VGGNet
目录
一、VGGNet介绍
???????VGGNet(Visual Geometry Group Network)是一种深度卷积神经网络,由牛津大学计算机视觉组(Visual Geometry Group)的研究团队于2014年提出。VGGNet在当时的ImageNet图像识别挑战中取得了很好的表现,并成为了深度学习和计算机视觉领域中的经典模型之一。
1、VGG块
???????VGGNet的设计思想相对简单,其主要特点是将卷积层组合成块(卷积块),再把卷积块进行拼接,就像拼乐高一样,使模型更加规则。网络中的卷积层使用相同数量的卷积核,并采用相同的填充方式和步长。通过多次堆叠这种相同结构的卷积层,VGGNet可以构建不同深度的网络。

2、VGG架构
???????多个VGG块后接全连接层,不同次数的重复块得到不同的架构VGG-16,VGG-19。
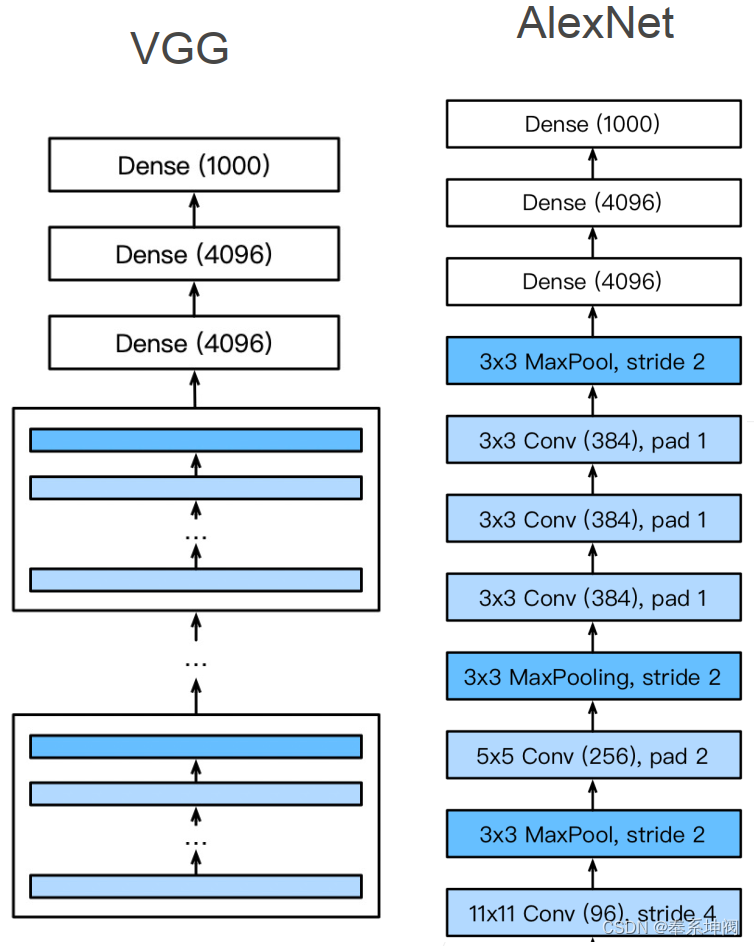
3、LeNet, AlexNet和VGGNet对比
| LeNet | AlexNet | VGGNet | |
| 改进 | 2卷积+池化层 2全连接层 | 更大更深的LeNet ReLU, Dropout, 数据增强 | 更大更深的AlexNet 重复的VGG块 |
4、总结
- VGG使用可重复使用的卷积块来构建深度卷积神经网络
- 不同的卷积块个数和超参数可以得到不同复杂度的变种
二、代码实现
1、定义VGG卷积块
???????一个VGG块由一系列卷积层组成,后面再加上用于空间下采样的最大池化层。在下面的代码中,我们定义了一个名为`vgg_block`的函数来实现一个VGG块。该函数有三个参数,分别对应于卷积层的数量`num_convs`、输入通道的数量`in_channels`和输出通道的数量`out_channels`。
import torch
from torch import nn
from d2l import torch as d2l
def vgg_block(num_convs, in_channels, out_channels): # 这里是一个卷积块,可以自定义卷积块内卷积层的数量
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)2、VGG网络
???????与AlexNet、LeNet一样,VGG网络可以分为两部分:第一部分主要由卷积层和池化层组成,第二部分由全连接层组成。如下图所示。

???????VGG神经网络连接的几个VGG块(在`vgg_block`函数中定义)。其中有超参数变量`conv_arch`。该变量指定了每个VGG块里卷积层个数和输出通道数。全连接模块则与AlexNet中的相同。
???????原始VGG网络有5个卷积块,其中前两个块各有一个卷积层,后三个块各包含两个卷积层。第一个模块有64个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。由于该网络使用8个卷积层和3个全连接层,因此它通常被称为VGG-11。
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))???????下面的代码实现了VGG-11。可以通过在`conv_arch`上执行for循环来简单实现。
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
net = vgg(conv_arch)???????接下来,我们将构建一个高度和宽度为224的单通道数据样本,以观察每个层输出的形状。
X = torch.randn(size=(1, 1, 224, 224))
for blk in net:
X = blk(X)
print(blk.__class__.__name__,'output shape:\t',X.shape)Sequential output shape: torch.Size([1, 64, 112, 112])
Sequential output shape: torch.Size([1, 128, 56, 56])
Sequential output shape: torch.Size([1, 256, 28, 28])
Sequential output shape: torch.Size([1, 512, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
Flatten output shape: torch.Size([1, 25088])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])3、训练模型
???????由于VGG-11比AlexNet计算量更大,因此我们构建了一个通道数较少的网络,足够用于训练Fashion-MNIST数据集。
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch] # 将输出通道数缩小为之前的1/4
print(small_conv_arch)
net = vgg(small_conv_arch)[(1, 16), (1, 32), (2, 64), (2, 128), (2, 128)]除了使用略高的学习率外,模型训练过程与AlexNet类似。
lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())loss 0.178, train acc 0.935, test acc 0.920
2463.7 examples/sec on cuda:0
4、总结
- VGG-11使用可复用的卷积块构造网络。不同的VGG模型可通过每个块中卷积层数量和输出通道数量的差异来定义。
- 块的使用导致网络定义的非常简洁。使用块可以有效地设计复杂的网络。
- 在VGG论文中,Simonyan和Ziserman尝试了各种架构。特别是他们发现深层且窄的卷积(即卷积核为
)比较浅层且宽的卷积更有效。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!