二十九、微服务案例完善(数据聚合、自动补全、数据同步)
目录
一、定义
聚合( aggregations)可以实现对文档数据的统计、分析、运算。
二、分类
1、桶(Bucket)聚合:
-
用来对文档做分组
TermAggregation:按照文档字段值分组
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
2、度量(Metric)聚合:
- 用以计算一些值,比如:最大值、最小值、平均值等
- 计数(COUNT):计算指定列中非空值的数量。
- 求和(SUM):计算指定列中所有数值的总和。
- 平均值(AVG):计算指定列中所有数值的平均值。
- 最大值(MAX):查找指定列中的最大值。
- 最小值(MIN):查找指定列中的最小值。
3、管道聚合(Pipeline Aggregation):
- 管道聚合是MongoDB中一种强大的数据聚合工具,它可用于通过将多个聚合操作连接在一起来对文档进行处理。
- 通过管道聚合,MongoDB用户可以使用多个聚合操作按顺序执行,以生成更为复杂、细致和灵活的数据查询和汇总结果。
- 管道聚合可以处理来自单个或多个集合的数据。
一般而言,MongoDB 的聚合管道通过 $ 开头的操作符来实现数据聚合操作。以下是一些常见的聚合管道操作:
1. $match:用于选择满足条件的文档,可以通过使用查询条件来过滤文档。
2. $group:用于将文档分组,通过指定一个或多个字段进行分组,对每个分组执行聚合操作,最终返回每个组的统计结果。
3. $project:用于选择文档的特定字段,并输出指定的字段。
4. $sort:用于对文档进行排序,可以根据指定字段进行升序或降序排列。
5. $limit:用于限制输出文档的数量。
6. $skip:用于跳过指定数量的文档,并返回剩余的文档。
7. $unwind:用于展开数组属性,将数组属性的每个元素转换为一个单独的文档。
- 使用管道聚合,可以将以上操作有机地组合在一起,以实现各种复杂的聚合查询需求。
- 此外,MongoDB 还提供了许多其他的聚合管道操作,可以根据具体场景自由组合使用,方便用户进行数据处理和分析。
4、注意:
参与聚合的字段类型必须是:
- keyword
- 数值
- 日期
- 布尔
三、使用DSL实现聚合
聚合所必须的三要素:
- 聚合名称
- 聚合类型
- 聚合字段
聚合可配置属性:
- size:指定聚合结果数量
- order:指定聚合结果排序方式f
- ield:指定聚合字段
1、桶聚合
GET /hotel/_search
{
"size": 0, //?设置size为0,结果中不包含文档,只包含聚合结果
"aggs": { //?定义聚合
"brandagg": { //给聚合起个名字
"terms": { //?聚合的类型,按照品牌值聚合,所以选择term
"field": "brand", //?参与聚合的字段
"size": 20 //?希望获取的聚合结果数量
}
}
}
}
运行后,数据被按照品牌(brand)划分了

(1)自定义排序规则

(2)限定聚合范围

2、度量聚合
在分类的同时,进行了分数的计算,并且按照平均分做降序

GET /hotel/_search
{
"size": 0,
"aggs": {
"brandagg": {
"terms": {
"field": "brand",
"size": 20,
"order": {
"scoreAgg.avg": "desc"
}
},
"aggs": {
"scoreAgg": {
"stats": {
"field": "score"
}
}
}
}
}
}四、使用RestAPI实现聚合
1、对品牌进行聚合

@Test
void testAggregation() throws IOException {
// 准备请求对象
SearchRequest request = new SearchRequest();
// 初始化 SearchSourceBuilder
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 设置 size
sourceBuilder.size(0);
// 聚合
sourceBuilder.aggregation(AggregationBuilders
.terms("brandAgg")
.field("brand")
.size(10)
);
// 将 SearchSourceBuilder 设置到 SearchRequest 中
request.source(sourceBuilder);
// 发出请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 解析结果
Aggregations aggregations = response.getAggregations();
// 根据聚合名称获取聚合结果
Terms brandTerms = aggregations.get("brandAgg");
// 获取桶
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
// 遍历
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
System.out.println(key);
}
}成功提取出品牌名
2、对品牌、城市、星级进行聚合
1、在service中添加方法

Map<String , List<String>> filters() throws IOException;2、在实现类中编写聚合方法
@Override
public Map<String, List<String>> filters() throws IOException {
// 准备请求对象
SearchRequest request = new SearchRequest();
// 初始化 SearchSourceBuilder
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 设置 size
sourceBuilder.size(0);
// 聚合
buildAggs(sourceBuilder);
// 将 SearchSourceBuilder 设置到 SearchRequest 中
request.source(sourceBuilder);
// 发出请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 解析结果
HashMap<String, List<String>> result = new HashMap<>();
Aggregations aggregations = response.getAggregations();
// 根据名称,获得结果
List<String> brandList = getAggByName(aggregations,"brandAgg");
result.put("品牌",brandList);
List<String> cityList = getAggByName(aggregations,"cityAgg");
result.put("城市",cityList);
List<String> starList = getAggByName(aggregations,"starAgg");
result.put("星级",starList);
return result;
}
private List<String> getAggByName(Aggregations aggregations,String aggName) {
// 根据聚合名称获取聚合结果
Terms brandTerms = aggregations.get(aggName);
// 获取桶
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
// 遍历
List<String > brandList = new ArrayList<>();
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
brandList.add(key);
}
return brandList;
}
private void buildAggs(SearchSourceBuilder sourceBuilder) {
sourceBuilder.aggregation(AggregationBuilders
.terms("brandAgg")
.field("brand")
.size(100)
);
sourceBuilder.aggregation(AggregationBuilders
.terms("cityAgg")
.field("city")
.size(100)
);
sourceBuilder.aggregation(AggregationBuilders
.terms("starAgg")
.field("starName")
.size(100)
);
}3、运行测试

3、与前端进行对接
1、增加controller方法
@PostMapping("filters")
public Map<String , List<String >> getFilters(@RequestBody RequestParams params){
return service.filters(params);
}2、更改service方法
Map<String , List<String>> filters(RequestParams params);3、更改实现类方法

@Override
public Map<String, List<String>> filters(RequestParams params) {
try {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
buildBasicQuery(params, request);
// 2.2.设置size
request.source().size(0);
// 2.3.聚合
buildAggs(request);
// 3.发出请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析结果
Map<String, List<String>> result = new HashMap<>();
Aggregations aggregations = response.getAggregations();
// 4.1.根据品牌名称,获取品牌结果
List<String> brandList = getAggByName(aggregations, "brandAgg");
result.put("brand", brandList);
// 4.2.根据品牌名称,获取品牌结果
List<String> cityList = getAggByName(aggregations, "cityAgg");
result.put("city", cityList);
// 4.3.根据品牌名称,获取品牌结果
List<String> starList = getAggByName(aggregations, "starAgg");
result.put("starName", starList);
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}4、运行测试

五、拼音分词器
1、将py插件复制到此目录
/var/lib/docker/volumes/es-plugins/_data/
2、重启es
docker restart es
3、测试
POST /_analyze
{
"text": ["西巴仙人爱桃树"],
"analyzer": "pinyin"
}把每个字都拆成了拼音

六、自定义分词器
elasticsearch中分词器(analyzer)的组成包含三部分:
lcharacter filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
ltokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
ltokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
// 自定义拼音分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
}
}1、自动补全字段
- elasticsearch提供了Completion Suggester查询来实现自动补全功能。
- 这个查询会匹配以用户输入内容开头的词条并返回。
为了提高补全查询的效率,对于文档中字段的类型有一些约束:
- 参与补全查询的字段必须是completion类型。
- 字段的内容一般是用来补全的多个词条形成的数组。
语法:
//?自动补全查询
GET?/test/_search
{
??"suggest":?{
????"title_suggest":?{
??????"text":?"s",?//?关键字
??????"completion":?{
????????"field":?"title",?//?补全查询的字段
????????"skip_duplicates":?true,?//?跳过重复的
????????"size":?10?//?获取前10条结果
??????}
????}
??}
}
七、实现自动补全功能
1、删除原索引库
DELETE /hotel2、新建索引库
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}3、修改HotelDoc类,增加suggestion属性
private List<String> suggestion;this.suggestion = Arrays.asList(this.brand,this.business);
4、重新做批处理
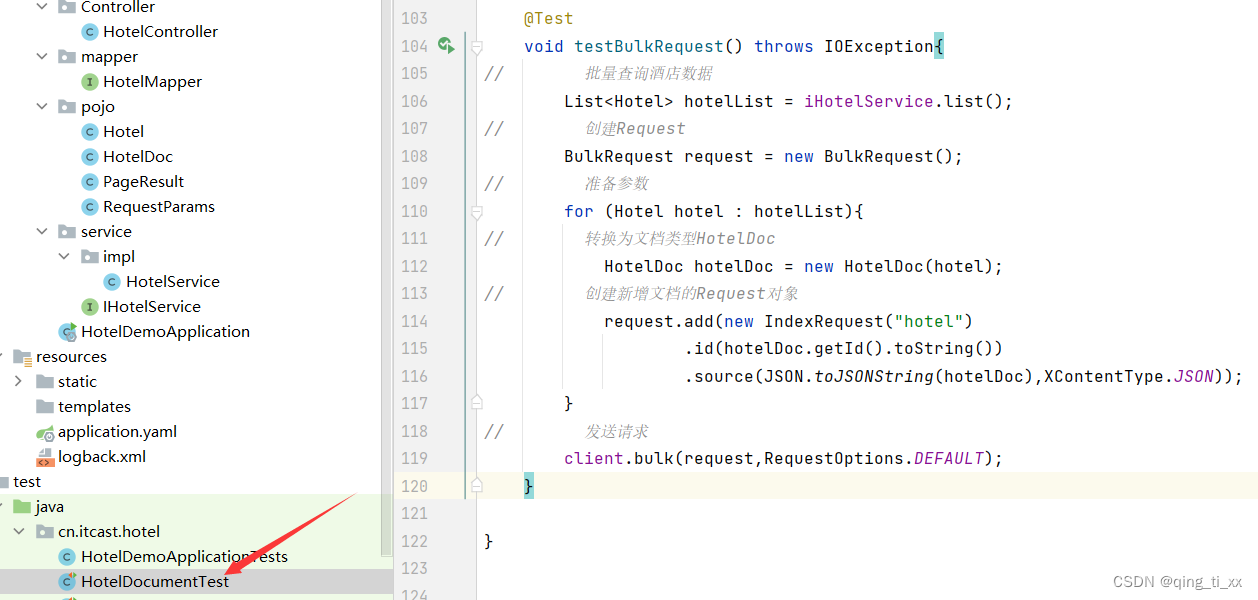
@Test
void testBulkRequest() throws IOException{
// 批量查询酒店数据
List<Hotel> hotelList = iHotelService.list();
// 创建Request
BulkRequest request = new BulkRequest();
// 准备参数
for (Hotel hotel : hotelList){
// 转换为文档类型HotelDoc
HotelDoc hotelDoc = new HotelDoc(hotel);
// 创建新增文档的Request对象
request.add(new IndexRequest("hotel")
.id(hotelDoc.getId().toString())
.source(JSON.toJSONString(hotelDoc),XContentType.JSON));
}
// 发送请求
client.bulk(request,RequestOptions.DEFAULT);
}
5、词条做切割处理,修改HotelDoc类
// 有多个值,做切割
String[] arr = this.business.split("/");
this.suggestion = new ArrayList<>();
this.suggestion.add(this.brand);
Collections.addAll(this.suggestion,arr);
}else {
this.suggestion = Arrays.asList(this.brand,this.business);
}
6、编写RestAPI
@Test
void testSuggest() throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source().suggest(new SuggestBuilder().addSuggestion(
"suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix("h")
.skipDuplicates(true)
.size(10)
));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
Suggest suggest = response.getSuggest();
CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");
List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();
for (CompletionSuggestion.Entry.Option option : options) {
String string = option.getText().toString();
System.out.println(string);
}
}
7、实现搜索框的输入补全
1、在controller中新增方法
@PostMapping("suggestion")
public List<String> getSuggestion(@RequestParam("key") String prefix){
return service.getSuggestions(prefix);
}
2、在service中新建方法
List<String> getSuggestions(String prefix);
3、实现方法
@Override
public List<String> getSuggestions(String prefix) {
try {
// 准备Request
SearchRequest request = new SearchRequest("hotel");
request.source().suggest(new SuggestBuilder().addSuggestion(
"suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix(prefix)
.skipDuplicates(true)
.size(10)
));
// 发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 得到响应
Suggest suggest = response.getSuggest();
CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");
List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();
ArrayList<String> list = new ArrayList<>(options.size());
// 遍历
for (CompletionSuggestion.Entry.Option option : options) {
String string = option.getText().toString();
list.add(string);
}
return list;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
8、测试
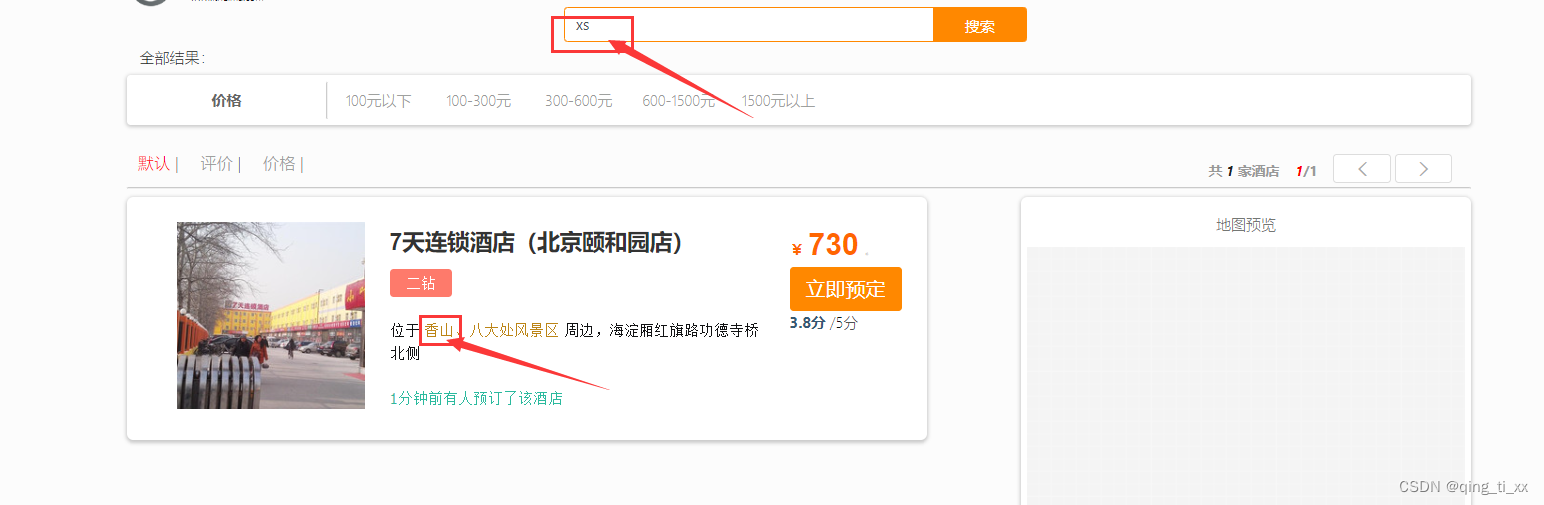
八、数据同步
1、定义:
- 数据同步是指将一个数据源的数据与另一个数据存储系统中的数据保持更新的过程。
- 数据同步确保不同数据存储系统中的数据保持一致,从而支持企业在不同数据存储系统中的数据共享和协作。
2、特点:
数据同步是一个周期性的过程。数据同步通常需要从源系统读取数据,然后将数据传递到目标系统。这个过程可能需要经过多个步骤,如数据转换、数据清洗、数据映射等。一般情况下,数据同步是一个周期性的过程,定期将目标系统中的数据更新到最新状态。
数据同步的目标是确保数据的一致性。在数据同步的过程中,目标是确保源系统中的数据与目标系统中的数据保持一致。这样可以保证不同应用之间使用相同的数据。
数据同步需要考虑数据的安全性和完整性。在数据同步的过程中,数据的安全性和完整性必须得到保障。例如,在数据传输过程中,需要使用加密技术来保护敏感数据的机密性。
数据同步通常需要使用专业工具或平台。数据同步的过程需要使用专业工具或平台来完成。这些工具或平台通常提供了丰富的功能和技术,如数据清洗、数据转换、数据映射等,以确保数据同步的质量和效率。
数据同步可以提高企业效率和降低成本。通过数据同步,企业可以在不同部门和团队之间共享数据,从而更好地理解业务趋势和市场需求,进一步提高效率和降低成本。
3、数据同步方案
(1)同步调用

优点:
实现简单
缺点:
粗暴业务耦合度高
(2)异步通知

优点:
低耦合,实现难度一般依赖
缺点:
mq的可靠性
(3)监听binlog
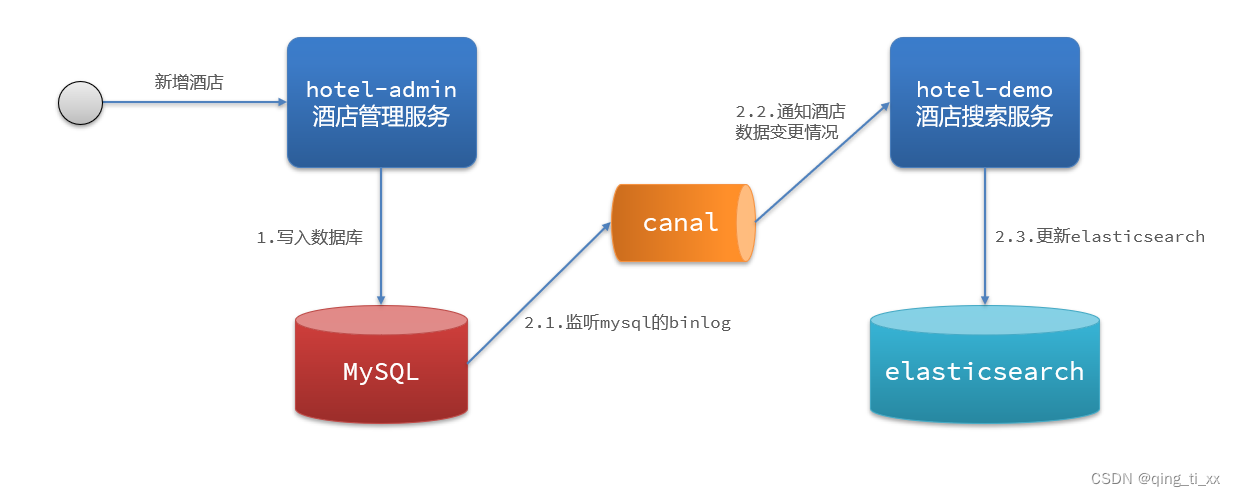
优点:
完全解除服务间耦合
缺点:
开启binlog增加数据库负担、实现复杂度高
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!