Python(六)—— 自定义模块
15. 自定义模块
15.1 模块的定义与分类
15.1.1 模块的定义
一个函数封装一个功能,当遇到众多函数时,将这些相同的功能封装到一个文件中,那么这个存储着很多常用的功能的py文件,就是模块。模块就是文件,存放一堆常用的函数,就是一系列常用功能的集合体
1、为什么要使用模块
① 从文件级别组织程序,更方便管理。随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。这时我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现了功能的重复利用
②拿来主义,提升开发效率。同样的原理,我们也可以下载别人写好的模块,然后导入到自己的项目中使用,这种拿来主义,可以极大地提升我们的开发效率,避免重复造轮子
2、什么是脚本
如果你退出Python解释器然后重新进入,那么你之前定义的函数或者变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过python test.py方式去执行,此时test.py被称为脚本Script,所以,脚本就是一个Python文件
15.1.2 模块的分类
Python语言中,模块分为三类
-
第一类:内置模块,也叫做标准库。此类模块就是Python解释器给你提供的,比如我们之前见过的time模块,os模块等。标准库的模块非常多(200多个,每个模块又有很多功能)
-
第二类:第三方模块,第三方库。一些Python大神写的非常好用的模块,必须通过pip install 指令安装的模块,比如BeautfulSoup,Django等等(大概有6000多个)
-
第三类:自定义模块。我们自己在项目中定义的一些模块
15.1.3 自定义模块
定义一个模块其实很简单就是写一个文件,里面写一些代码(变量,函数)即可。此文件的名字为yuluo.py,文件内容如下:
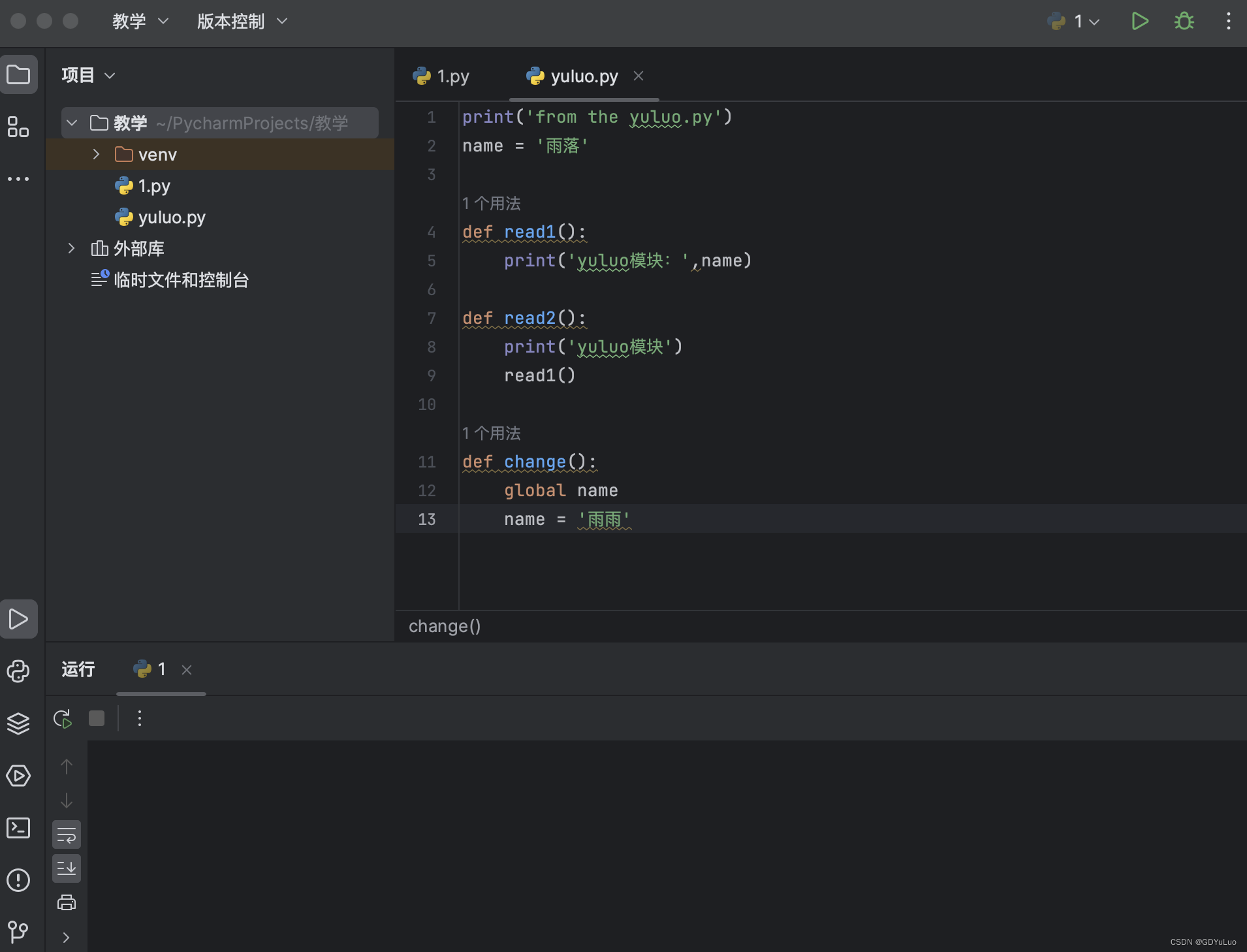
15.2 import
15.2.1 import的使用
import 翻译过来是一个导入的意思,模块可以包含可执行的语句和函数的定义,这些语句的目的是初始化模块,它们只在模块名第一次遇到导入import语句时才执行(import语句是可以在程序中的任意位置使用的,且针对同一个模块很import多次,为了防止你重复导入,Python的优化手段是:第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载到内存中的模块对象增加了一次引用,不会重新执行模块内的语句),例如:

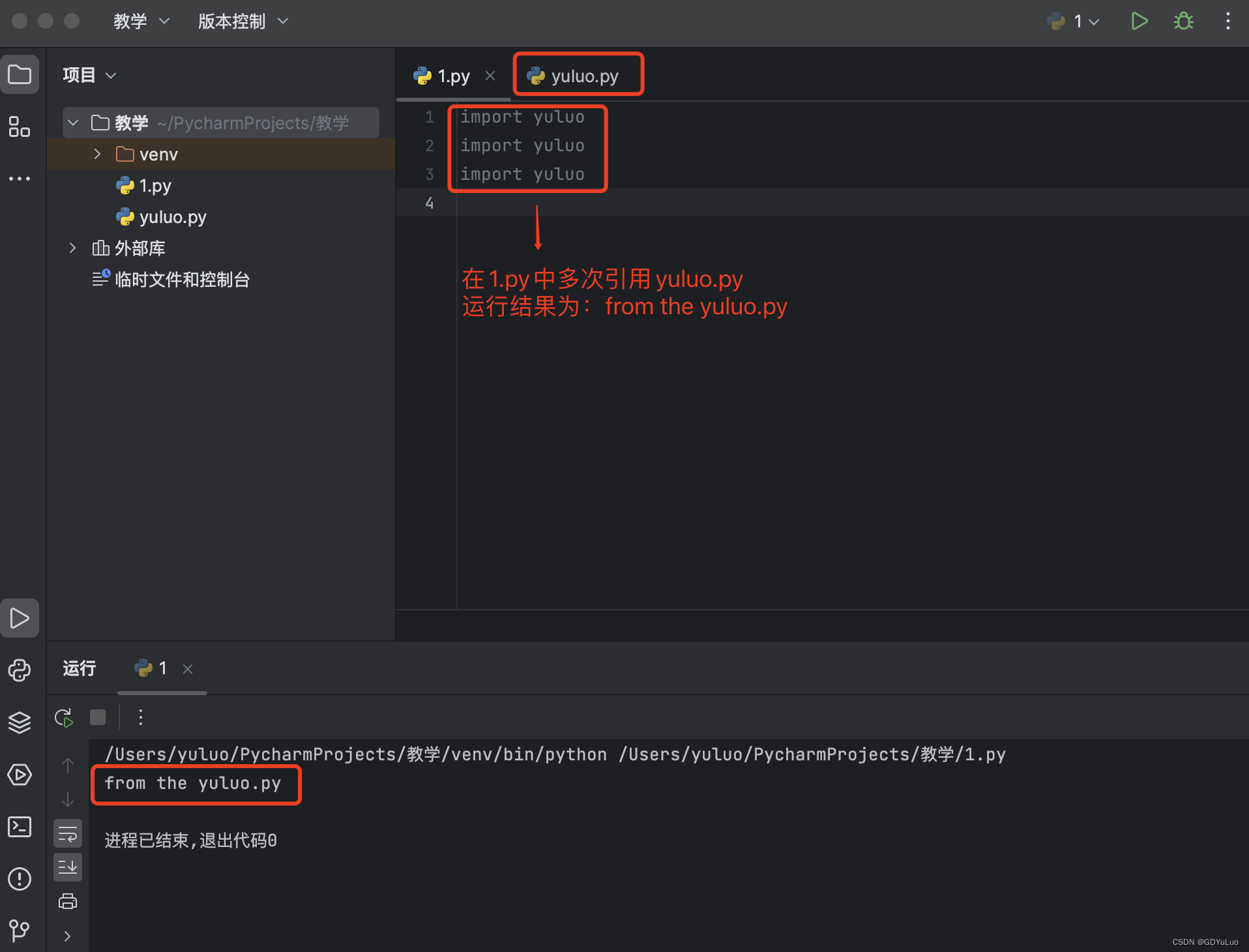
注意:只在首次导入时才执行yuluo.py内代码,此处的运行结果是只打印一次from the yuluo.py
15.2.2 初次导入模块执行三件事
1、创建一个以模块名命名的名称空间
2、执行这个名称空间(即导入的模块)里面的代码
3、通过此模块名. 的方式引用该模块里面的内容(变量,函数名,类名等),这个名字和变量名没什么区别,都是第一类的,且使用 yuluo.名字的方式可以访问yuluo.py文件中定义的名字
注意:重复导入会直接引用内存中已经加载好的结果
15.2.3 被导入模块有独立的名称空间
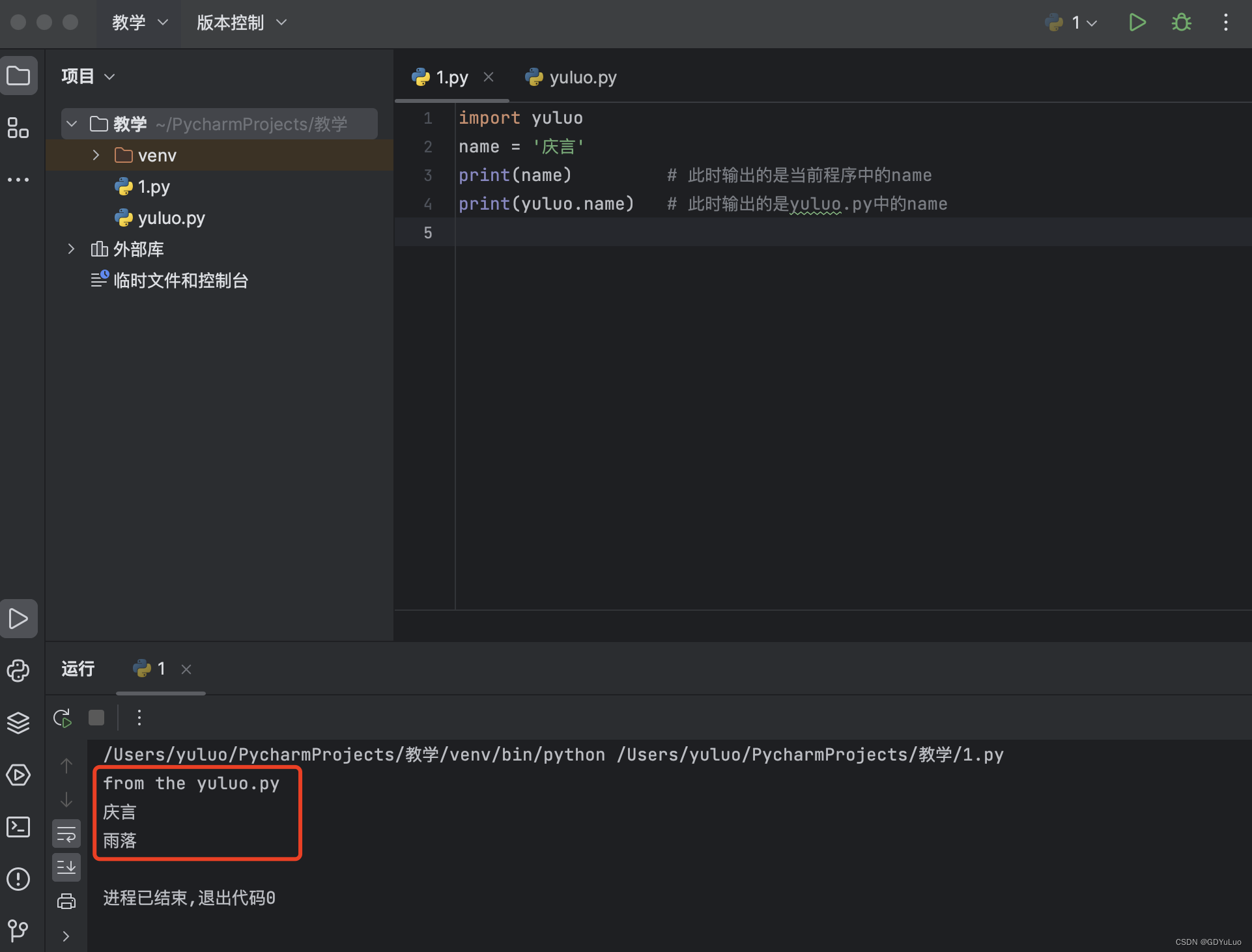
每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时,就不用担心我们定义在自己模块中全局变量会在被导入时,与使用者的全局变量冲突,例如我们写好一个yuluo.py文件,再在1.py中导入这个yuluo.py

1、此时我们打印name,会优先查找当前文件中的name;如果想打印yuluo.py中的name,得用yuluo.name
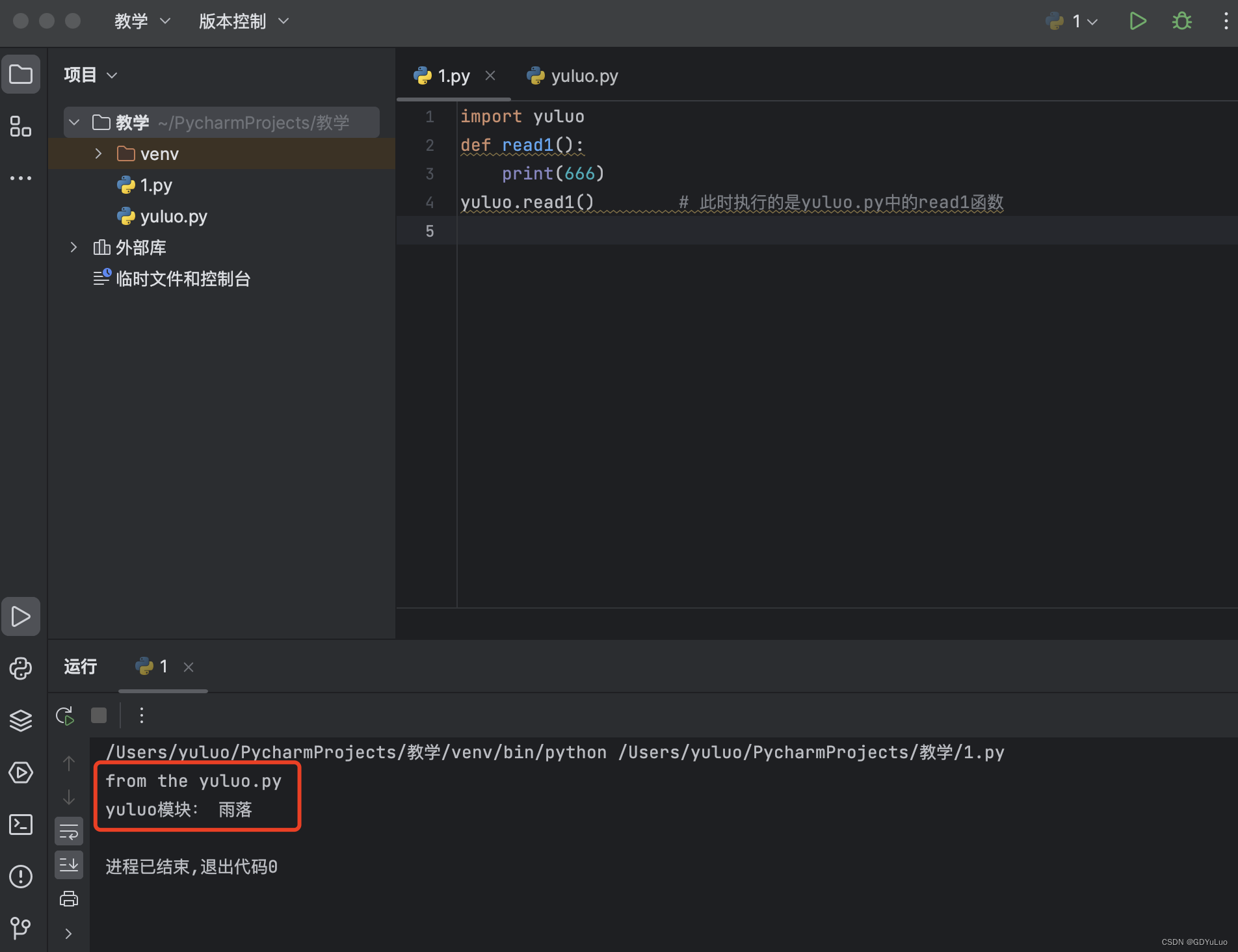
2、我们在1.py中也写一个read1函数,当我们执行yuluo.py中的read1函数,即使函数名相同,也不会引起冲突
3、在1.py中执行yuluo.py中的change函数,此时yuluo.py中的全局变量name="雨落"被修改为name="雨雨"

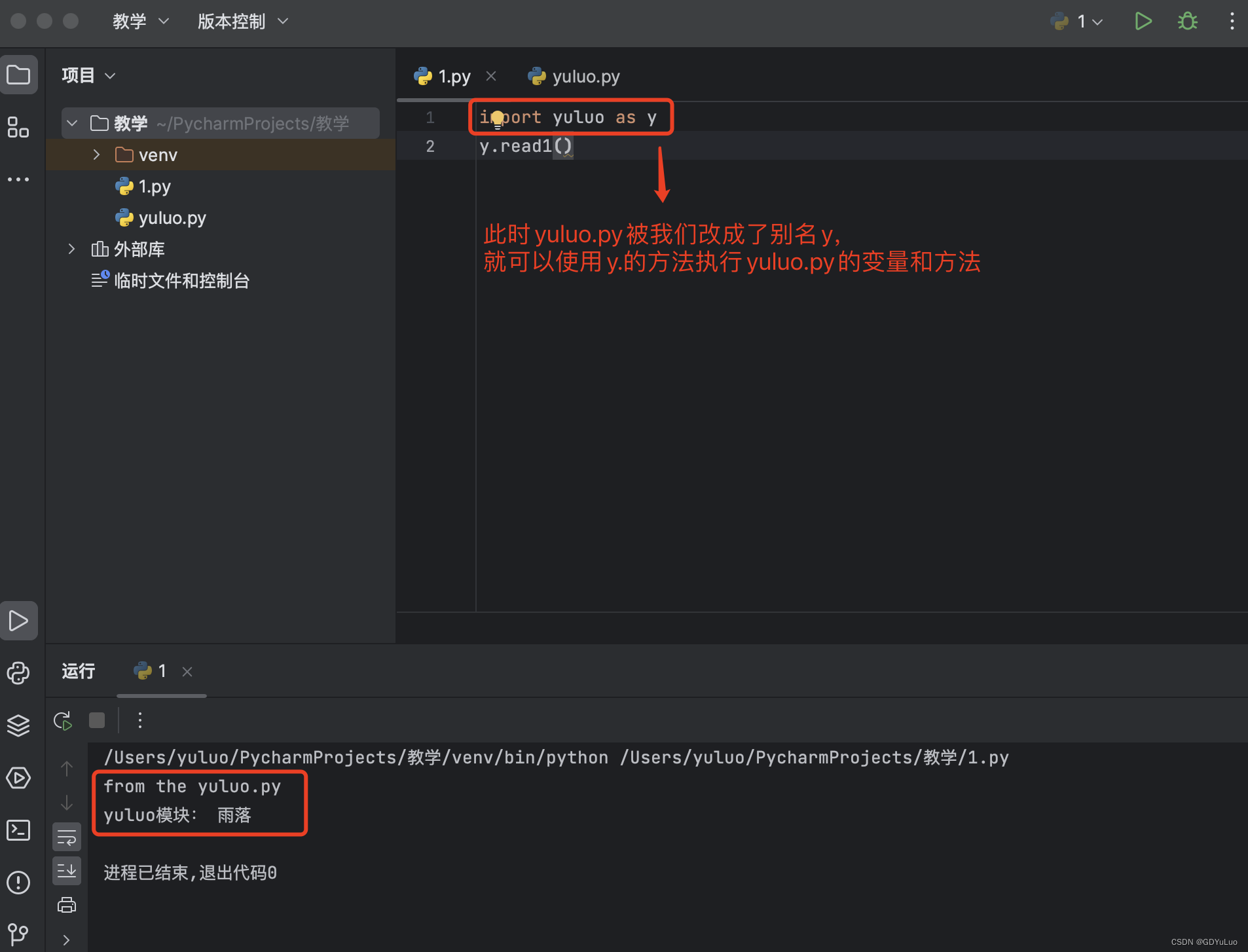
15.2.4 为模块起别名
别名也就是函数的“外号”,主要由两大优点:
1、优点一:可以将很长的模块名改成很短,方便使用
2、优点二:有利于代码的扩展和优化。例如我们重新建立两个py文件,写入以下代码


此时我们在1.py文件中,根据我们输入不同的db_type内容,引入不同的py文件作为db,例如此处我输入的是mysql,会将mysql.py作为别名db引入到1.py文件中,执行相应的sqlparse方法

15.2.5 导入多个模块
我们以后再开发过程中,免不了会在一个文件中,导入多个模块,推荐写法是一个一个导入
"""--- 这样写可以但是不推荐 ---"""
import os,sys,json"""--- 推荐写法 ---"""
import os
import sys
import json
# 多行导入:易于阅读 易于编辑 易于搜索 易于维护15.3 from ... import ...
15.3.1 from ... import ...的使用
from ... import ... 的使用示例
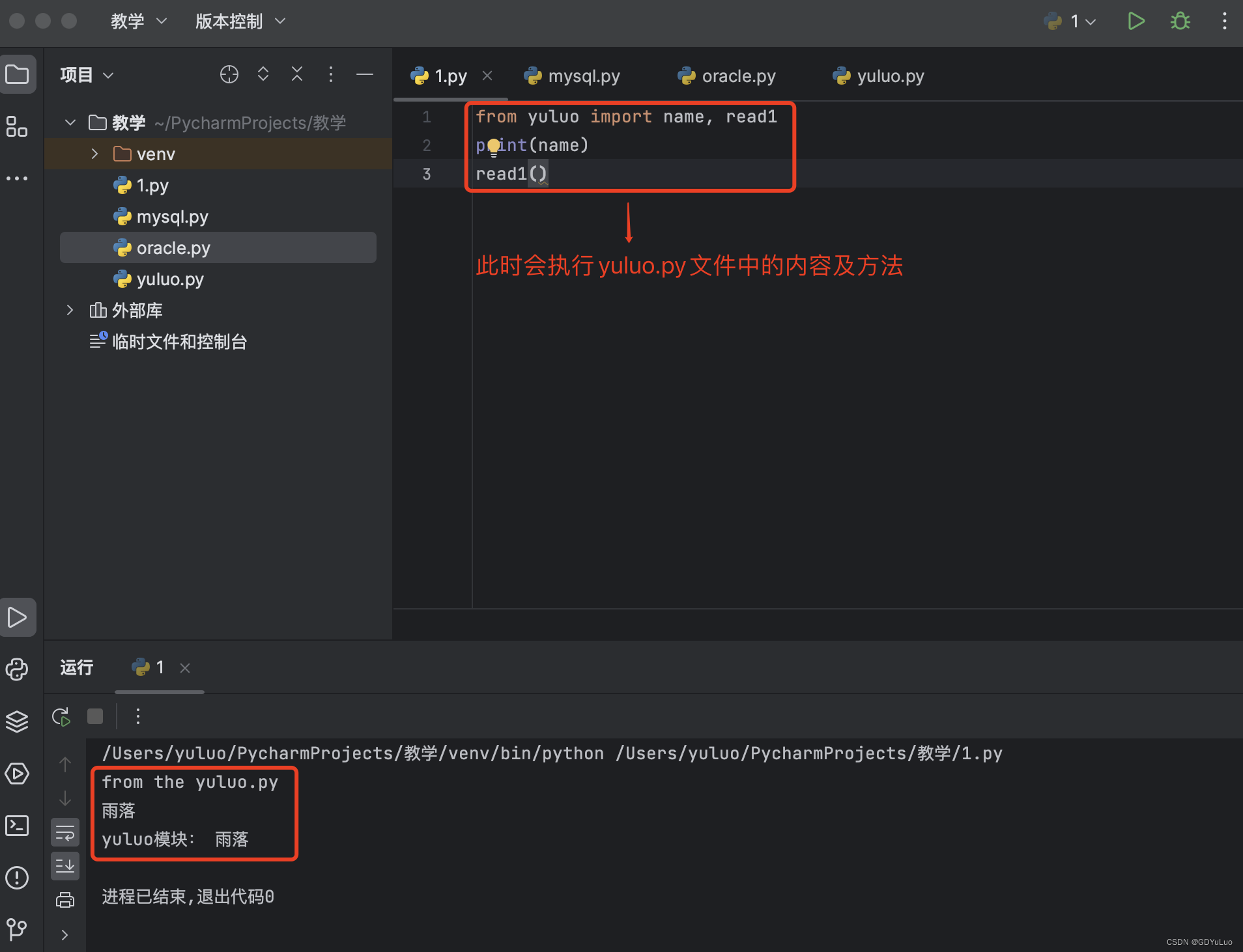
15.3.2 from ... import ...与import
唯一的区别就是:使用from...import...则是将spam中的名字直接导入到当前的名称空间中,所以在当前名称空间中,直接使用名字就可以了,无需加前缀 yuluo.
1、执行文件有与模块同名的变量或者函数名,写在后面的会有覆盖前者的效果

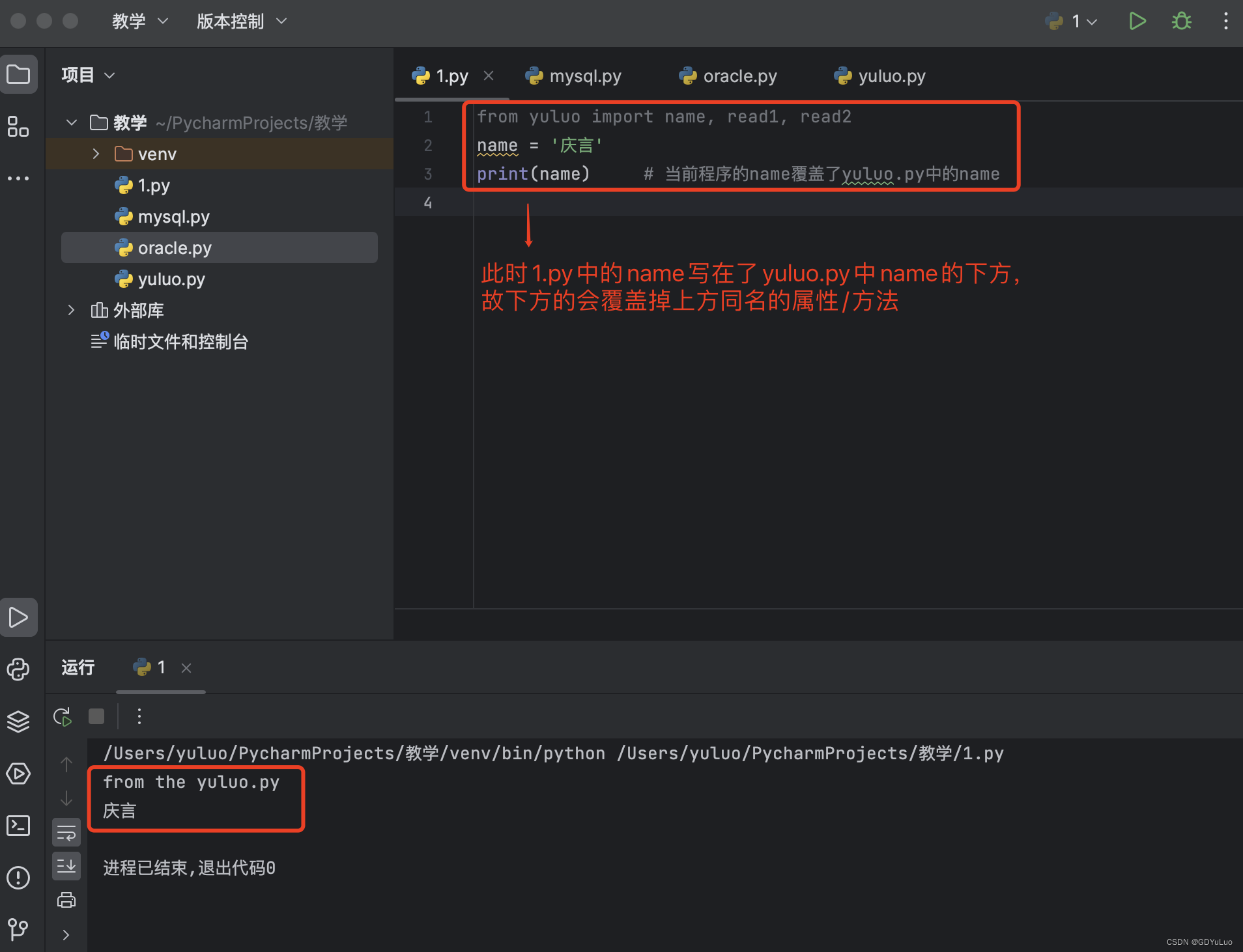
2、当前位置直接使用read1和read2就好了,执行时,仍然以yuluo.py文件全局名称空间
总结:from ... import ...相对于import
-
好处:使用起来方便了
-
坏处:容易与当前执行文件中的名字冲突
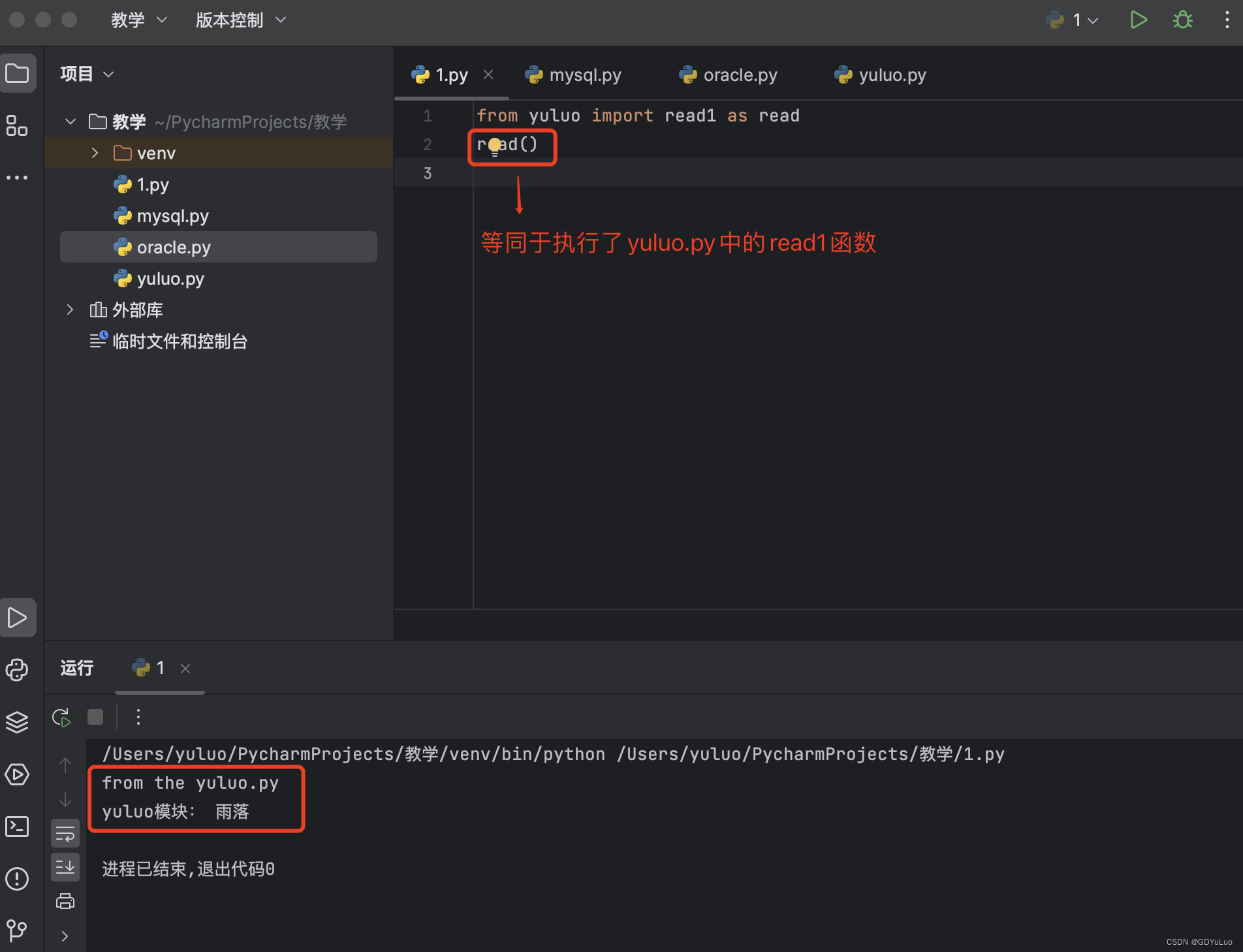
15.3.3 支持起别名
通过这种方式引用模块也可以对模块进行改名
15.3.4 支持一行导入多个
用法基本与import相似
from yuluo import read1,read2,name15.4 from ... import *
from spam import * 把yuluo中所有的不是以下划线开头的名字都导入到当前位置,大部分情况下我们的Python程序不应该使用这种导入方式,因为?* 你不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字。而且可读性极差,在交互式环境中导入时没有问题
可以使用__all__来控制*,在yuluo.py中新增一行
__all__=['money','read1']
# 这样在另外一个文件中用from spam import * 就这能导入列表中规定的两个名字----? 格式待完善,明天再更 ----?
15.5 模块循环导入问题
-
模块循环/嵌套导入抛出异常的根本原因是由于在Python中模块被导入一次之后,就不会重新导入,只会在第一次导入时执行模块内代码
-
在我们的项目中应该尽量避免出现循环/嵌套导入,如果出现多个模块都需要共享的数据,可以将共享的数据集中存放到某一个地方在程序出现了循环/嵌套导入后的异常分析、解决方法如下(了解,以后尽量避免)
-
错误示范:先创建3个py文件,并分别运行,结果和报错原因如下:
# 创建一个m1.py print('正在导入m1') from m2 import y ? x='m1' ? -------------------------- ? # 创建一个m2.py print('正在导入m2') from m1 import x ? y='m2' ? -------------------------- ? # 创建一个run.py import m1# 测试一:执行run.py会抛出异常 # 运行结果: 正在导入m1 正在导入m2 ImportError: cannot import name 'x' ? ? # 结果分析: 先执行run.py--->执行import m1,开始导入m1并运行其内部代码--->打印内容"正在导入m1"--->执行from m2 import y 开始导入m2并运行其内部代码--->打印内容“正在导入m2”--->执行from m1 import x,由于m1已经被导入过了,所以不会重新导入,所以直接去m1中拿x,然而x此时并没有存在于m1中,所以报错# 测试一:直接执行m1.py抛出异常 # 运行结果: 正在导入m1 正在导入m2 正在导入m1 ImportError: cannot import name 'y' ? ? # 结果分析: 执行m1.py,打印“正在导入m1”,执行from m2 import y ,导入m2进而执行m2.py内部代码--->打印"正在导入m2",执行from m1 import x,此时m1是第一次被导入,执行m1.py并不等于导入了m1,于是开始导入m1并执行其内部代码--->打印"正在导入m1",执行from m1 import y,由于m1已经被导入过了,所以无需继续导入而直接问m2要y,然而y此时并没有存在于m2中所以报错-
解决方法如下:
----- 方法一 导入语句放到最后 ----- ? # m1.py print('正在导入m1') x='m1' from m2 import y ? ? # 此处的import语句放于最后 ? # m2.py print('正在导入m2') y='m2' from m1 import x ? ? # 此处的import语句放于最后 ? ----- 方法二 导入语句放到函数中----- ? # m1.py print('正在导入m1') def f1(): ? ?from m2 import y ? ?print(x,y) x = 'm1' ? # m2.py print('正在导入m2') def f2(): ? ?from m1 import x ? ?print(x,y) y = 'm2' ? # run.py import m1 m1.f1() -
15.6 py文件的两种功能
-
编写好的一个python文件可以有两种用途:
-
一:脚本,一个文件就是整个程序,用来被执行(比如你之前写的模拟博客园登录那个作业等)
-
二:模块,文件中存放着一堆功能,用来被导入使用
-
-
python为我们内置了全局变量
__name__-
当文件被当做脚本执行时:
__name__ == __main__ -
当文件被当做模块导入时:
__name__ == 模块名 -
作用:用来控制
.py文件在不同的应用场景下执行不同的逻辑(或者是在模块文件中测试代码)
print('from the tbjx.py') __all__ = ['name', 'read1'] ? ?# 利用__all__来控制py文件中导入可使用的名字 name = '太白金星' ? -------------------------- ? def read1(): ? print('tbjx模块:',name) ? def read2(): ? print('tbjx模块') ? read1() ? def change(): ? ? global name ? name = 'barry' ? if __name__ == '__main__': ? ? # 在模块文件中测试read1()函数 ? # 此模块被导入时 __name__ == tbjx 所以不执行 ? read1() -
15.7 模块的搜索路径
-
当你引用一个模块时,不见得每次都可以import到,引用模块也是按照一定规则进行引用的
上面的示例可以得知,引用模块也是按照一定规则进行引用的。
-
Python中引用模块是按照一定的规则以及顺序去寻找的,这个查询顺序为:先从内存中已经加载的模块进行,寻找找不到再从内置模块中寻找,内置模块如果也没有,最后去sys.path中路径包含的模块中寻找
-
它只会按照这个顺序从这些指定的地方去寻找,如果最终都没有找到,那么就会报错
-
内存中已经加载的模块->内置模块->sys.path路径中包含的模块
-
1、在第一次导入某个模块时(比如tbjx),会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用(ps:python解释器在启动时会自动加载一些模块到内存中,可以使用sys.modules查看)
-
2、如果没有,解释器则会查找同名的内置模块
-
3、如果还没有找到就从sys.path给出的目录列表中依次寻找tbjx.py文件
-
-
需要特别注意的是:我们自定义的模块名不应该与系统内置模块重名
# 在初始化后,python程序可以修改sys.path,路径放到前面的优先于标准库被加载 ? > > > import sys > > > sys.path.append('/a/b/c/d') > > > sys.path.insert(0,'/x/y/z') #排在前的目录,优先被搜索 > > > 注意:搜索时按照sys.path中从左到右的顺序查找,位于前的优先被查找,sys.path中还可能包含.zip归档文件和.egg文件,python会把.zip归档文件当成一个目录去处理, ? # 首先制作归档文件:zip module.zip foo.py bar.py import sys sys.path.append('module.zip') import foo,bar ? # 也可以使用zip中目录结构的具体位置 sys.path.append('module.zip/lib/python') ? # windows下的路径不加r开头,会语法错误 sys.path.insert(0,r'C:\Users\Administrator\PycharmProjects\a') ? # 至于.egg文件是由setuptools创建的包,这是按照第三方python库和扩展时使用的一种常见格式,.egg文件实际上只是添加了额外元数据(如版本号,依赖项等)的.zip文件。 ? # 需要强调的一点是:只能从.zip文件中导入.py,.pyc等文件。使用C编写的共享库和扩展块无法直接从.zip文件中加载(此时setuptools等打包系统有时能提供一种规避方法),且从.zip中加载文件不会创建.pyc或者.pyo文件,因此一定要事先创建他们,来避免加载模块是性能下降
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!