Java面试题(每天10题)-------连载(45)
2023-12-13 05:05:46
Dubbo篇
1、Dubbo的服务调用流程
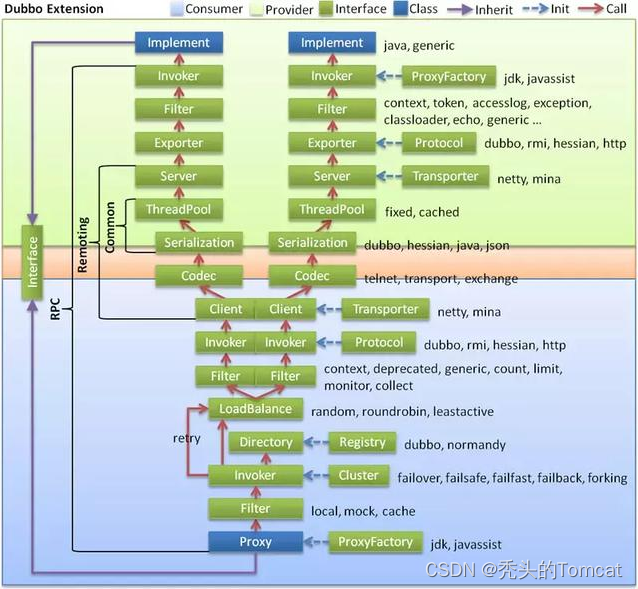
2、Dubbo支持那种协议,每种协议的应用场景,优缺点?
- dubbo: 单一长连接和 NIO 异步通讯,适合大并发小数据量的服务调用,以及消费者远大于提供者。传输协议 TCP,异步,Hessian 序列化;
- rmi: 采用 JDK 标准的 rmi 协议实现,传输参数和返回参数对象需要实现 Serializable 接口,使用 java 标准序列化机制,使用阻塞式短连接,传输数据包大小混合,消费者和提供者个数差不多,可传文件,传输协议 TCP。 多个短连接,TCP 协议传输,同步传输,适用常规的远程服务调用和 rmi 互操作。在依赖低版本的 Common-Collections包,java 序列化存在安全漏洞;
- webservice: 基于 WebService 的远程调用协议,集成 CXF 实现,提供和原生 WebService 的互操作。多个短连接,基于 HTTP 传输,同步传输,适用系统集成和跨语言调用;
- http: 基于 Http 表单提交的远程调用协议,使用 Spring 的HttpInvoke 实现。多个短连接,传输协议 HTTP,传入参数大小混合,提供者个数多于消费者,需要给应用程序和浏览器 JS 调用;
- hessian: 集成 Hessian 服务,基于 HTTP 通讯,采用 Servlet 暴露服务,Dubbo 内嵌 Jetty 作为服务器时默认实现,提供与 Hession 服务互操作。多个短连接,同步 HTTP 传输,Hessian 序列化,传入参数较大,提供者大于消费者,提供者压力较大,可传文件;
- memcache: 基于 memcached 实现的 RPC 协议
- redis: 基于 redis 实现的 RPC 协议
3、Dubbo推荐用什么协议?
默认使用 dubbo 协议
4、Dubbo中有哪些注册中心?
- Multicast 注册中心: Multicast 注册中心不需要任何中心节点,只要广播地址,就能进行服务注册和发现。基于网络中组播传输实现;
- Zookeeper 注册中心: 基于分布式协调系统 Zookeeper 实现,采用Zookeeper 的 watch 机制实现数据变更;
- redis 注册中心: 基于 redis 实现,采用 key/Map 存储,住 key 存储服务名和类型,Map 中 key 存储服务 URL,value 服务过期时间。基于 redis 的发布/订阅模式通知数据变更;
- Simple 注册中心
- Dubbo 默认采用 Zookeeper
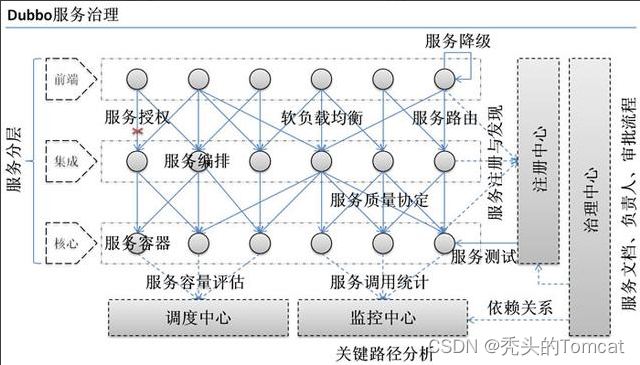
5、为什么需要服务治理?
- 过多的服务 URL 配置困难
- 负载均衡分配节点压力过大的情况下也需要部署集群?
- 服务依赖混乱,启动顺序不清晰
- 过多服务导致性能指标分析难度较大,需要监控
6、Dubbo的注册中心集群挂掉,发布者和订阅者之间还能通信吗?
可以的,启动 dubbo 时,消费者会从 zookeeper 拉取注册的生产者的地址接口等数据,缓存在本地。每次调用时,按照本地存储的地址进行调用。
7、Dubbo与Spring的关系
Dubbo 采用全 Spring 配置方式,透明化接入应用,对应用没有任何API 侵入,只需用 Spring 加载 Dubbo 的配置即可,Dubbo 基于Spring 的 Schema 扩展进行加载。
8、Dubbo使用的是什么通信框架?
默认使用 NIO Netty 框架
9、Dubbo集群提供了那些负载均衡策略?
- Random LoadBalance: 随机选取提供者策略,有利于动态调整提供者权重。截面碰撞率高,调用次数越多,分布越均匀;
- RoundRobin LoadBalance: 轮循选取提供者策略,平均分布,但是存在请求累积的问题;
- LeastActive LoadBalance: 最少活跃调用策略,解决慢提供者接收更少的请求;
- ConstantHash LoadBalance: 一致性 Hash 策略,使相同参数请求总是发到同一提供者,一台机器宕机,可以基于虚拟节点,分摊至其他提供者,避免引起提供者的剧烈变动;
- 缺省时为 Random 随机调用
10、Dubbo的集群容错方案有哪些?
- Failover Cluster?失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。
- Failfast Cluster 快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
- Failsafe Cluster 失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
- Failback Cluster 失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
- Forking Cluster?并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks="2" 来设置最大并行数。
- Broadcast Cluster 广播调用所有提供者,逐个调用,任意一台报错则报错 。通常用于通知所有提供者更新缓存或日志等本地资源信息。
文章来源:https://blog.csdn.net/tgdmjhf/article/details/134869444
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!