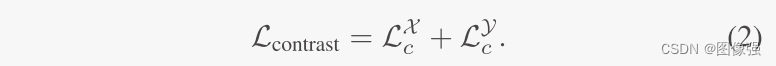
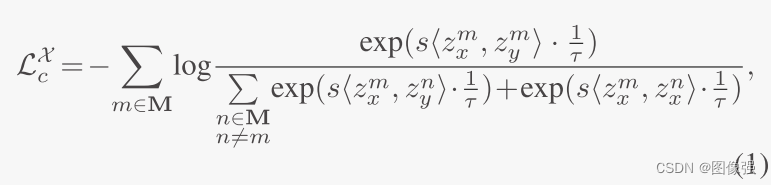
s
(
?
)
s(·)
s(?)是鉴别器函数,正对值高负对值低。
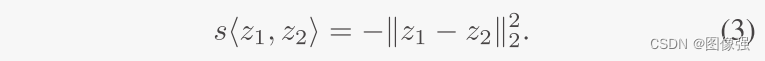
同时,作者利用旋转等价来细化潜表示的精细度。即对
f
θ
1
c
l
(
?
)
f_{\theta1}^{cl}(·)
fθ1cl?(?)和
f
θ
2
c
l
(
?
)
f_{\theta2}^{cl}(·)
fθ2cl?(?)进行像素级旋转和反向旋转。
🪢MCRM
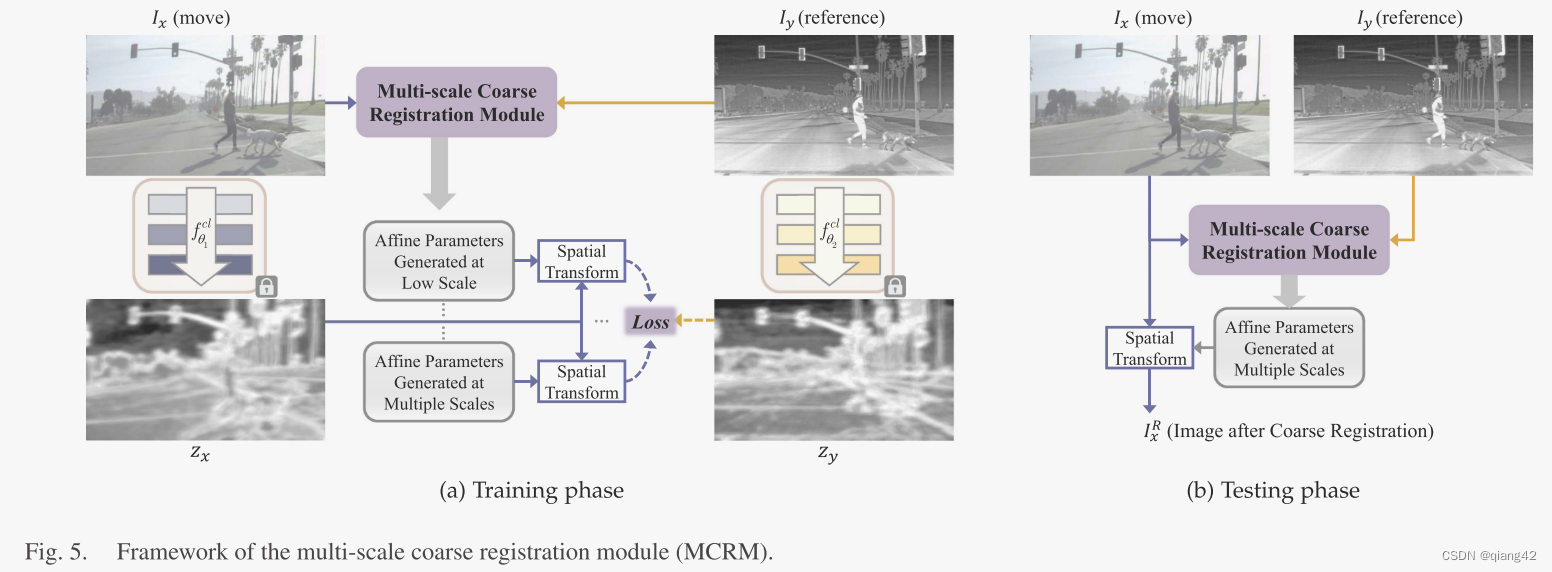
在训练阶段,使用上一节训练好的
f
θ
1
c
l
(
?
)
f_{\theta1}^{cl}(·)
fθ1cl?(?)和
f
θ
2
c
l
(
?
)
f_{\theta2}^{cl}(·)
fθ2cl?(?)提取
I
x
I_x
Ix?和
I
y
I_y
Iy?的共享信息
z
x
z_x
zx?和
z
y
z_y
zy?,然后利用仿射变换(affine transform)提高
z
x
z_x
zx?和
z
y
z_y
zy?之间的配准度。注意,训练阶段SIEM里参数是固定的。在测试阶段,只有MCRM用于粗配准。
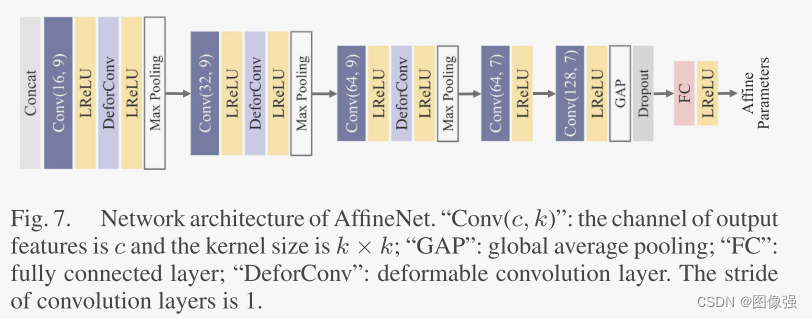
在单尺度的网络中,使用大的卷积核和较深的网络结构是常态,为了解决这个问题,作者采用了一种多尺度渐进式配准策略减少参数量、加快收敛速度。
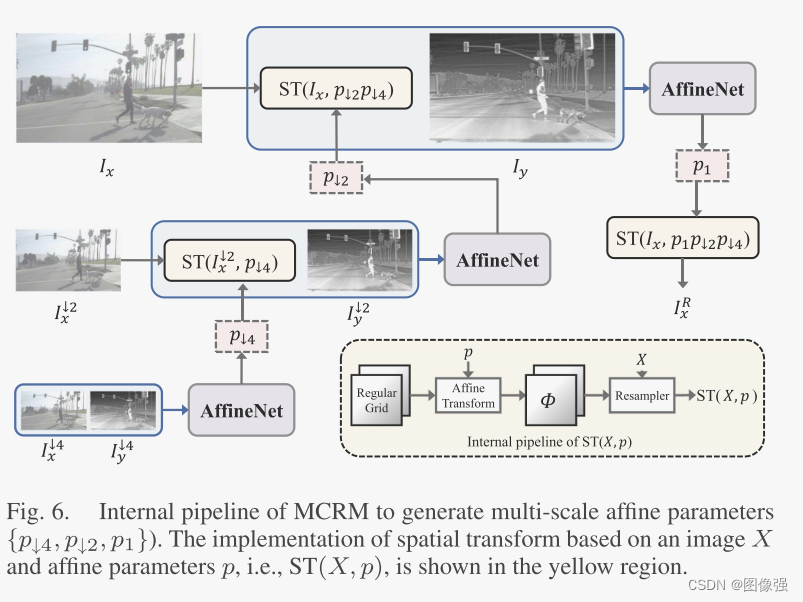
这个图应该从下往上看,即一开始训练AffineNet是下采样4倍的时候,然后在下采样2倍的时候继续,使用下采样4倍的参数作为粗空间变换。同理,到原尺寸的时候,使用4倍和2倍的参数作为粗空间变换,得到最精细的参数p1。即输出为粗配准的图像
I
x
R
=
S
T
(
I
x
,
p
1
P
↓
2
P
↓
4
)
I_x^R=ST(I_x,p_1P_{↓2}P_{↓4})
IxR?=ST(Ix?,p1?P↓2?P↓4?)
那么空间变换是什么样子的呢?
给定一个图像X和仿射参数p,在常规采样网格上使用p,生成一个H×W×2的形变场
?
\phi
?,代表了X中像素的变形。形变场
?
\phi
?的两个通道分别代表垂直方向和水平方向:
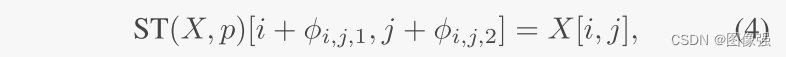
该模块的损失函数为:
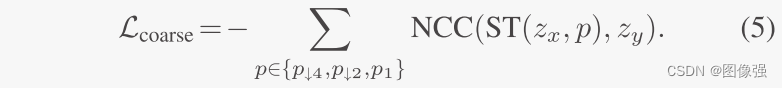
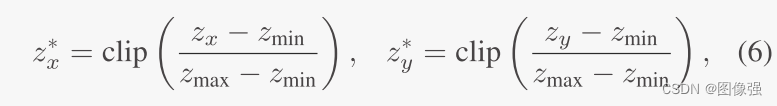
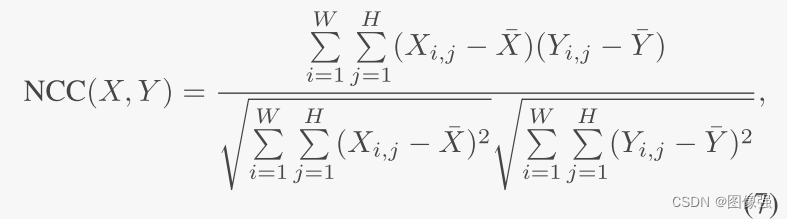
🪢F2M
这个模块在训练分为两个阶段,融合阶段和微配准阶段。
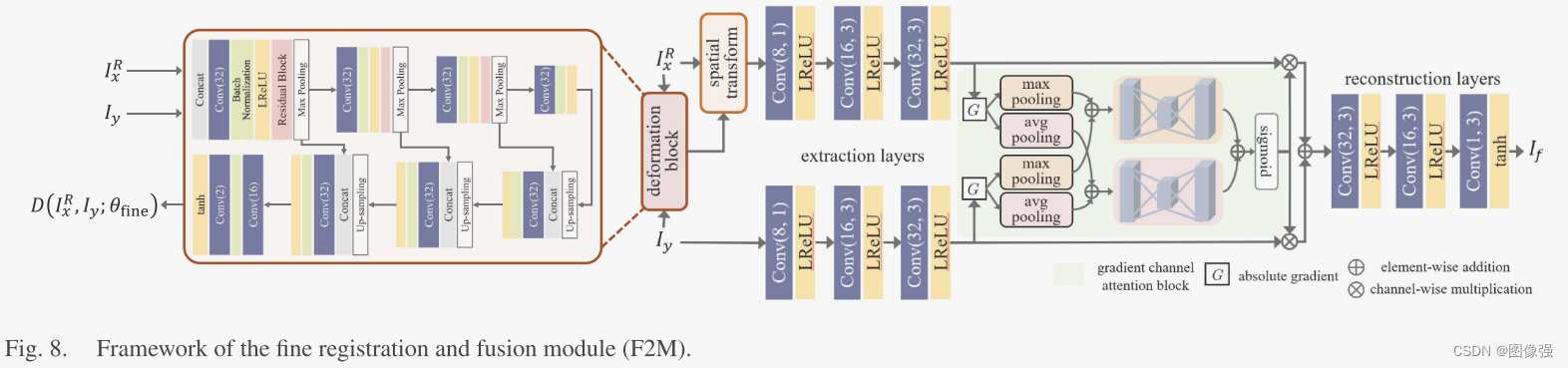
测试阶段,将粗配准的图像
I
x
R
I_x^R
IxR?和
I
y
I_y
Iy?输入变形块进行空间变换以及矫正局部视差,得到变形后的
I
x
R
I_x^R
IxR?即
I
x
F
I_x^F
IxF?。然后通过后续的提取层、梯度通道注意力块、重构层融合得到最终的融合图像
I
f
I_f
If?。
图像融合的损失函数为:
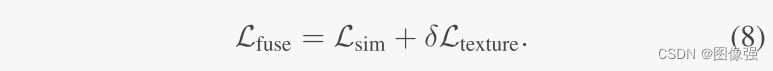
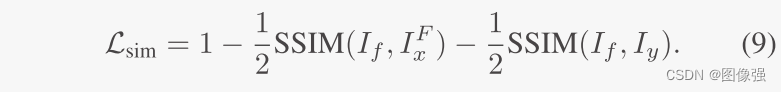
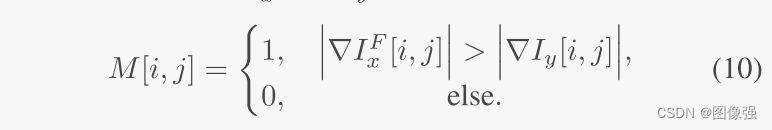
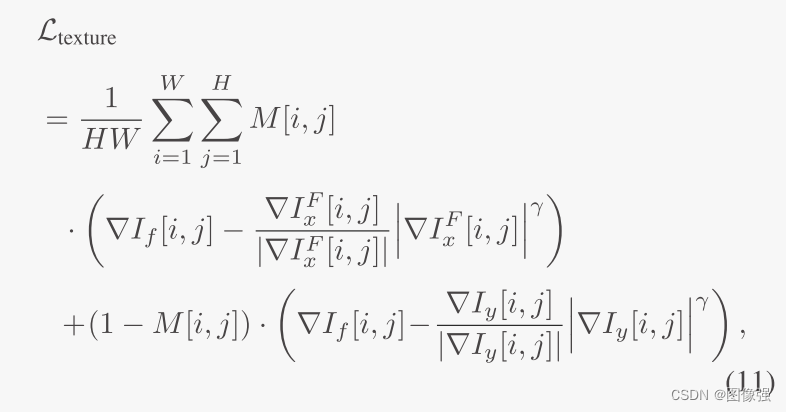
在训练微配准网络的时候,生成了一个局部平滑的非刚性形变场
?
n
r
\phi^{nr}
?nr

微调配准损失函数:

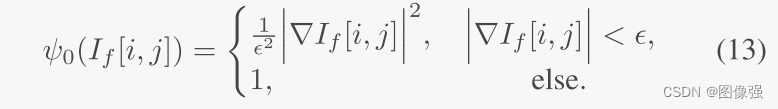
📉损失函数
上面分节已介绍
🔢数据集
图像融合数据集链接
[图像融合常用数据集整理]
🎢训练设置

🔬实验
📏评价指标
- MG
- EI
- VIF
参考资料
[图像融合定量指标分析]
🥅Baseline
- DenseFuse, DIF-Net, IFCNN, MDLatLRR, RFN-Nest, U2Fusion
???参考资料
???强烈推荐必看博客[图像融合论文baseline及其网络模型]???
🔬实验结果
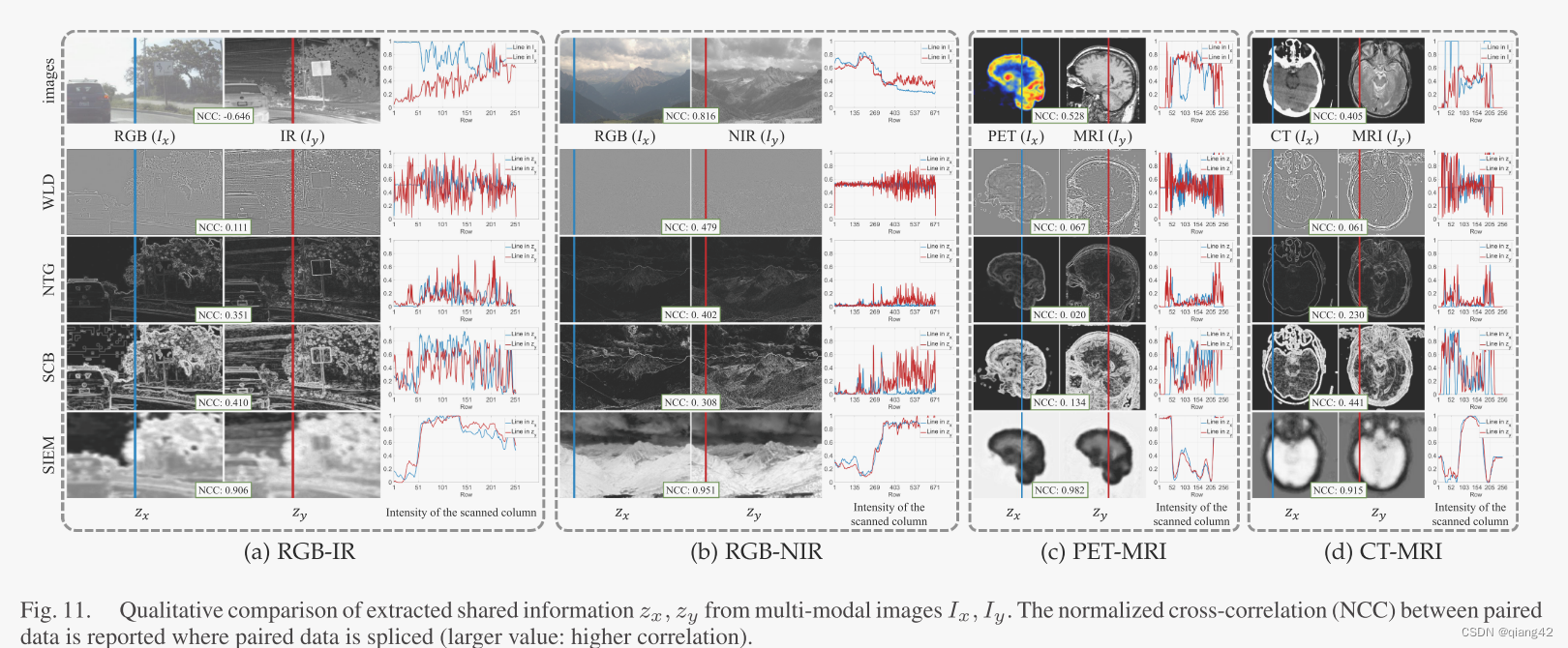

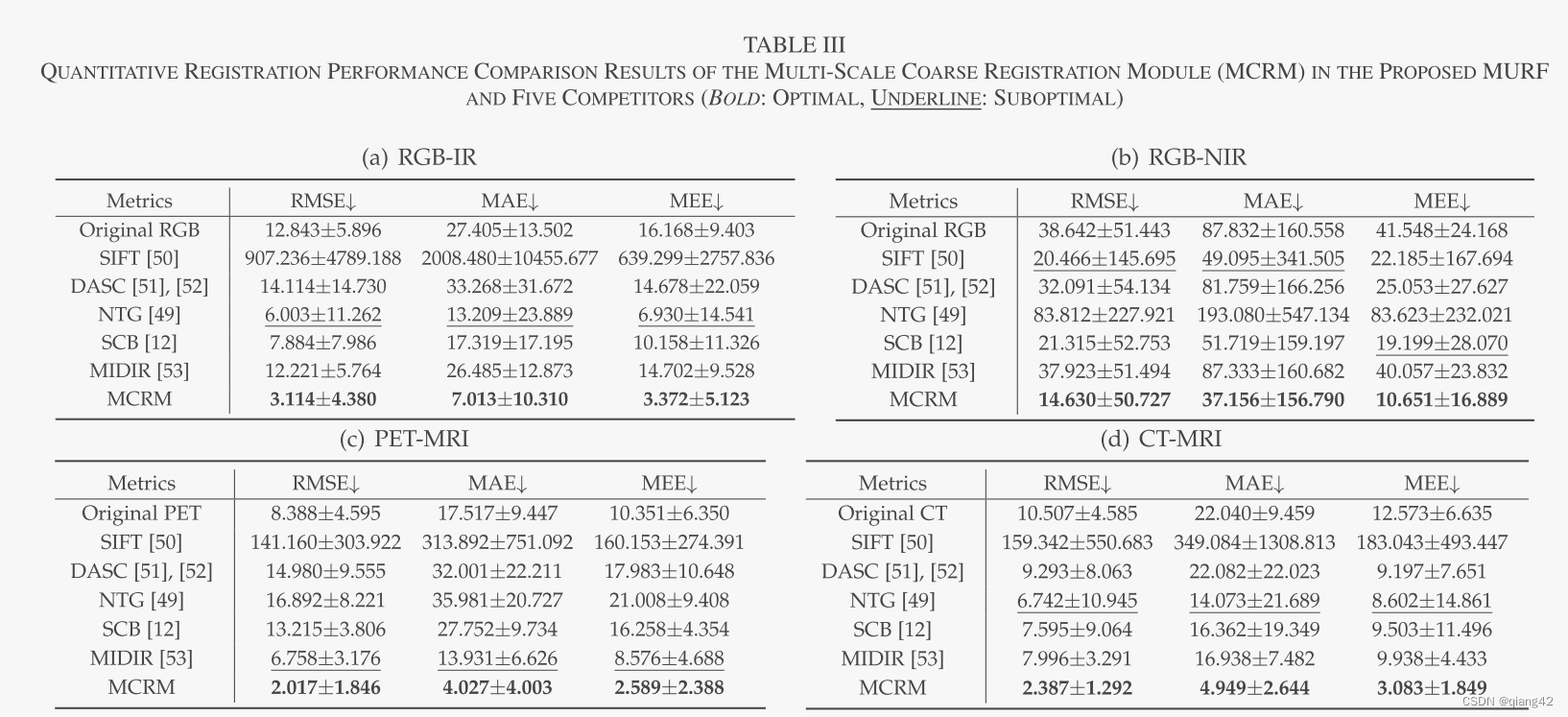

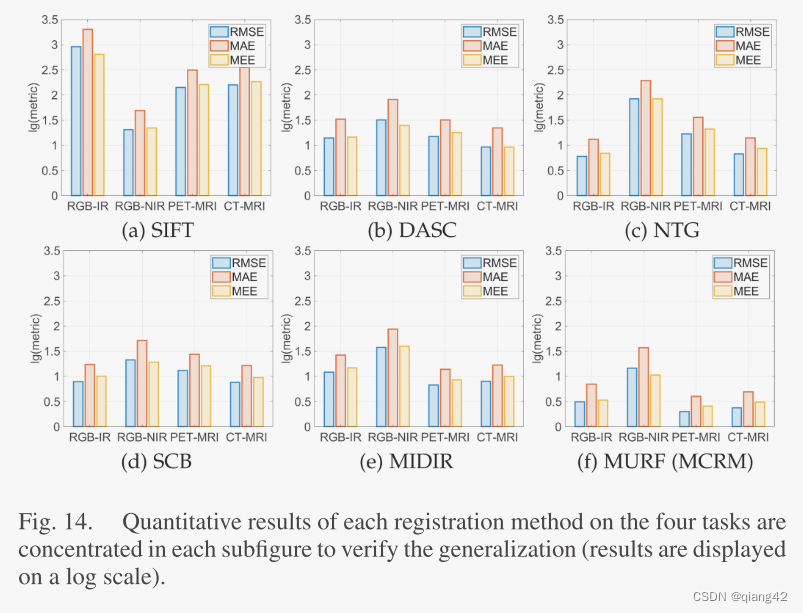
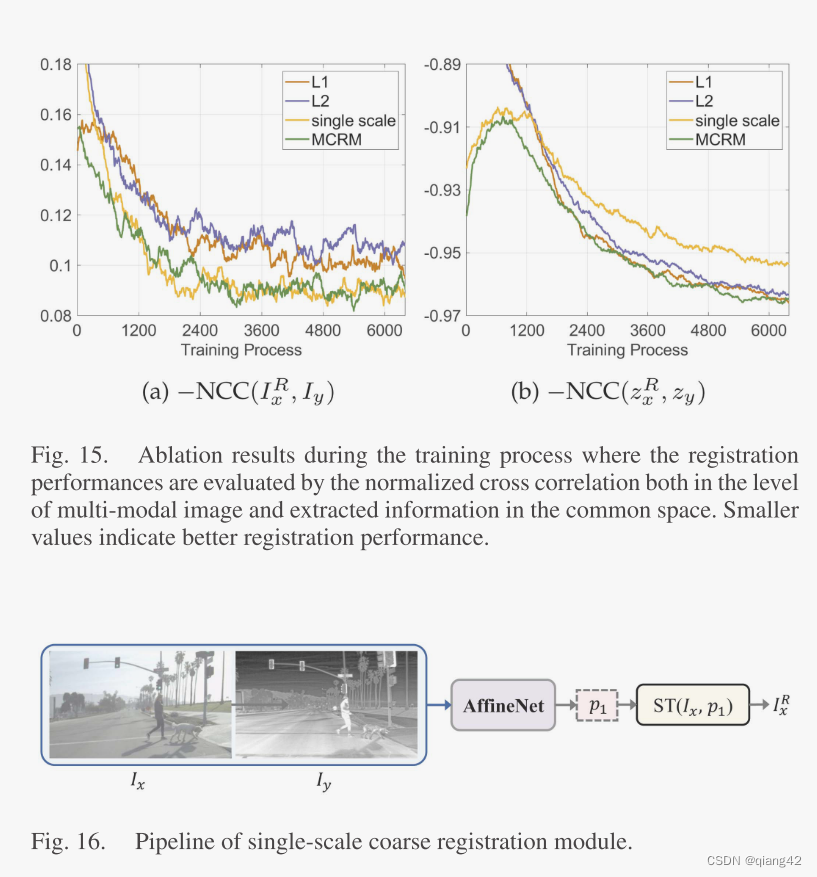
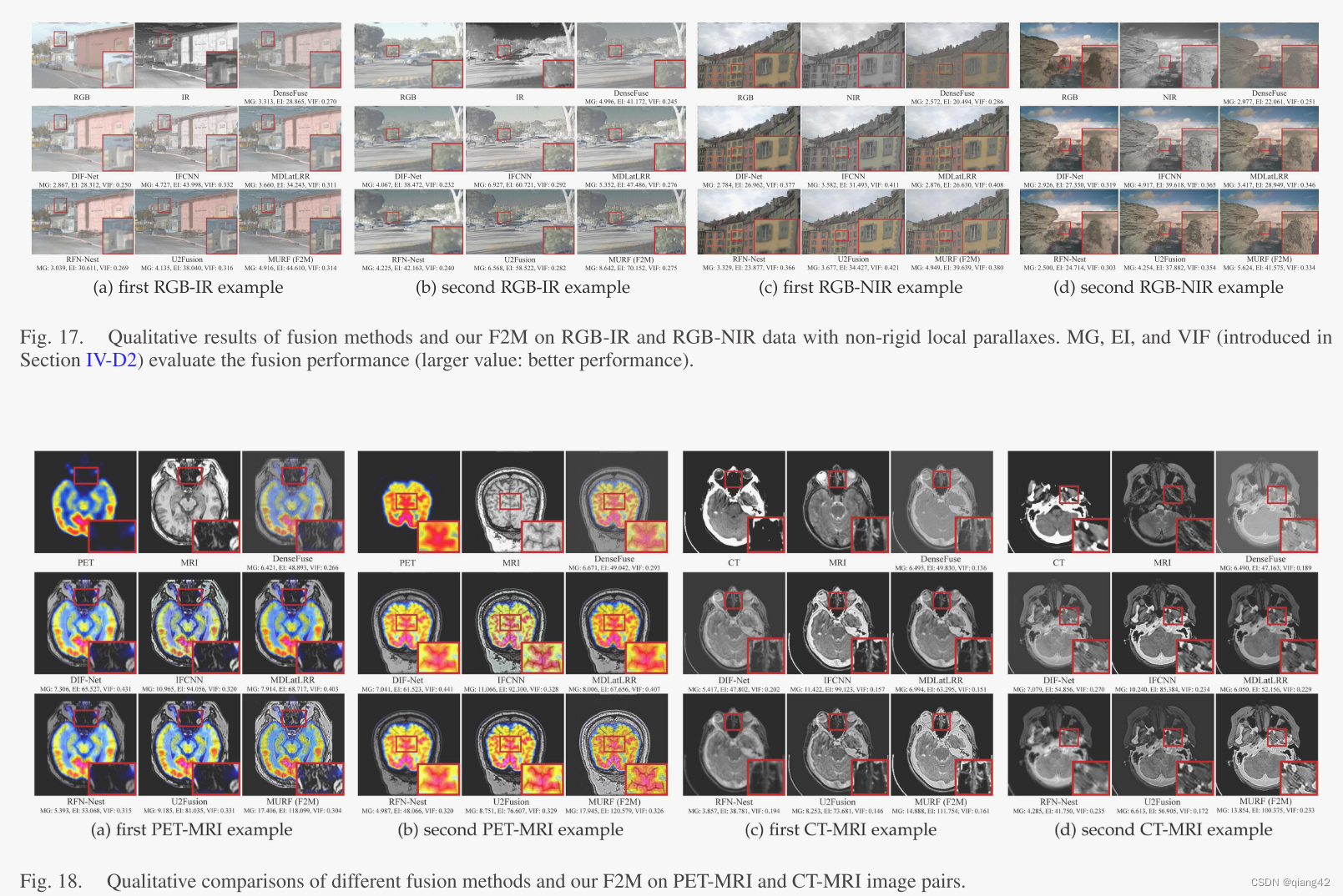
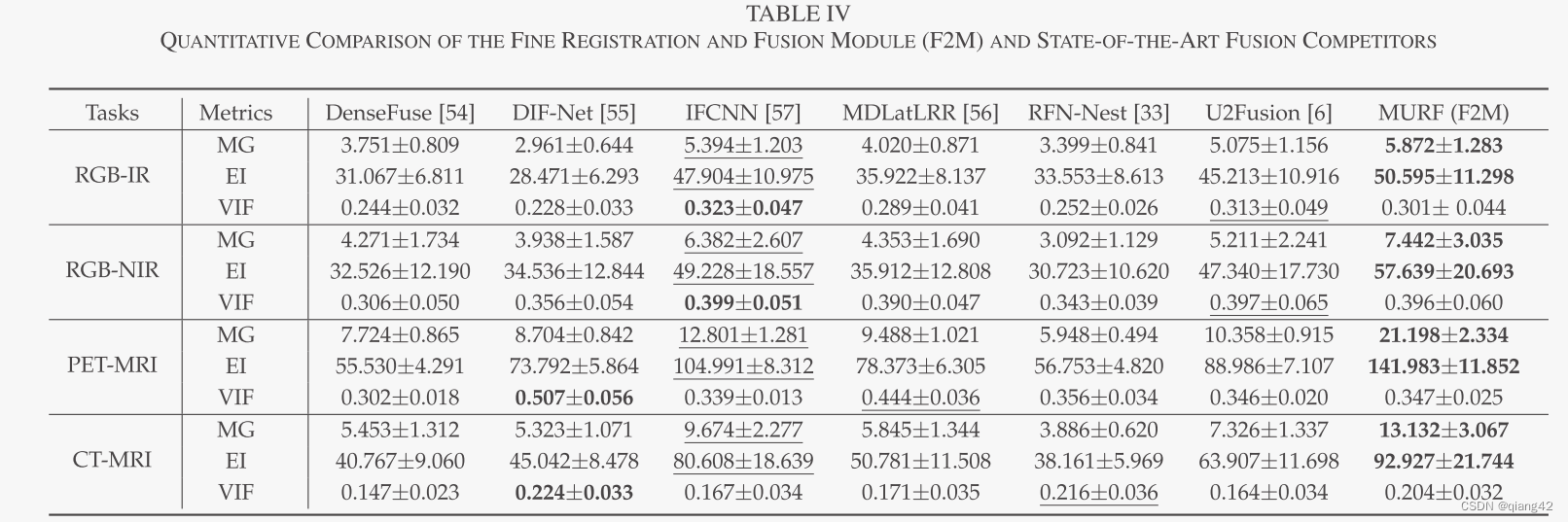

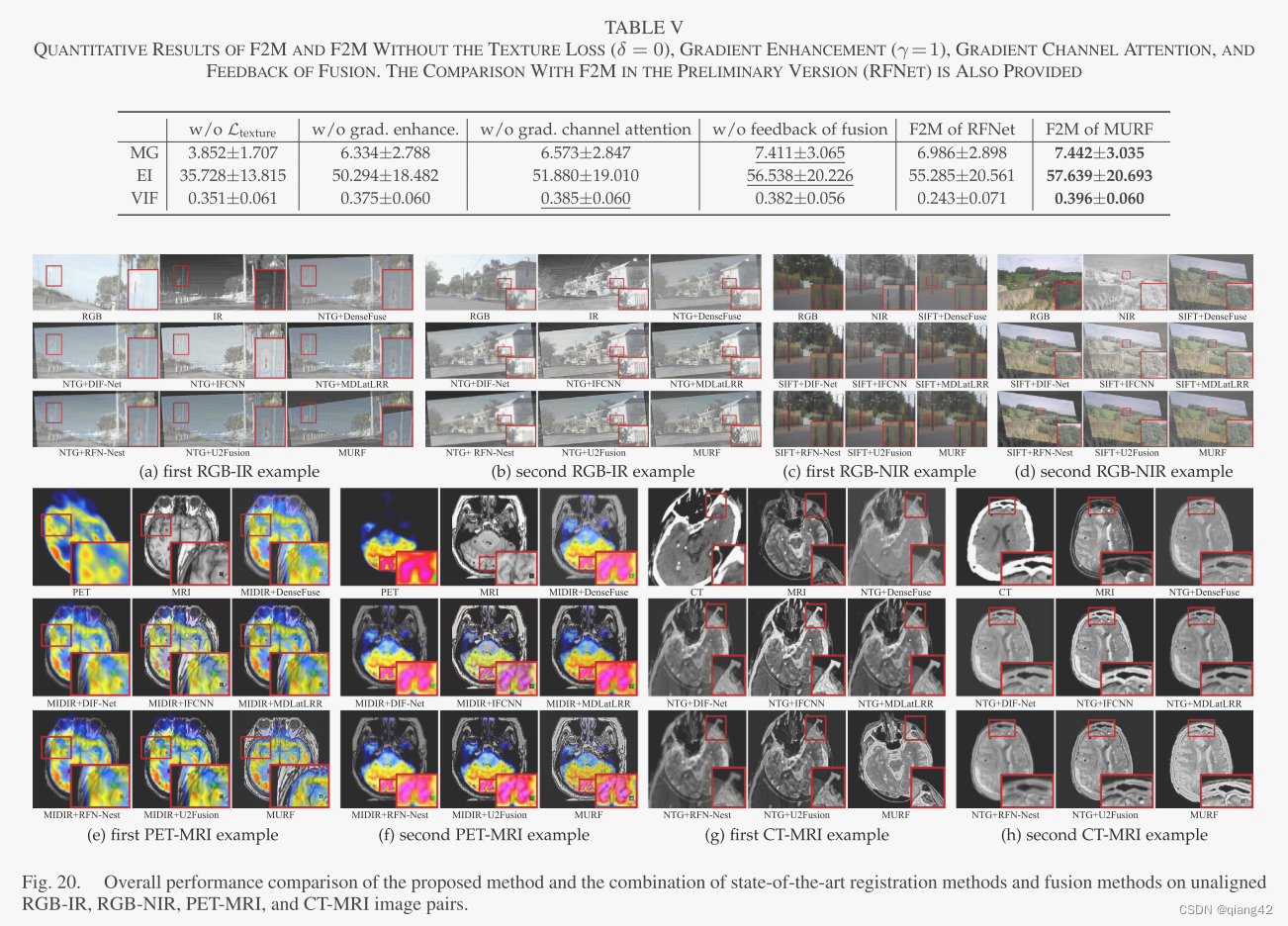

更多实验结果及分析可以查看原文:
📖[论文下载地址]
🚀传送门
📑图像融合相关论文阅读笔记
📑[(A Deep Learning Framework for Infrared and Visible Image Fusion Without Strict Registration]
📑[(APWNet)Real-time infrared and visible image fusion network using adaptive pixel weighting strategy]
📑[Dif-fusion: Towards high color fidelity in infrared and visible image fusion with diffusion models]
📑[Coconet: Coupled contrastive learning network with multi-level feature ensemble for multi-modality image fusion]
📑[LRRNet: A Novel Representation Learning Guided Fusion Network for Infrared and Visible Images]
📑[(DeFusion)Fusion from decomposition: A self-supervised decomposition approach for image fusion]
📑[ReCoNet: Recurrent Correction Network for Fast and Efficient Multi-modality Image Fusion]
📑[RFN-Nest: An end-to-end resid- ual fusion network for infrared and visible images]
📑[SwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible Images]
📑[SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer]
📑[(MFEIF)Learning a Deep Multi-Scale Feature Ensemble and an Edge-Attention Guidance for Image Fusion]
📑[DenseFuse: A fusion approach to infrared and visible images]
📑[DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pair]
📑[GANMcC: A Generative Adversarial Network With Multiclassification Constraints for IVIF]
📑[DIDFuse: Deep Image Decomposition for Infrared and Visible Image Fusion]
📑[IFCNN: A general image fusion framework based on convolutional neural network]
📑[(PMGI) Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity]
📑[SDNet: A Versatile Squeeze-and-Decomposition Network for Real-Time Image Fusion]
📑[DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion]
📑[FusionGAN: A generative adversarial network for infrared and visible image fusion]
📑[PIAFusion: A progressive infrared and visible image fusion network based on illumination aw]
📑[CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion]
📑[U2Fusion: A Unified Unsupervised Image Fusion Network]
📑综述[Visible and Infrared Image Fusion Using Deep Learning]
📚图像融合论文baseline总结
📑其他论文
📑[3D目标检测综述:Multi-Modal 3D Object Detection in Autonomous Driving:A Survey]
🎈其他总结
🎈[CVPR2023、ICCV2023论文题目汇总及词频统计]
?精品文章总结
?[图像融合论文及代码整理最全大合集]
?[图像融合常用数据集整理]
如有疑问可联系:420269520@qq.com;
码字不易,【关注,收藏,点赞】一键三连是我持续更新的动力
祝各位早发paper,顺利毕业~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!