数据结构之优先级队列(堆)及top-k问题讲解
?💕"哪里会有人喜欢孤独,不过是不喜欢失望。"💕
作者:Mylvzi?
?
文章主要内容:数据结构之优先级队列(堆)?
?

一.优先级队列
1.概念
? 我们已经学习过队列,队列是一种先进先出(FIFO)的数据结构,但是在有些情况下,数据的进出是有优先级的,优先级高的往往需要先"出",优先级低的就需要后"出",此时普通的队列就无法完成这样的操作(也就是数据在插入到队列中后,还需要根据优先级进行位置调整),需要另外一种数据结构--优先级队列?PriorityQueue来实现
? 在实际生活中PriorityQueue的场景经常存在,比如你在打游戏的时候,如果有来电,系统应该优先处理来电。
? 在这种场景下,数据结构需要实现两个最基本的操作"返回优先级最高的对象"和"添加新的数据"
二.优先级队列的模拟实现
? jdk1.8中的PriorityQueue 底层就使用了"堆"这种数据结构,堆实际上就是经过优先级调整的完全二叉树
注:这里的优先级在堆中的体现一般是所存储数据的大小?
1.什么是堆?
? 堆是一种把元素按大小排列的完全二叉树,堆就是进行数据高效组织的另一种形式
从小到大排列:小根堆(每棵树的根节点的值比当前树的所有孩子都小)
从大到小排列:大根堆(每棵树的根节点的值比当前树的所有孩子都大)
大根堆示例:
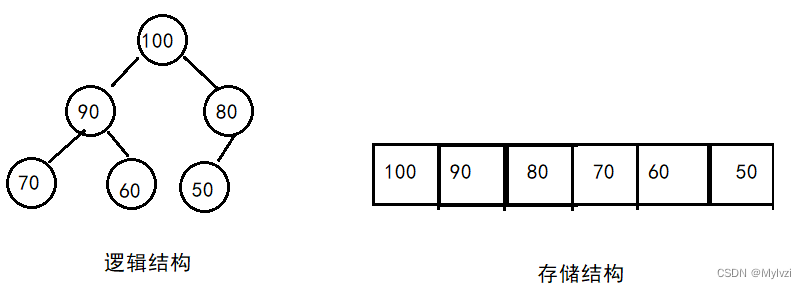
小根堆示例: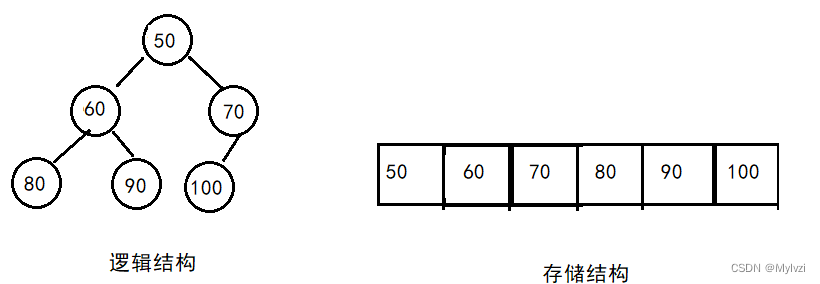 ?
?
2.堆的存储方式
? 堆其实是一颗完全二叉树,那么在存储的时候就可以使用顺序表进行数据的存储;而对于非完全二叉树来说,则不适合使用顺序表存储数据,因为会导致空间资源的浪费
? 既然是一颗完全二叉树,那就具有完全二叉树的一些性质
- 如果i为0,则i对应的结点是根节点;i的父节点的下标为(i-1)/2
- 由父节点的下标i可得左孩子的下标:2*i+1,右孩子的下标:2*i+2
3.堆的创建
一般都是根据数组去创建堆? 使数组中的元素在二叉树中排列时呈现某种顺序
对于集合{ 27,15,19,18,28,34,65,49,25,37 }中的数据,如果将其创建成堆呢?
观察集合,此时是无序的,我们需要通过调整将其设置为大根堆/小根堆
1.堆的实现
1.大根堆的实现
图解:
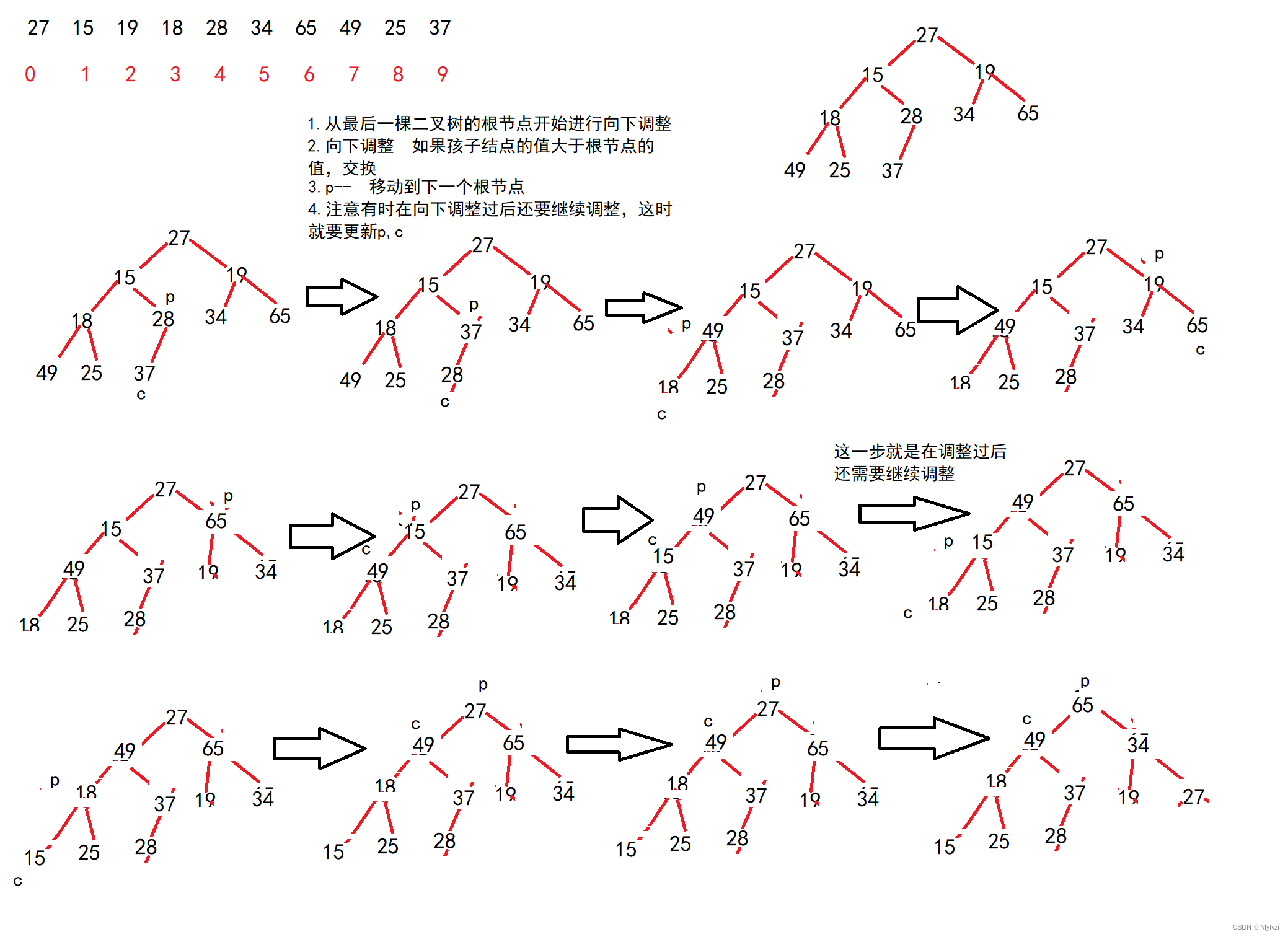
可见实现大根堆的核心思路在于"向下调整",对已有的数据进行向下调整,使其符合规定的顺序
向下调整的步骤:
- ?先获取到最后一棵子树的根节点的下标 parent = (usedSize - 1- 1)/2
- 获取到左右孩子结点的最大值(先获取左孩子,再判断左右孩子谁的值更大)
- 如果孩子节点的值>根节点的值,交换,交换之后需要堆parent重新赋值为child,继续向下调整
- 如果孩子节点的值<根节点的值,不交换,parent--;
对于2:为什么先获取左孩子的结点呢?因为对于一个完全二叉树来说,其最后一棵子树一定有左孩子,但是不一定有右孩子。
代码实现?
// 根据传入的数组 将他们调整为大根堆
public int[] elem;
public int usedSize;
public TestHeap(int size) {
this.elem = new int[size];
}
// 初始化堆
public void initHeap(int[] arr) {
for (int i = 0; i < arr.length; i++) {
this.elem[i] = arr[i];
this.usedSize++;
}
}
// 实现大根堆
/**
* 从最后一棵子树的根节点开始,进行向下调整,一直调整到root
*/
// 向下调整
public void createHeap() {
// 从最后一棵子树的根节点开始
for (int parents = (usedSize-1-1)/2; parents >= 0; parents--) {
shiftDown(parents,usedSize);
}
}
private void shiftDown(int parents, int usedSize) {
// 先获取左孩子的下标
int child = 2*parents + 1;
// 进行向下调整
while (child < usedSize) {
// 先判断左右孩子的值是谁更大
if(child+1 < usedSize && elem[child] < elem[child+1]) {
// 存在右孩子 且右孩子的值比左孩子的大
child++;
}
if(elem[child] > elem[parents]) {
// 如果孩子结点的值比根节点大 交换
swap(child,parents);
parents = child;
child = 2*parents + 1;
}else {
// 如果根节点就是最大值 直接翻一下
break;
}
}
}
// 交换函数
private void swap(int i, int j) {
int tmp = elem[i];
elem[i] = elem[j];
elem[j] = tmp;
}2.小根堆的实现
实现小根堆的逻辑是相同的,只需要在进行向下调整的时候改一下交换的逻辑
// 实现小根堆
public void createHeap2() {
// 从最后一棵子树的根节点开始
for (int parents = (usedSize-1-1)/2; parents >= 0; parents--) {
shiftDown(parents,usedSize);
}
}
private void shiftDown2(int parents, int usedSize) {
// 先获取左孩子的下标
int child = 2*parents + 1;
// 进行向下调整
while (child < usedSize) {
// 先判断左右孩子的值是谁更大
if(child+1 < usedSize && elem[child] > elem[child+1]) {
// 存在右孩子 且右孩子的值比左孩子的小
child++;
}
if(elem[child] < elem[parents]) {
// 如果孩子结点的值比根节点小 交换
swap(child,parents);
// parent中大的元素向下移动 可能会造成子树不满足堆的性质 继续进行向下调整
parents = child;
child = 2*parents + 1;
}else {
// 如果根节点就是最大值
break;
}
}
}向下调整的时间复杂度:
? ?最坏的情况就是从根节点一直比到叶子节点,比较的次数就是完全二叉树的高度,O(logn)
其他情况比较的次数都是常数次,对于时间复杂度来说,一般只考虑最坏情况
2.堆的创建
? 在向下调整的代码中我们已经实现了堆的创建
// 堆的创建
public void createHeap() {
// 从最后一棵子树的根节点开始
for (int parents = (usedSize-1-1)/2; parents >= 0; parents--) {
shiftDown(parents,usedSize);
}
}向下调整的时间复杂度是?O(logn),那"建堆"的时间复杂度是多少呢?请看下面的推导
?
注:
1.堆建立的时间复杂度需要考虑两方面,每层的结点数,以及每个结点向下调整的最坏情况2.堆的时间复杂度的推导需要使用到数列中常见的一种方法"错位相减"
3.堆的时间复杂度一定要回手写推导,面试中有可能会考到!!!
3.在堆中添加元素
? 要求:添加之后仍满足大根堆的形式
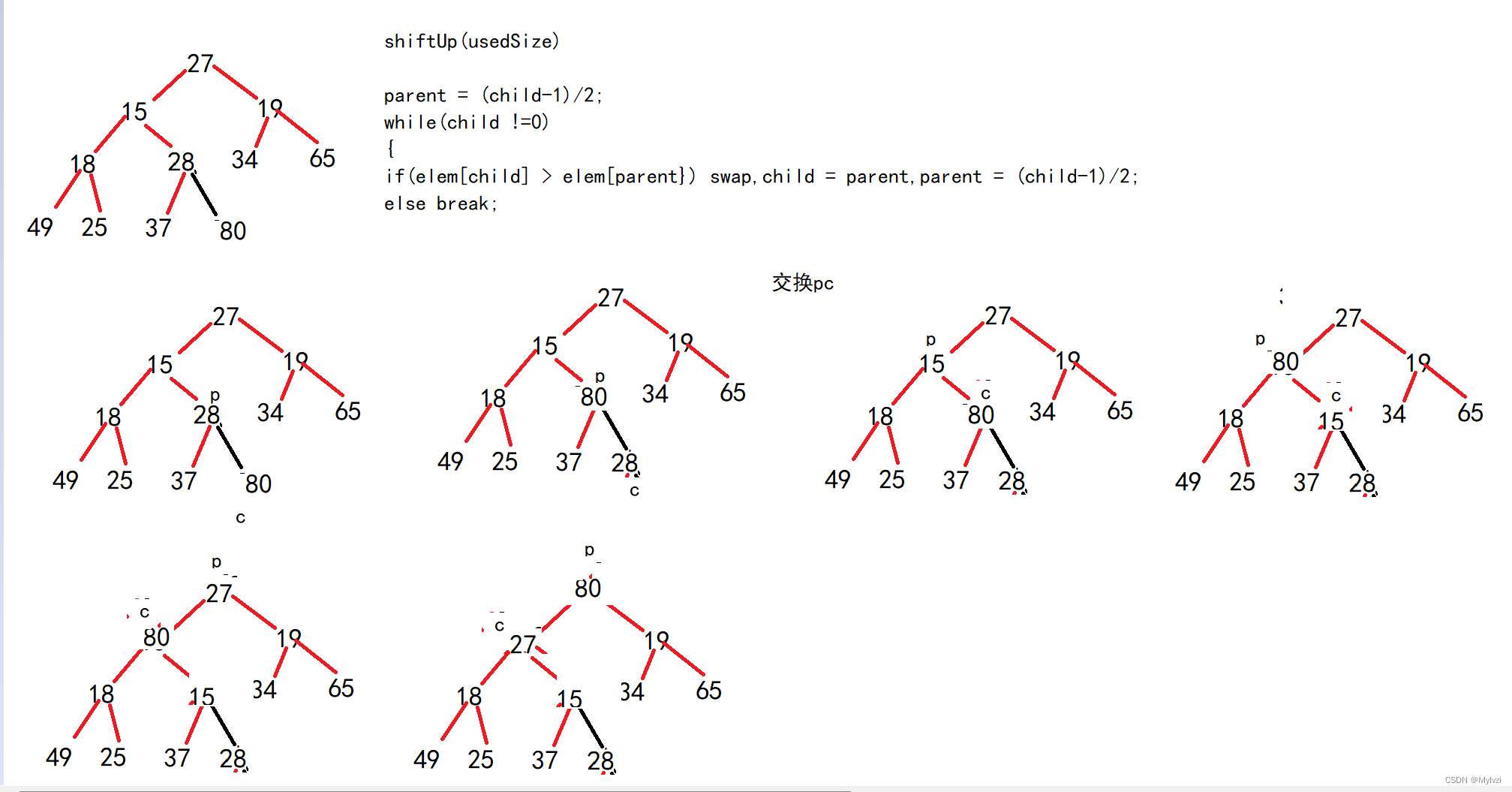
说明:
- 在堆中插入一个新的元素之后,需要仍保持堆的性质,此时需要进行向上调整,直到调整到合适的位置;
- 由于堆的存储结构是一个顺序表,所以当顺序表满时,需要进行扩容?;同时,堆的插入对应的就是顺序表的尾插
代码实现:
// 在堆内添加元素
/**
* 插入到最后一个位置(保证是一个完全二叉树,且方便后续操作)
* 向上调整
*/
public void offer(int val) {
if (isFull()) {
this.elem = Arrays.copyOf(this.elem,2*this.elem.length);
}
this.elem[usedSize] = val;
shiftUp(usedSize);
this.usedSize++;
}
private void shiftUp(int child) {
int parent = (child-1)/2;
// == 0此时就是根节点了 不需要再去向上调整
// 需要一直调整到根节点
while(child != 0) {
if(elem[child] > elem[parent]) {
swap(child,parent);
child = parent;
parent = (child-1)/2;
}else {
break;
}
}
}
private boolean isFull() {
return this.usedSize == this.elem.length;
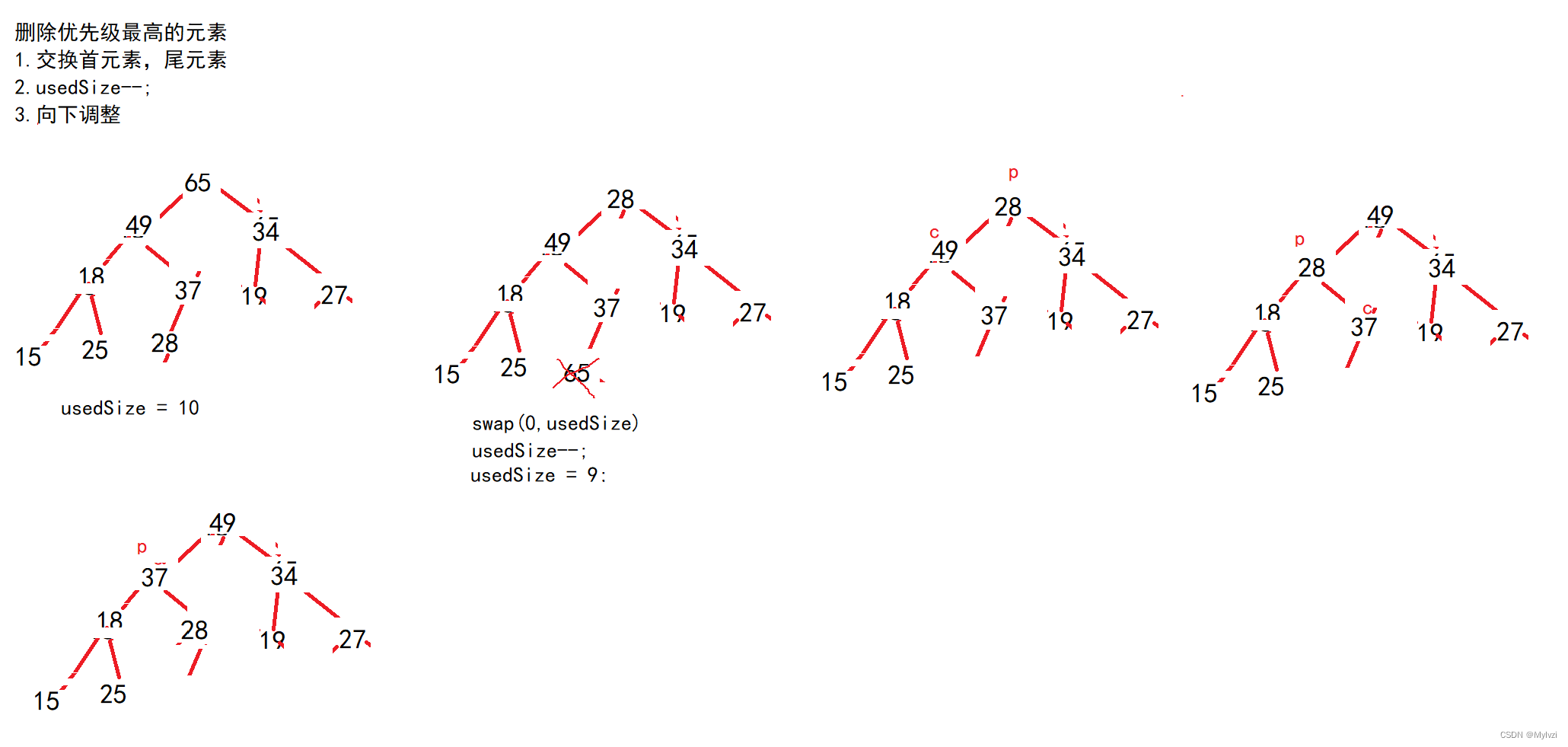
}4.删除优先级最高的元素(数组的首元素)
? 堆的删除对应队列的"出队"操作,只不过堆的删除出的是优先级最高的元素
? 对于堆来说,优先级最高的元素位于堆顶,也就是顺序表的首元素,那如何进行堆的删除操作呢?
? 最直观的想法就是先保存堆顶元素,然后挪动堆顶元素之后的所有元素,使其都向前挪动一个位置,再对挪动之后的结果重新进行向下调整。这种方法实际上是可行的,但是时间复杂度过高,效率较低,这种方法的时间复杂度是挪动数据的时间复杂度O(n)与向下调整的时间复杂度O(logN)之和
? 当然还有另一种效率更高的实现方法,先交换堆顶和堆尾的元素,再进行向下调整,此方法的时间复杂度是交换的时间复杂度O(1)与向下调整的时间复杂度O(logN),效率明显比大量挪动数据更高
代码实现:
// 删除 一定是删除优先级最高的元素 最后返回优先级最高的那个元素
public int poll() {
// 优先级最高的元素就是顺序表elem 的首元素
int tmp = elem[0];
swap(0,usedSize-1);
this.usedSize--;
// 只需对堆顶元素进行向下调整
shiftDown(0,usedSize);
return tmp;
}注:
? 交换堆顶和堆尾元素这一操作还有另一考量,因为堆尾元素一定是优先级最低的元素,出队一定是最后一个进行出队,交换之后,堆顶是优先级最低的元素,就保证了其余元素都是优先级比堆顶元素更高,此时只需对堆顶元素进行向下调整即可,而不是从最后一棵子树的根节点开始进行调整
总结:删除堆中元素的三步骤
- 交换堆顶和堆中最后一个元素
- 删除最后一个元素
- 将堆顶元素进行向下调整
三.常用接口介绍
1.PriorityQueue的特性
? Java的集合框架中提供了PriorityQueue和PriorityBlockingQueue两种类型的优先级队列,PriorityQueue是线程不安全的,PriorityBlockingQueue是线程安全的,此处主要介绍PriorityQueue
使用PriorityQueue的注意事项
- 需要导包,即:import java.util.PriorityQueue;
- PriorityQueue中存放的数据必须能够进行大小的比较,不能够插入无法比较的对象,否则会报错
PriorityQueue<Integer> priorityQueue1 = new PriorityQueue<>(); priorityQueue1.offer(1); priorityQueue1.offer(2); PriorityQueue<Student> priorityQueue2 = new PriorityQueue<>(); priorityQueue2.offer(new Student()); priorityQueue2.offer(new Student());// 报错
3.不能插入null,否则会报空指针异常
4.插入(向上调整)和删除的操作的时间复杂度都是O(logN)
5.?PriorityQueue默认是小根堆,也就是根节点的值比子节点的值小
?
PriorityQueue<Integer> priorityQueue1 = new PriorityQueue<>();
priorityQueue1.offer(1);
priorityQueue1.offer(2);
priorityQueue1.offer(3);
priorityQueue1.offer(4);
priorityQueue1.offer(5);
System.out.println(priorityQueue1.poll());// 输出12.?PriorityQueue常用接口介绍
1.构造方法
1.1不含参的构造方法
// 不含参的构造方法
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
// 默认容量是11
private static final int DEFAULT_INITIAL_CAPACITY = 11;1.2?指定容量的构造方法
// 指定容量的构造方法
public PriorityQueue(int initialCapacity) {
this(initialCapacity, null);
}1.3指定容量 ?并接受比较器的构造方法(最核心的一个构造方法)
// 指定容量 并接受比较器的构造方法
public PriorityQueue(int initialCapacity,
Comparator<? super E> comparator) {
// Note: This restriction of at least one is not actually needed,
// but continues for 1.5 compatibility
// 如果初始容量<1 就抛出异常 但实际上源码中也说了 <1这个条件并不是必需的 只不过是为了和1.5保持一致设置的条件
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}?1.4利用其他集合创建一个优先级队列
只要实现了Collection的集合都能作为参数参与创建一个优先级队列
PriorityQueue(Collection<? extends E>?c)??用一个集合来创建优先级队列
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(12);
list.add(13);
PriorityQueue<Integer> priorityQueue =
new PriorityQueue<>(list);
System.out.println(priorityQueue.toString());// 输出1 12 132.PriorityQueue的扩容机制
PriorityQueue的存储结构是顺序表,在不断添加数据的时候涉及到扩容问题,下面来研究一下PriorityQueue中是如何进行扩容的
先来看offer对应的源码
public boolean offer(E e) {
// 为空 直接抛出异常 不能插入空指针
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
// 进行扩容
if (i >= queue.length)
// grow方法内部是扩容的机制
grow(i + 1);
size = i + 1;
if (i == 0)
queue[0] = e;
else // 向上调整
siftUp(i, e);
return true;
}接下来看grow方法的实现?
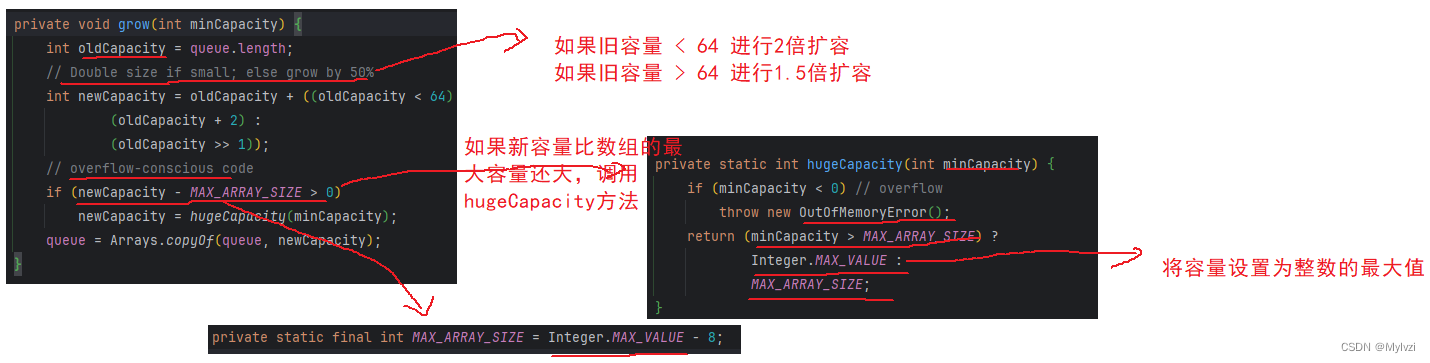
3.如何实现大根堆
PriorityQueue默认是小根堆,想要实现大根堆则需要重新构建比较逻辑,使用Comparator接口,下面以整数的比较为例实现大根堆
1.方法一:直接构造一个比较器
// 构造比较器 实现大根堆
class IntCmp implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
}
PriorityQueue<Integer> priorityQueue =
new PriorityQueue<>(new IntCmp());
priorityQueue.offer(1);
priorityQueue.offer(2);
priorityQueue.offer(33);
priorityQueue.offer(44);
priorityQueue.offer(55);
System.out.println(priorityQueue.poll());// 输出552.方法二:使用匿名内部类
// 使用匿名内部类
PriorityQueue<Integer> priorityQueue =
new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});
priorityQueue.offer(1);
priorityQueue.offer(2);
priorityQueue.offer(33);
priorityQueue.offer(44);
priorityQueue.offer(55);
System.out.println(priorityQueue.poll());// 输出553.方法三:使用lambda表达式(推荐)?
// 使用lambda表达式
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(
(o1,o2) ->{return o2.compareTo(o1);}
);
priorityQueue.offer(1);
priorityQueue.offer(2);
priorityQueue.offer(33);
priorityQueue.offer(44);
priorityQueue.offer(55);
System.out.println(priorityQueue.poll());// 输出55四.重点:top-k问题的三种解决方法
https://leetcode.cn/problems/smallest-k-lcci/description/

1.最简单的思路:对数组进行排序
// 解法1
public int[] smallestK1(int[] arr, int k) {
int[] ret = new int[k];
if(arr == null || k <= 0) return ret;
Arrays.sort(arr);
// 排序之后 arr从小到大排列完毕
for (int i = 0; i < k; i++) {
ret[i] = arr[i];
}
return ret;
}?
2.直接使用堆(优先级队列)的特性? 创建小根堆? poll k次即可
// 解法2
public int[] smallestK2(int[] arr, int k) {
int[] ret = new int[k];
if(arr == null || k <= 0) return ret;
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
for (int i = 0; i < arr.length; i++) {
priorityQueue.offer(arr[i]);
}
for (int i = 0; i < k; i++) {
ret[i] = priorityQueue.poll();
}
return ret;
}3.建立一个k个结点的大根堆? 再与数组剩余元素进行比较(重点掌握)
步骤:
- 先将前k个元素创建为大根堆(k 是因为我最后要返回k个元素)
- 将数组中剩余的元素依次去和堆顶元素进行比较,如果小于堆顶元素,插入堆中
- 返回容量为k的大根堆

// 解法3 效率最高的一种方法 创建一个具有k个结点的大根堆
// 注意 优先级队列默认是小根堆 要实现大根堆 需要先创建一个实现了Comparator接口的对象
class IntCmp implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
}
public int[] smallestK(int[] arr, int k) {
int[] ret = new int[k];
if(arr == null || k <= 0) return ret;
// 创建一个具有k个结点的大根堆
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(new IntCmp());
for (int i = 0; i < k; i++) {
// 将前k个元素做成大根堆
priorityQueue.offer(arr[i]);
}
for (int i = k; i < arr.length; i++) {
// 去和栈顶元素比较
if (arr[i] < priorityQueue.peek()) {
// 证明栈顶元素不是前k个最小的元素 要删除
priorityQueue.poll();
priorityQueue.offer(arr[i]);
}
}
for (int i = 0; i < k; i++) {
ret[i] = priorityQueue.poll();
}
return ret;
}?时间复杂度分析:

前两种方法对于数据量特别大的情况十分不友好!占用的内存太大?
变式:
求数组中第k大/小元素
// 求数组中第k大/小元素
// 前k个元素存储到小根堆中 堆里存放最大的k个元素 以小根堆的形式存储 则堆头一定是第k大的元素
public int maxKestK(int[] arr, int k) {
if(arr == null || k <= 0) {
throw new ArrayEmptyException("不含有元素或k不合法");
}
// 创建一个具有k个结点的大根堆
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
for (int i = 0; i < k; i++) {
// 将前k个元素做成小根堆
priorityQueue.offer(arr[i]);
}
for (int i = k; i < arr.length; i++) {
if (arr[i] > priorityQueue.peek()) {
priorityQueue.poll();
priorityQueue.offer(arr[i]);
}
}
return priorityQueue.poll();
}五.堆排
? 堆排序即利用堆的思想进行排序,堆排序的过程可以分为两步
- 确定排序方式:升序--建立大根堆? 降序--建立小根堆
- 利用堆删除的思想(向下调整进行堆排)
图解:
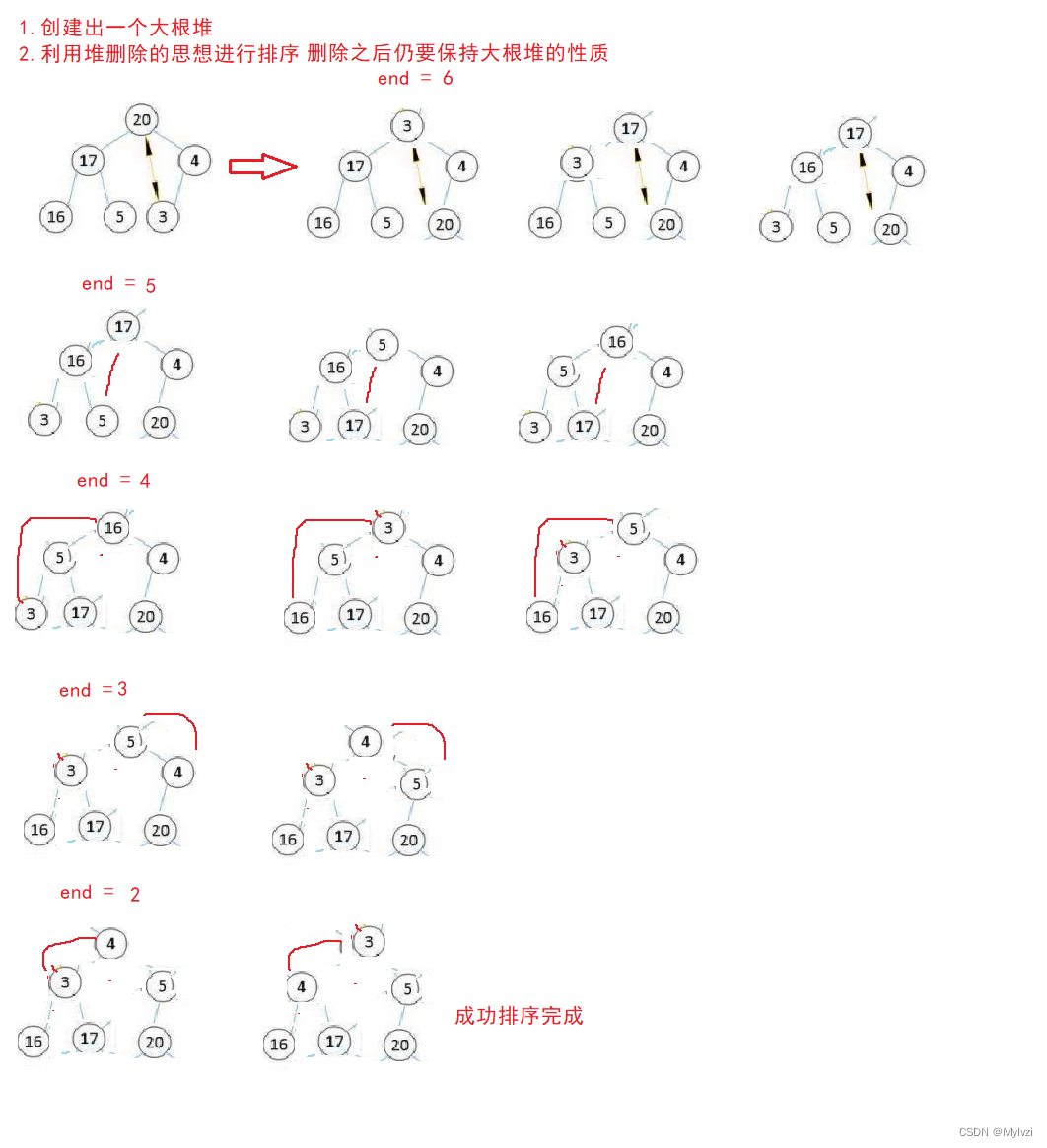
代码实现
// 堆排序
// 升序 从小到大 创建大根堆
// 降序 从大到小 创建小根堆
/**
* 升序 调整为大根堆 堆首元素一定是最大的
* 交换堆首和堆尾元素 向下调整(不包含被调下去的最大元素) 使第二大的元素位于堆顶
* 重复上述操作 每次都是堆首元素和堆尾元素进行交换
*/
public void headSort() {
int end = usedSize-1;
while(end > 0) {
swap(0,end);
shiftDown(0,end);
end--;
}
}
private void shiftDown(int parent, int usedSize) {
int child = 2 * parent+1;// 得到左孩子的下标
while (child < usedSize) {
// 首先要保证child是左右孩子最大元素的下标
if(child + 1 < usedSize && elem[child] < elem[child+1]) {
// 有右孩子 且右孩子的值比左孩子大
child++;
}
// 此时child就是值最大孩子的下标
if(elem[child] > elem[parent]) {
swap(child,parent);
parent = child;
child = 2 * parent+1;
}else {
break;
}
}
}总结:
堆排时要选择好排序的顺序,如果是升序排序就创建大根堆,如果是降序排序就是用小根堆
以升序排序为例,创建一个大根堆存储数据,再不断交换堆顶和堆尾元素(此时一定是最大元素放到堆尾,最小元素放到堆顶),再进行向下调整,向下调整的数据范围并不报错刚刚被挪动到堆尾的元素,使整个堆仍然保持大根堆的性质,这样最大的元素就被移动到最后,依次操作,每次都可以把当前数据范围内的最大元素移动到最后,最后创建出的堆中存储的数据就是升序排序的
这种"逆向思维"在堆中很常见,想让堆顶是最小的元素,就先创建大根堆,再不断地挪动数据,向下调整
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!