sparksql介绍
1.1 SparkSQL介绍
SparkSQL,顾名思义,就是Spark生态体系中的构建在SparkCore基础之上的一个基于SQL的计算模块。 ? SparkSQL的前身不叫SparkSQL,而叫Shark,最开始的时候底层代码优化,sql的解析、执行引擎等等完全基于Hive,总是Shark的执行速度要比Hive高出一个数量级,但是hive的发展制约了Shark,所以在15年中旬的时候,Shark负责人,将Shark项目结束掉,重新独立出来的一个项目,就是SparkSQL,不在依赖Hive,做了独立的发展,逐渐的形成两条互相独立的业务:SparkSQL和Hive-On-Spark。在SparkSQL发展过程中,同时也吸收了Shark有些的特点:基于内存的列存储,动态字节码优化技术。
1.1.1 SparkSQL概述
Spark SQL是用于结构化数据处理的Spark模块。与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了有关数据结构和正在执行的计算的更多信息。在内部,Spark SQL使用这些额外的信息来执行额外的优化。有几种与Spark SQL交互的方法,包括SQL和Dataset API。计算结果时,将使用相同的执行引擎,这与用于表示计算的API/语言无关。这种统一意味着开发人员可以轻松地在不同的API之间来回切换,基于API的切换提供了表示给定转换的最自然的方式。
1.1.2 SparkSQL特点
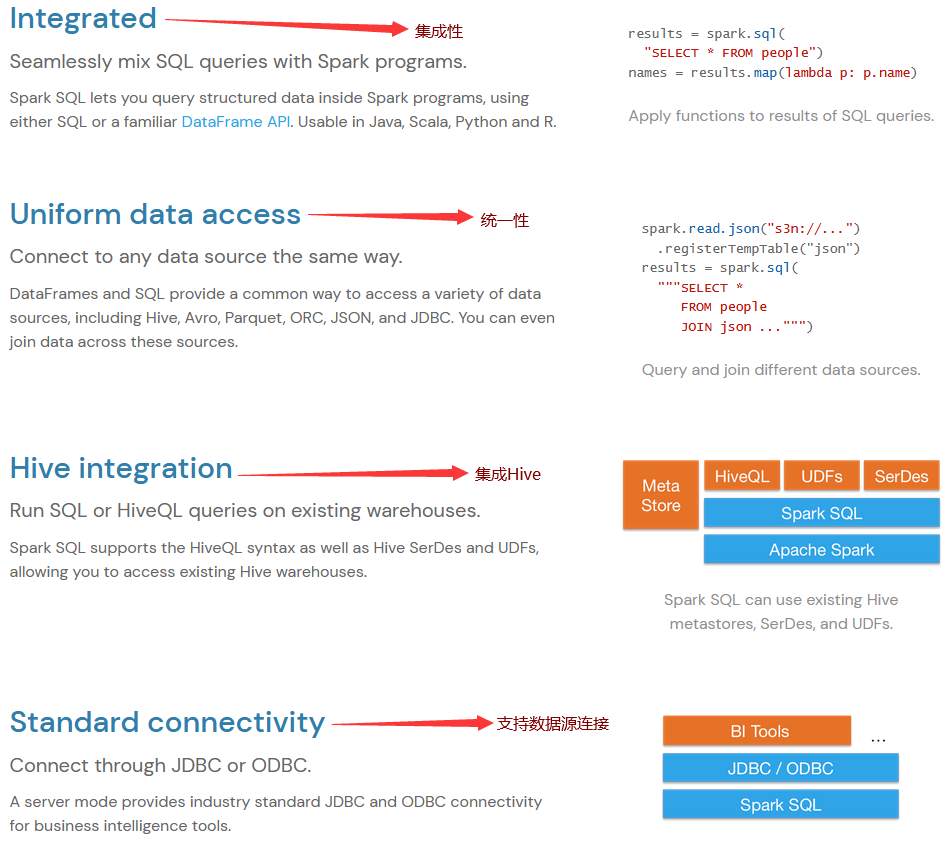
1.1.3 总结
SparkSQL就是Spark生态体系中用于处理结构化数据的一个模块。
-
结构化数据是什么?
-
存储在关系型数据库中的数据,就是结构化数据.
-
半结构化数据是什么?
-
类似xml、json等的格式的数据被称之为半结构化数据.
-
非结构化数据是什么?
-
音频、视频、图片等为非结构化数据.
换句话说,SparkSQL处理的就是二维表数据。sparksql引申:
Spark SQL是Apache Spark的一个模块,用于处理结构化数据的分布式计算引擎。它提供了一个用于处理大规模数据的统一的数据访问接口,支持SQL查询、DataFrame和Dataset API。Spark SQL具有高性能、易用性和灵活性,可以用于数据分析、数据挖掘、机器学习等多种场景。
Spark SQL的核心是Catalyst优化器,它能够对SQL查询进行优化,提高查询性能。Catalyst优化器使用了一系列的规则和优化技术,包括谓词下推、投影消除、列剪裁等,以及逻辑优化、物理优化和执行优化。通过这些优化技术,Spark SQL可以在处理大规模数据时提供高性能的查询处理能力。
Spark SQL支持多种数据源,包括Hive、HBase、Parquet、JSON、CSV等,可以方便地与其他数据存储系统集成。它还提供了丰富的内置函数和UDF(用户自定义函数)支持,可以方便地进行数据处理和计算。
除了支持SQL查询外,Spark SQL还引入了DataFrame和Dataset API,这两个API提供了更加灵活和高效的数据操作方式。DataFrame是一种类似于关系型数据库表的数据结构,可以进行类似于SQL的操作,如过滤、聚合、排序等。而Dataset是DataFrame的扩展,它提供了类型安全的数据操作方式,可以在编译时进行类型检查,避免在运行时出现类型错误。
Spark SQL还提供了丰富的集成功能,可以与Spark的其他模块(如Spark Streaming、Spark MLlib等)无缝集成,支持流处理、机器学习等多种应用场景。同时,它还支持与第三方工具(如Tableau、PowerBI等)的集成,可以方便地将Spark SQL的查询结果可视化展示。
总的来说,Spark SQL是一个功能强大、性能高效、易用灵活的分布式计算引擎,可以满足大规模数据处理的需求,支持多种数据源和多种数据操作方式,是大数据处理和分析的理想选择。随着Spark生态系统的不断完善和发展,Spark SQL将会在大数据领域发挥越来越重要的作用。
Guff_hys_python数据结构,大数据开发学习,python实训项目-CSDN博客
| ?SparkSQL概述 |
| SparkSQL特点 |
| 总结 |
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!