.Net中的集合
所有的集合都是继承自IEnumerable。集合总体可以分为以下几类:关联/非关联型集合,顺序/随机访问集合,顺序/无序集合,泛型/非泛型集合,线程集合。
各集合类底层接口关系图
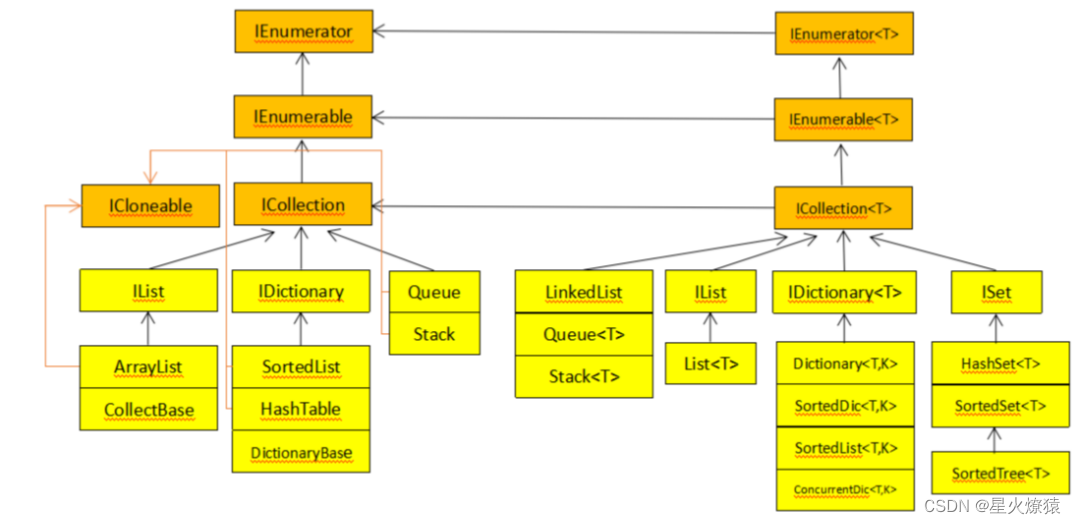
泛型与非泛型集合类的分析
- 泛型集合是类型安全的,基于固定的泛型T,运行时不需要像非泛型的执行Object和具体类型的类型转换。泛型集合的效率相对较高。
- 两者都能实现数据存储,不同的是泛型只能存放T类型数据,有运行时检测,而非泛型的都转化为Object存储,能存储任意类型,包括值类型,会带来装箱拆箱的性能损耗,同时都是Object类型(弱类型)编译时无法类型检测,运行时会导致类型不一致的安全性问题。
具体接口/类分析
- CollectionBase/DictionaryBase的目的都是抽象类,不能实例化;目的是提供给用户自定义实现强类型的集合,解决一般非泛型集合的弱类型不安全的问题。
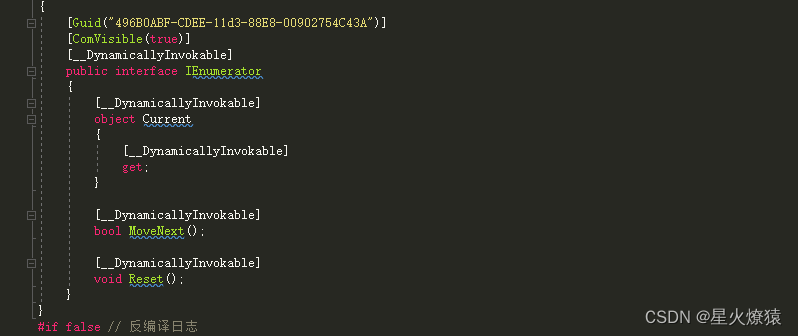
IEnumerator和IEnumerator<T>
IEnumerator定义了我们遍历集合的基本方法,以便我们可以实现单向向前的访问集合中的每一个元素。所有的集合类都继承了IEnumerator接口,包括String类。而IEnumerable只有一个方法GetEnumerator即得到遍历器。


ICollection和ICollection<T>
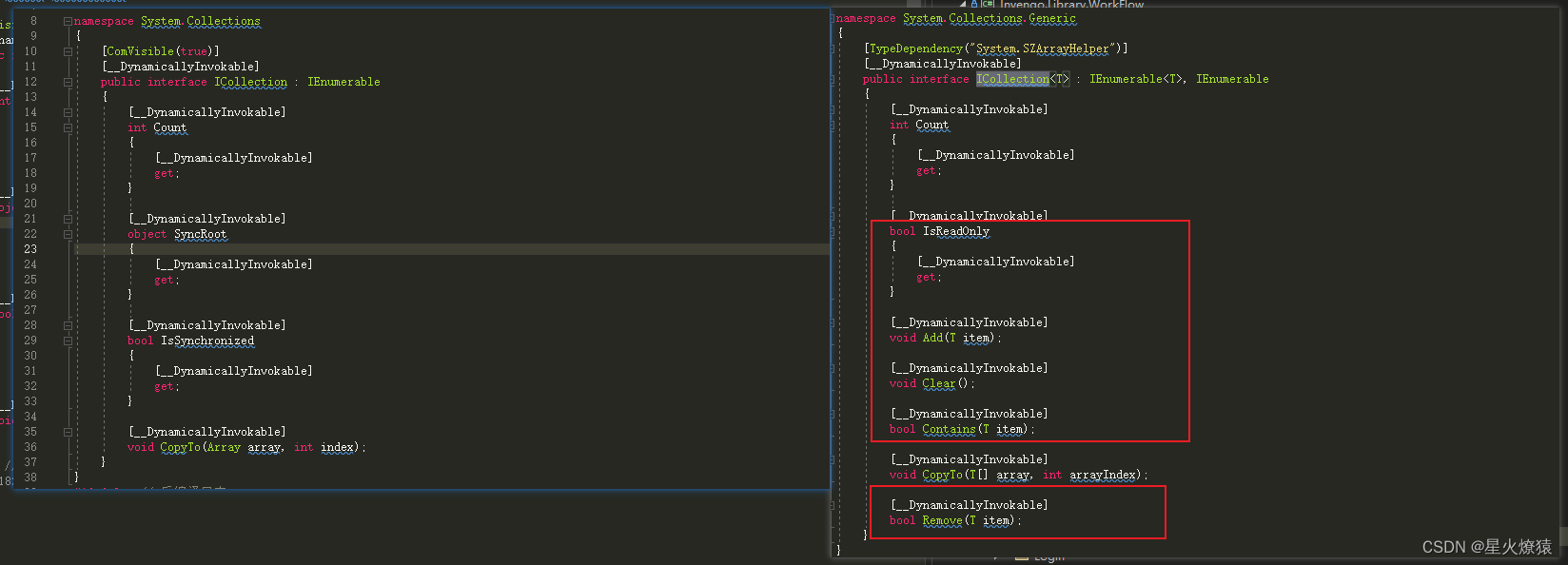
从最上面第一张图我们可以知道,ICollection<T>是直接继承自IEnumerable<T>。而实际上也是如此,我们可以说ICollection<T>比IEnumerable多支持一些功能,不仅仅只提供基本的遍历功能,还包括:
- 统计集合和元素个数
- 获取元素的下标
- 判断是否存在
- 添加元素到未尾
- 移除元素等等。。。
ICollection 与ICollection<T>略有不同,ICollection不提供编辑集合的功能,即Add和Remove。包括检查元素是否存在Contains也不支持。
IList和IList<T>
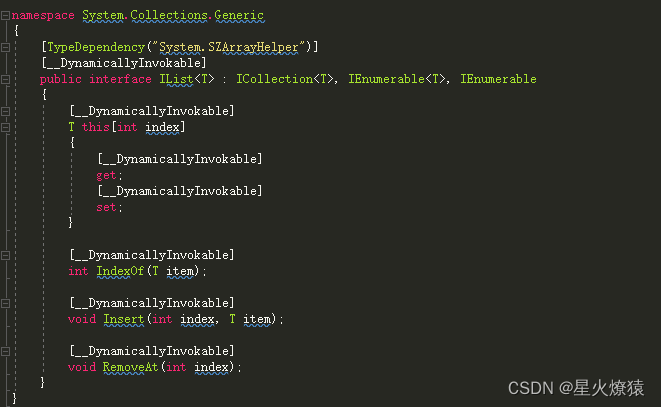
IList<T>则是直接继承自ICollection<T>和IEnumerable<T>。所以它包括两者的功能,并且支持根据下标访问和添加元素。IndexOf, Insert, RemoveAt等等。我们可以这样说,IEnumerable支持的功能最少,只有遍历。而ICollection支持的功能稍微多一点,不仅有遍历还有维护这个集合的功能。而IList<T>是最全的版本。
IReadOnlyList
这个是在Framework4.5中新增的接口类型,可以被看作是IList的缩减版,去掉了所有可能更改这个集合的功能。比如:Add, RemoveAt等等。
IDictionary<TKey,TValue>
IDictionary提供了对键值对集合的访问,也是继承了ICollection和IEnumerable,扩展了通过Key来访问和操作数据的方法。
关联性泛型集合类
关联性集合类即我们常说的键值对集合,允许我们通过Key来访问和维护集合。我们先来看一下 FCL为我们提供了哪些泛型的关联性集合类:
Dictionary <TKey,TValue>
SortedDictionary<TKey,TValue>
SortedList<TKey,TValue>
Dictionary<TKey,TValue>
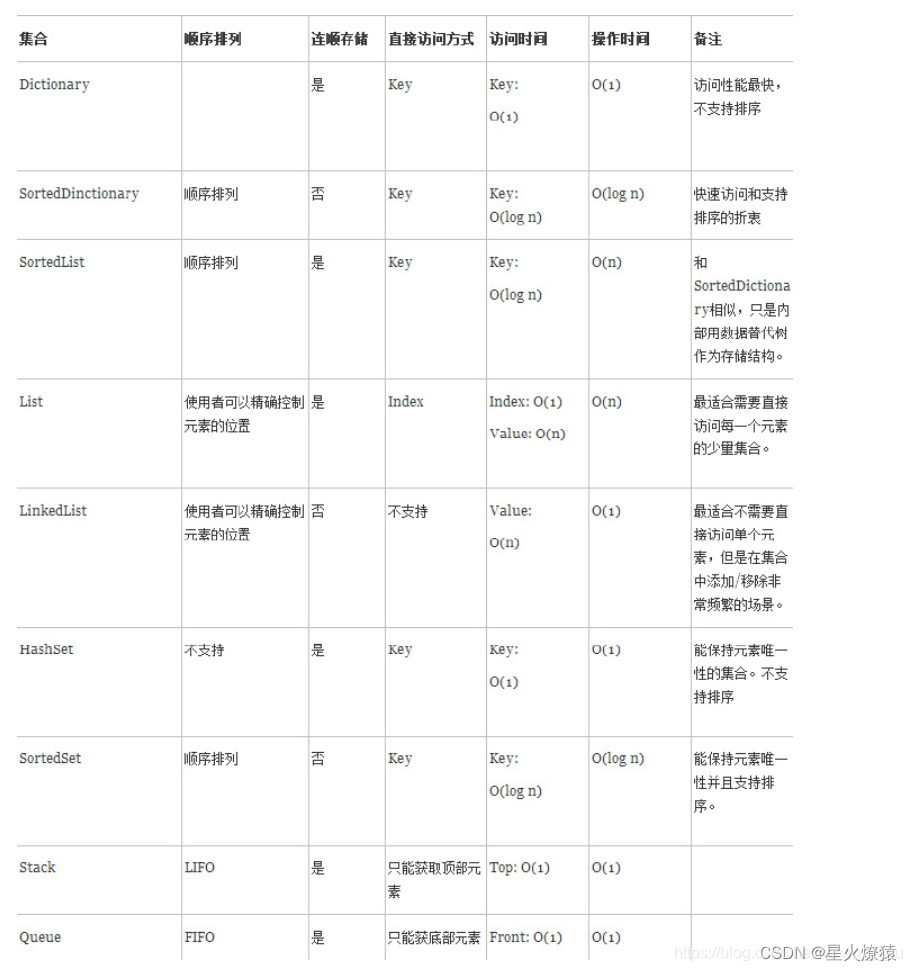
- 是我们最常用的关联性集合了,它的访问,添加,删除数据所花费的时间是所有集合类里面最快的,因为它内部用了Hashtable作为存储结构,所以不管存储了多少键值对,查询/添加/删除所花费的时间都是一样的,它的时间复杂度是O(1)。
Dictionary<TKey,TValue>优势是查找插入速度快==,那么什么是它的劣势呢?因为采用Hashtable1作为存储结构,就意味着里面的数据是无序排列的,所以想按一定的顺序去遍历Dictionary<TKey,TValue>里面的数据是要费一点工夫的。
作为TKey的类型必须实现GetHashCode()和Equals()或者提供一个IEqualityComparer,否则操作可能会出现问题。
SortedDictioanry<TKey,TValue>
SortedDictionary<TKey,TValue>和Dictionary<TKey,TValue>大致上是类似的,但是在实现方式上有一点点区别。SortedDictionary<TKey,TValue>用二叉树作为存储结构的。并且按key的顺序排列。那么这样的话SortedDictionary<TKey,TValue>的TKey就必须要实现IComparable。如果想要快速查询的同时又能很好的支持排序的话,那就使用SortedDictionary吧。
SortedList<TKey,TValue>
SortedList<TKey,TValue>是另一个支持排序的关联性集合。但是不同的地方在于,SortedList实际是将数据存存储在数组中的。也就是说添加和移除操作都是线性的,时间复杂度是O(n),因为操作其中的元素可能导致所有的数据移动。但是因为在查找的时候利用了二分搜索,所以查找的性能会好一些,时间复杂度是O(log n)。所以推荐使用场景是这样地:如果你想要快速查找,又想集合按照key的顺序排列,最后这个集合的操作(添加和移除)比较少的话,就是SortedList了。
非关联性泛型集合类
非关联性集合就是不用key操作的一些集合类,通常我们可以用元素本身或者下标来操作。FCL主要为我们提供了以下几种非关联性的泛型集合类。
- List
- LinkedList
- HashSet
- SortedSet
- Stack
- Queue
List
- 泛型的List 类提供了不限制长度的集合类型,List在内部维护了一定长度的数组(默认初始长度是4),当我们插入元素的长度超过4或者初始长度 的时候,会去重新创建一个新的数组,这个新数组的长度是初始长度的2倍(不永远是2倍,当发现不断的要扩充的时候,倍数会变大),然后把原来的数组拷贝过来。所以如果知道我们将要用这个集合装多少个元素的话,可以在创建的时候指定初始值,这样就避免了重复的创建新数组和拷贝值。
- 另外的话由于内部实质是一个数组,所以在List的未必添加数据是比较快的,但是如果在数据的头或者中间添加删除数据相对来说更低效一些因为会影响其它数据的重新排列。
LinkedList
LinkedList在内部维护了一个双向的链表,也就是说我们在LinkedList的任何位置添加或者删除数据其性能都是很快的。因为它不会导致其它元素的移动。一般情况下List已经够我们使用了,但是如果对这个集合在中间的添加删除操作非常频繁的话,就建议使用LinkedList。
HashSet
HashSet是一个无序的能够保持唯一性的集合。我们也可以把HashSet看作是Dictionary<TKey,TValue>,只不过TKey和TValue都指向同一个对象。HashSet非常适合在我们需要保持集合内元素唯一性但又不需要按顺序排列的时候。HashSet不支持下标访问。
SortedSet
SortedSet和HashSet,就像SortedDictionary和Dictionary一样,还记得这两个的区别么?SortedSet内部也是一个二叉树,用来支持按顺序的排列元素。
Stack
后进先出的队列,不支持按下标访问
Queue
先进先出的队列,不支持按下标访问
推荐使用方式
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!